Fitted-Model-Based Annotations
‘ggpmisc’ 1.0.0
Pedro J. Aphalo
2026-07-05
Source:vignettes/user-guide.Rmd
user-guide.RmdPurpose
Package ‘ggpmisc’ makes it easier to add to plots created using ‘ggplot2’ annotations based on fitted models and other statistics. It does this by wrapping existing model fit and other functions. The same annotations can be produced by calling the model fit functions, extracting the desired estimates and adding them to plots. There are two advantages in wrapping these functions in an extension to package ‘ggplot2’: 1) we ensure the coupling of graphical elements and the annotations by building all elements of the plot using the same data and a consistent grammar and 2) we make it easier to annotate plots to the casual users of R familiar with the grammar of graphics.
To avoid confusion it is good to make clear what may seem obvious to some: if no plot is needed, then there is no reason to use this package. The values shown as annotations are not computed within ‘ggpmisc’ but instead by the usual model-fit and statistical functions from R and R packages. The same is true for model predictions, residuals, etc., that some of the functions in ‘ggpmisc’ display as lines, segments, or other graphical elements.
It is also important to remember that in most cases data analysis proper should take place before annotated plots for publication are produced. Even though data analysis can benefit from combined numerical and graphical representation of the results, the use I envision for ‘ggpmisc’ is mainly for the production of plots for publication or communication.
Attaching package ‘ggpmisc’ also attaches package ‘ggpp’ as this package was created as a spin-off from ‘ggpmisc’. ‘ggpp’ provides several of the geometries used by default in the statistics described below. Package ‘ggpp’ can be loaded and attached on its own, and has separate on-line documentation.
The on-line
documentation of ‘ggpmisc’ includes articles/vignettes not installed
with the package. These articles contain use examples covering
annotations based on additional model fitting functions, including
user-defined ones. These articles also describe the use of
ggpmisc together with some other R packages including
‘ggrepel’, ‘gganimate’, ‘ggtext’, ‘marquee’ and ‘xdvir’. With the last
three packages, automatically generated Markdown and \LaTeX formatted equations and other labels
can be added to plots.
Introduction to computed annotations
The design of data visualizations depends on the target audience, expected “reading” time, being communicated and the type of statistical analysis relevant to a given data set (e.g., whether or y to a continuous variable, and x to a factor, or vice versa).
When continuous variables are mapped to both of x and y aesthetics, fitted model predictions are often displayed as curves and bands in plots. To facilitate interpretation or further use, fitted-model equations, tests of significance and various indicators of goodness of fit are diplayed as plot annotations. Occasionally an ANOVA table or a summary table as a plot inset can help interpretation. Other annotations computed from data are parametric and non-parametric correlations and their significance and other summaries. Data labels indicate the location of local or global maxima and minima and other features of the data.
When one of variables mapped to x or y aesthetics
is a factor and the other a continuous variable, an ANOVA table as a
plot inset can be useful. However, most (too?) frequently the outcomes
of pairwise contrasts are indicated using letters or connecting labels.
Several additional statistics for simple plot annotations computed from
data but not dependent of fitting of statistical models are
documented in the vignettes and help pages of package ‘ggpp’ even if
these statistics are imported and re-exported by ‘ggpmisc’.
‘ggpmisc’ not only implements a good assortment of annotations, it implements them using an open-ended approach that makes it possible to work with many different model-fitting methods. ‘ggpmisc’ expands the range of plots and data visualisation features available within the grammar of graphics. While some R packages like ‘ggpubr’ easy construction of everyday plots, ‘ggpmisc’ aims to make it possible the construction of data visualizations that communicate effectively the outcomes from a broader range of statistical methods.
Computed and model-fit based annotations are implemented in ‘ggpmisc’ as new statistics that do computations on the plot data and pass the results to existing or new geometries. These new statistics are only a convenience in the sense that similar plots can be achieved by fitting models and operating on the fitted model objects to extract estimates and outcomes of tests passing them as data directly to geoms in a plot. This approach requires additional coding by users to assemble character strings to be parsed into R expressions (or encoded using markdown or \LaTeX or \TeX). Fitting the models before constructing the plot object can weaken reproducibility as the values in the annotations are not computed at the time the plot is rendered and not guaranteed to use the data being plotted (When using ‘ggpmisc’ statistics the user remains responsible for the consistency of methods and model formulas used in different plot layers!).
The statistics defined in ‘ggpmisc’ even if usable with geometries from package ‘ggplot2’, in most cases have as default geometries defined in package ‘ggpp’. These new geometries are better suited for plot annotations than those from ‘ggplot2’, which are designed for data labels.
In user interfaces there is always a compromise between simplicity and flexibility in which the choice of default arguments plays a key role in finding a balance. I have aimed to make everyday use simple without limiting the flexibility inherent to the Grammar of Graphics. However, the assumption is that users desire/need the flexibility inherent in the layered approach of the Grammar of Graphics, and that the layer functions provided will be combined with those from ‘ggplot2’, ‘ggpp’ and other packages extending the Grammar of Graphics as implemented in ‘ggplot2’.
Statistics
Currently, the core statistics made available by package ‘ggpmisc’
help with reporting parameter- and other estimates from fitted models,
both as equations and numbers in annotations and by plotting. Similarly
to ggplot2::stat_smooth() they call model-fit-functions to
fit a model-formula to the plot-layer data and, as all ggplot
statistics, return new data as a data frame that is in turn
passed to a geometry. The statistics are stat_poly_line(),
stat_poly_eq(), stat_ma_line(),
stat_ma_eq(), stat_quant_line(),
stat_quant_band(), stat_quant_eq(),
stat_fit_residuals(), stat_fit_deviations(),
stat_fit_glance(), stat_fit_augment(),
stat_fit_tidy() and stat_fit_tb(). Most of
these statistics support orientation flipping, both using parameter
orientation similarly to package ‘ggplot2’ in recent
versions or through a model formula with x as
response variable and y as explanatory variable. In
addition, stat_correlation() helps with the reporting of
Pearson, Kendall and Spearman correlations. Finally,
stat_distrmix_line() and stat_distrmix_eq()
support the fitting of mixtures of probability density
distributions.
These statistics support grouping and faceting. In the case of those
that return character strings to be mapped to the label
aesthetic they also return suitable x and y,
or npcx and npcy values as well as
hjust and vjust values. These default values
ensure that the annotations do not spill ouside the edges of the
plotting area. The automatic computation of these positions can be
adjusted through arguments passed to these statistics and also
overridden by user-supplied manual positions.
Not all possible model formulas can be decoded to produce valid fitted model equations. In most cases, for incompatible model formulas, no equation label is automatically generated, and a warning triggered. Other labels such as R^2 are nearly always generated. When not automatically generated, a suitable fitted model equation can be assembled by user code within the aesthetic mapping using the numeric values that are also returned.
Initially, stat_poly_eq() and
stat_poly_line() supported only lm() as model
fit function, as time passed by support for additional specific model
fit functions was added. Since ‘ggpmisc’ (>= 0.5.0) user-defined
functions have been supported as long as the class of the model fit
object they return matches one corresponding to one of the supported
model fit functions. Since ‘ggpmisc’ (>= 0.6.2) support is expanded
to include arbitrary model fit functions for which the necessary fitted
model object query methods are available. In this last case a
warning is issued as the extraction of estimates can fail and
NA values returned for some or all labels. Most
importantly, the correctness of the extracted estimates needs to be
checked when the warning is issued as in these cases there is no
assurance of correctness.
Table 1 below summarizes the use of the model-fittings statistics and
the default geometries. The statistics stat_fit_glance()
and stat_fit_tidy() require in their use more effort as the
mapping to aesthetics and conversion of numeric values into character
strings must be coded in the layer function call, but on the other hand
they support all model fit objects catered by package ‘broom’ itself or
any of the packages extending ‘broom’ such as ‘broom.mixed’ (see next
section).
| Statistic | Returned values (default geometry) |
Methods |
|---|---|---|
| Model equation | parameter estimates | |
stat_poly_eq() |
equation, R2, P, etc.
(text_npc) |
lm, rlm, lts, gls, ma, sma, etc. (1, 2, 7) |
stat_ma_eq() |
equation, R2, P, etc.
(text_npc) |
lmodel2 (6, 7) |
stat_quant_eq() |
equation, P, etc. (text_npc) |
rq, rqss (1, 3, 4, 7) |
stat_distrmix_eq() |
equation(s) (text_npc) |
normalmixEM (2, 7) |
stat_correlation() |
correlation, P-value, CI
(text_npc) |
Pearson (t), Kendall (z), Spearman (S) |
stat_fit_glance() |
equation, R2, P, etc.
(text_npc) |
those supported by ‘broom’ |
| Model line | predicted and fitted values | |
stat_poly_line() |
line + conf. (smooth) |
lm, rlm, lts, gls, ma, sma, etc. (1, 2, 7) |
stat_ma_line() |
line + slope conf. (smooth) |
lmodel2 (6, 7) |
stat_quant_line() |
line + conf. (smooth) |
rq, rqss (1, 3, 4, 7) |
stat_quant_band() |
line + band, 2 or 3 quantiles
(smooth) |
rq, rqss (1, 4, 5, 7) |
stat_distrmix_line() |
lines(s) (line) |
normalmixEM (2, 7) |
stat_fit_augment() |
predicted and other values (smooth) |
those supported by ‘broom’ |
stat_fit_fitted() |
fitted values (point) |
lm, rlm, lts, gls, rq, rqss, etc. (1, 2, 4, 7, 9) |
stat_fit_deviations() |
deviations from observations
(segment) |
lm, rlm, lts, gls, rq, rqss, etc. (1, 2, 4, 7, 9) |
| Model table | parameter estimates and significance | |
stat_fit_tb() |
ANOVA and summary tables (table_npc) |
those supported by ‘broom’ |
stat_fit_tidy() |
fit results, e.g., for equation
(text_npc) |
those supported by ‘broom’ |
| Contrasts | Tukey, Dunnet and arbitrary pairwise | |
stat_multcomp() |
Multiple comparisons (label_pairwise or
text) |
those supported by glht (1, 2, 7) |
| Residuals | model fit residuals | |
stat_fit_residuals() |
residuals (point) |
lm, rlm, lte, gls, rq, rqss, etc. (1, 2, 4, 7, 8) |
Model equations and other annotations
Statistics stat_poly_eq() , stat_ma_eq() ,
stat_quant_eq(), stat_distrmix_eq() and
stat_correlation() return by default ready formatted
character strings that can be mapped to the label aesthetic
individually or concatenated. The convenience function
use_label() makes this easier by accepting
abbreviated/common names for the component labels, and handling both the
concatenation and mapping to the label aesthetics. For full
flexibility in the assembly of concatenated labels paste()
or sprintf() functions can the used within a call to
ggplot2::aes(). By default the character strings are
formatted ready to be parsed as R expressions. Optionally they can be
formatted as R Markdown, \LaTeX or
plain text as shown in the table below.
These statistics as of ‘ggpmisc’ (>= 0.5.0) allow additional
flexibility in the model fit method functions: they can be
any function with a suitable interface, as long as they return a fitted
model object of the expected class, or that inherits from the expected
class. When possible, in stat_poly_eq(), the model formula
is retrieved from the model fit object, and this retrieved model formula
overrides, only in the returned value, the one supplied as argument by
the user. In practice, this means that method can be a
function that does model selection. This is specially useful with
grouped data and facets, making it possible for model formula to vary
from group to group or from panel to panel within a single ggplot
object.
The returned values for output.type different from
numeric are shown below in Table 2. The variable mapped by
default to the label aesthetics is indicated with an
asterisk. The returned values for x and y are
for the default computed location of the labels. The returned data frame
has one row per group of observations in each panel of the plot.
Function use_label() provides an easy way of selecting,
possibly combining and mapping the text labels for different parameters
from a model fit, supporting the use of both variable names
such as "eq.label" and "rr.label" and
abbreviations or symbols used in statistics such as "eq"
and "R2".
| Variable | Key | Mode | poly_eq |
ma_eq |
quant_eq |
correlation |
multcomp |
distrmix_eq |
|---|---|---|---|---|---|---|---|---|
| eq.label | eq | character | y | y | y* | n | n | y |
| rr.label | R2 | character | y* | y* | n | y(1) | n | n |
| rr.confint.label | R2.CI | character | y | n | n | n | n | n |
| adj.rr.label | adj.R2 | character | y | n | n | n | n | n |
| cor.label | cor | character | n | n | n | y(1) | n | n |
| rho.label | rho | character | n | n | y | y(1) | n | n |
| tau.label | tau | character | n | n | n | y(1) | n | n |
| r.label | R | character | n | n | n | y* | n | n |
| cor.confint.label | cor.CI | character | n | n | n | y(1) | n | n |
| rho.confint.label | rho.CI | character | n | n | y | y(1) | n | n |
| tau.confint.label | tau.CI | character | n | n | n | y(1) | n | n |
| r.confint.label | R.CI | character | n | n | n | y | n | n |
| f.value.label | F | character | y | n | n | n | n | n |
| t.value.label | t | character | n | n | n | y(1) | y | n |
| z.value.label | z | character | n | n | n | y(1) | n | n |
| S.value.label | S | character | n | n | n | y(1) | n | n |
| p.value.label | P | character | y | y | n | y | y | n |
| delta.label | delta | character | n | n | n | n | y (3) | n |
| letters.label | delta | character | n | n | n | n | y (3) | n |
| AIC.label | AIC | character | y | n | y | n | n | n |
| BIC.label | BIC | character | y | n | n | n | n | n |
| knots.label | character | y(4) | n | n | n | n | n | |
| n.label | n | character | y | y | y | y | y | y |
| grp.label | grp | character | y | y | y | y | y | n |
| method.label | method | character | y | y | y | y | n | y |
In some cases it is desirable to alter the formatting based on the
outcome from a model fit, i.e., based on the value of parameter
estimates. In other cases, some ready formatted labels can be in the
desired format, while other need to be manually formatted. To catter for
these situations, multiple parameter estimates and test outcomes are
also returned as raw numeric or raw character values. The values
returned for all output.type values, including
"numeric" are shown below in Table 3.
| Variable | Key | Mode | poly_eq |
ma_eq |
quant_eq |
correlation |
multcomp |
distrmix_eq |
|---|---|---|---|---|---|---|---|---|
| coefs | numeric | y | y | n | n | n | n | |
| r.squared | numeric | y | y | n | n | n | n | |
| adj.r.squared | numeric | y | n | n | n | n | n | |
| rho | numeric | n | n | y | y(1) | n | n | |
| tau | numeric | n | n | n | y(1) | n | n | |
| cor | numeric | n | n | n | y(1) | n | n | |
| f.value | numeric | y | y | n | y | y | n | |
| f.df1 | numeric | y | y | n | y | y | n | |
| f.df2 | numeric | y | y | n | y | y | n | |
| f.value | numeric | y | y | n | y | y | n | |
| t.value | numeric | n | n | n | n | n | y | |
| t.df | numeric | n | n | n | n | n | y | |
| z.value | numeric | n | n | n | y(1) | n | n | |
| S.value | numeric | n | n | n | y(1) | n | n | |
| p.value | numeric | y | y | n | y | n | n | |
| lambda | numeric | n | n | n | n | n | y | |
| mu | numeric | n | n | n | n | n | y | |
| sigma | numeric | n | n | n | n | n | y | |
| lambda.se | numeric | n | n | n | n | n | y | |
| mu.se | numeric | n | n | n | n | n | y | |
| sigma.se | numeric | n | n | n | n | n | y | |
| knots | numeric | y(4) | n | n | n | n | n | |
| knots.se | numeric | y(4) | n | n | n | n | n | |
| component | factor | n | n | n | n | n | y | |
| n | numeric | y | y | y | y | y | y | |
| rq.method | character | n | n | y | n | n | n | |
| method | character | y | y | y | y | n | y | |
| test | character | n | n | n | y | n | n | |
| quantile | numeric | n | n | y | n | n | n | |
| quantile.f | factor | n | n | y | n | n | n | |
| fm.method | character | y | y | y | y | y | y | |
| fm.class | character | y | y | y | y | y | n | |
| fm.formula.chr | character | y | y | y | y | y | n | |
| converged | logical | n | n | n | n | n | y | |
| .size | numeric | n | n | n | n | n | y | |
| mc.adjusted | character | n | n | n | n | y | n | |
| mc.contrast | character | n | n | n | n | y | n | |
| xmin/ymin | numeric | n | n | n | n | y (3) | n | |
| xmax/ymax | numeric | n | n | n | n | y (3) | n | |
| x(2) | numeric | y | y | y | y | y | y | |
| y(2) | numeric | y | y | y | y | y | y | |
| npcx(2) | numeric | y | y | y | y | n | y | |
| npcy(2) | numeric | y | y | y | y | n | y |
Even though the number of significant digits and some other
formatting can be adjusted by passing arguments when calling the
statistics function, in some cases it maybe necessary for the user to do
the conversion of numeric values into character strings. One case is
when the fitted model is not a polynomial, as in this case
eq.label needs to be assembled and formatted in user code
within a call to aes(). For these special cases, the
statistics can return additional values as numeric. The
values returned only for output.type equal to
numeric are shown below in Table 4.
| Variable | Mode | poly_eq |
ma_eq |
quant_eq |
correlation |
distrmix_eq |
|---|---|---|---|---|---|---|
| coef.ls | list | y | y | y | n | n |
| b_0.constant | numeric | y | y | y | n | n |
| b_0 | numeric | y | y | y | n | n |
| b_1 | numeric | y | y | y | n | n |
| b_2…b_n | numeric | y | y | y | n | n |
In the cases of the statistics based on the methods from package
‘broom’ and its extensions, the returned value depends on that of the
method specialization that is automatically dispatched based on the
class of the model fit object returned by the method
function (Table 5). The expectation is that these statistics will be
used only in cases when those described above cannot be used.
Implementation based on generic methods from package ‘broom’ and its
extensions provides support for very many different model fit
procedures, but at the same time requires that the user consults the
documentation of these broom methods and that the user builds the
character strings for labels in his own code. The simplest way of
discovering what variables are returned is to use
gginnards::geom_debug_group() to explore the returned data
frame. Examples are included in the help to some of the statistics and
in a later section of this User Guide.
| Variable | Mode | fit_tb |
fit_tidy |
fit_glance |
fit_augment |
|---|---|---|---|---|---|
| broom method | tidy() |
tidy() |
glance() |
augment() |
|
| x(1) | numeric | y | y | y | y |
| y(1) | numeric | y | y | y | y |
| npcx(1) | numeric | y | y | y | n |
| npcy(1) | numeric | y | y | y | n |
| fm.tb | data.frame | y | n | n | n |
| fm.tb.type | character | y | n | n | n |
| fm.method | character | y | y | y | y |
| fm.class | character | y | y | y | y |
| fm.formula.chr | character | y | y | y | y |
Statistics stat_poly_line(),
stat_ma_line(), stat_quant_line(),
stat_quant_band() and stat_distrmix_line()
return objects similar to those returned by
ggplot2:stat_smooth().
Fitted lines, confidence bands and residuals
Statistics stat_poly_line(),
stat_ma_line(), stat_quant_line() and
stat_quant_band() return numeric data suitable for plotting
lines or lines plus bands. They are similar to
ggplot2::stat_smooth() in their use. They return a basic
set of variables, x, y, ymin,
ymax, weights and
posterior.weights which can be expanded by passing
fm.values = TRUE. The expanded returned data
contains in addition n, r.squared,
adj.r.squared and p.value when available.
These numeric variables make it possible to conditionally hide or
highlight using aesthetics, fitted lines that fulfil conditions tested
on these variables. The number of rows per group and
panel in the plot, i.e., number of points used to plot the
smooth line, is that given by parameter n with default
n = 80. The user interface and default arguments are
consistent with those of statistics stat_poly_eq(),
stat_ma_eq() and stat_quant_eq() described
above.
Statistics stat_fit_residuals() and
stat_fit_deviations() can be used to plot the residuals of
model fits on their own and to highlight them in a plot of the fitted
model curve, respectively.
ANOVA and summary tables
Statistic stat_fit_tb() can be used to add ANOVA or
summary tables as plots insets. While the statistics described in the
two previous subsections are useful when fitting curves when both
x and y are mapped to continuous
numeric variables, stat_fit_tb() is also
suitable for cases when x or y is a
factor .
Which columns from the objects returned by R’s anova()
and summary() methods as well as which terms from the model
formula are included in the inset table can be selected by
the user. Column headers and term names can also be replaced by R
expressions. This statistics uses ggpp::geom_table() , a
geometry that supports table formatting styles.
Annotations based on package ‘broom’
Package ‘broom’ provides a translation layer between various
model fit functions and a consistent naming and organization for the
returned values. This made it possible to design statistics
stat_fit_glance() and stat_fit_augment() that
provide similar capabilities as those described above and that work with
any of the many model fit functions supported by package ‘broom’ and its
extensions. This means that the returned data are in columns with
generic names. Consequently, when using stat_fit_glance()
text labels need to be created in user code and then mapped to the
label aesthetic and when using
stat_fit_augment() with complex fitted models know the
details of the model fitting functions used.
Other data features
Statistics stat_peaks() and stat_valleys()
can be used to locate and annotate global and local maxima and minima in
the variable mapped to the y (or x )
aesthetic. Date time variables mapped to the x or
y aesthetics are supported.
Scales
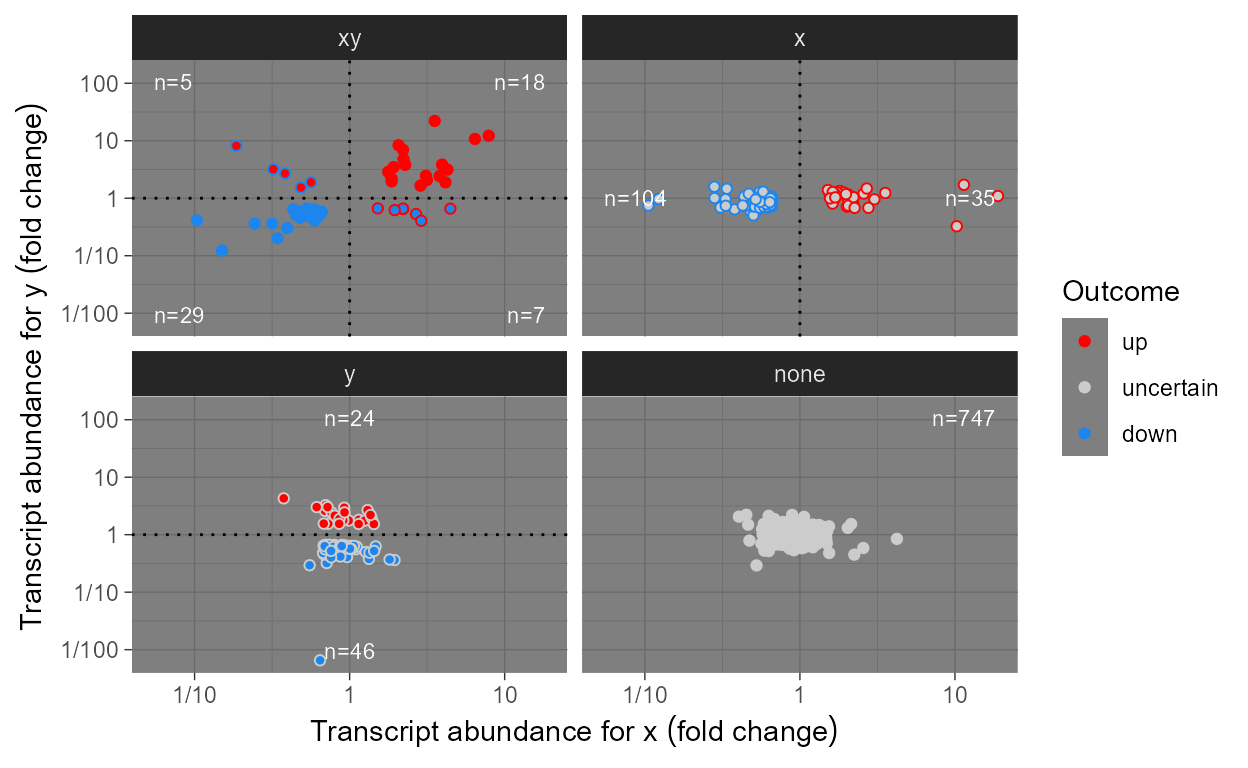
When plotting omics data we usually want to highlight
observations based on the outcome of tests of significance for each one
of 100’s or 1000’s genes or metabolites. We define some scales, as
wrappers on continuous x and y scales from
package ggplot2 that are suitable for 1) differences in
abundance expressed as fold changes, 2) P-value and 3) FDR.
Scales scale_x_logFC() and scale_y_logFC()
are suitable for plotting of log fold change data. Scales
scale_x_Pvalue(), scale_y_Pvalue(),
scale_x_FDR() and scale_y_FDR() are suitable
for plotting p-values and adjusted p-values or false
discovery rate (FDR). Default arguments are suitable for volcano and
quadrant plots as used for transcriptomics, metabolomics and similar
data.
Encoding of test outcomes into binary and ternary colour scales is also frequent when plotting omics data, so as a convenience we define wrappers on the colour, fill and shape scales from ‘ggplot2’ as well as defined functions suitable for converting binary and ternary outcomes and numeric P-values into factors.
Scales scale_colour_outcome(),
scale_fill_outcome() and scale_shape_outcome()
and functions outome2factor(),
threshold2factor(), xy_outcomes2factor() and
xy_thresholds2factor() used together make it easy to map
ternary numeric outputs and logical binary outcomes to colour, fill and
shape aesthetics. Default arguments are suitable for volcano, quadrant
and other plots as used for genomics, metabolomics and similar data.
R options
Some default arguments that should be in most cases set consistently
the different plots included in a document, can be set through R
options. These include the character used as decimal point, through the
option used by R itself, OutDec, the use of upper- or lower
case letters as symbol for probability and pearson correlation and
coefficient of determination: ggpmisc.small.p,
ggpmisc.small.r and the ordering of terms in the model fit
equation label (not the in the model formula argument)
ggpmisc.decreasing.poly.eq.
The labels can be generated using different types of markup: R
plotmath expressions, Markdown, \LaTeX,
and plain text. Character strings suitable for parsing are the default
unless the argument to parameter geom is
richtext or textbox, in which case Markdown
encoded character strings are returned. The default for
parse is TRUE only if suitable strings are
being returned.
Loading packages
The code below loads the packages used in the examples. Those imported always, and those suggested, when available.
library(ggpmisc)
library(tibble)
library(dplyr)
library(quantreg)
eval_nlme <- requireNamespace("nlme", quietly = TRUE)
if (eval_nlme) library(nlme)
eval_broom <- requireNamespace("broom", quietly = TRUE)
if (eval_broom) library(broom)
eval_broom_mixed <- requireNamespace("broom.mixed", quietly = TRUE)
if (eval_broom_mixed) library(broom.mixed)
eval_gginnards <- requireNamespace("gginnards", quietly = TRUE)
if (eval_gginnards) library(gginnards)As examples add text and labels onto the plotting area, the code below sets a theme with a white canvas as default.
Examples for Statistics
Several simple use examples are given in the help for each of the layer and other functions exported by package ‘ggpmisc’. Additional examples, mostly more advanced, together with brief explanations are provided here. Additional examples illustrating possible uses of ‘ggpmisc’ together with other packages are available at the ‘ggpmisc’ website as articles.
stat_correlation()
The statistic stat_correlation() computes one of
Pearson, Kendall or Spearman correlation coefficients and tests if they
differ from zero. This is done by calling
stats::cor.test(), with all of its formal parameters
supported. Depending on the argument passed to parameter
output.type the values returned very. The formatted strings
use different markup encodings depending on the geometry used: plotmath
expressions, as default; \LaTeX for
‘xdvir’; markdown for ‘ggtext’, markdown for ‘marquee’ and plain ASCII
text. The default behaviour is to generate labels as character strings
using R’s expression syntax, suitable to be parsed.
This ggplot statistic can also output labels using other mark-up
languages, including \LaTeX and
Markdown, or just numeric values. Nevertheless, all examples below use
expression syntax, which is the most commonly used.
Artificial data are used in the code examples in this and subsequent
sections, saved in a data.frame named my.data.
In these data, x has no error variation, and y
has errors normally distributed with mean = 0 and
sd = 1, y.grp is y with a
difference in mean between levels of group.
y.otlr is y with 5 outlier values
with larger error variation, with sd = 3 instead of
sd = 1. wght.otlr, to be used as prior
weights is set to 1/3 for the outliers and to
1 otherwise. y.poly are values from a third
degree polynomial with errors normally distributed with
mean = 0 and sd chosen to be suitable for the
examples. y.poly.grp is y.poly with different
slope and mean for each group.
set.seed(4321)
x <- (1:100) / 10
# linear
y.sd1 <- x + rnorm(length(x), mean = 0, sd = 1)
y.sd3 <- x + rnorm(length(x), sd = 3)
y.sdinc <- x + rnorm(length(x), mean = 0,
sd = seq(from = 1, to = 3, length.out = length(x)))
outliers <- sample(seq_along(x), size = 5)
# 3rd degree polynomial
y.poly <- (x + x^2 + x^3) + rnorm(length(x), mean = 0, sd = mean(x^3) / 4)
y.poly <- y.poly / max(y.poly)
my.data <- data.frame(x = x,
y = y.sd1,
y.sd3 = y.sd3,
y.sdinc = y.sdinc,
y.desc = - y.sd1,
y.grp = y.sd1 + c(0, 1),
y.otlr = ifelse(seq_along(x) %in% outliers,
y.sd3,
y.sd1),
wght.otlr =
ifelse(seq_along(x) %in% outliers, 1/3, 1),
y.poly = y.poly,
y.poly.grp = y.poly * c(1, 1.5) + c(0, 0.2),
wght.sqrt = sqrt(x),
group = c("A", "B"),
group.abcd = c("a", "b", "c", "d"),
block = c("a", "a", "b", "b"))
head(my.data)## x y y.sd3 y.sdinc y.desc y.grp y.otlr
## 1 0.1 -0.32675738 2.5139573 -0.1869614 0.32675738 -0.3267574 -0.32675738
## 2 0.2 -0.02361182 1.8290143 -0.4582363 0.02361182 0.9763882 -0.02361182
## 3 0.3 1.01760679 -2.2090599 0.1571174 -1.01760679 1.0176068 1.01760679
## 4 0.4 1.24144567 -0.3586354 -1.1381915 -1.24144567 2.2414457 1.24144567
## 5 0.5 0.37164273 4.7098440 -1.8533134 -0.37164273 0.3716427 4.70984401
## 6 0.6 2.20934721 1.3302780 2.6610857 -2.20934721 3.2093472 2.20934721
## wght.otlr y.poly y.poly.grp wght.sqrt group group.abcd block
## 1 1.0000000 0.078381346 0.07838135 0.3162278 A a a
## 2 1.0000000 -0.006522069 0.19021690 0.4472136 B b a
## 3 1.0000000 0.066537191 0.06653719 0.5477226 A c b
## 4 1.0000000 0.022086892 0.23313034 0.6324555 B d b
## 5 0.3333333 0.062825923 0.06282592 0.7071068 A a a
## 6 1.0000000 -0.016811847 0.17478223 0.7745967 B b aThe first example, using stat_correlation() defaults,
creates a plot with an annotation showing Pearson’s correlation
coefficient.
ggplot(my.data, aes(x, y)) +
geom_point() +
stat_correlation()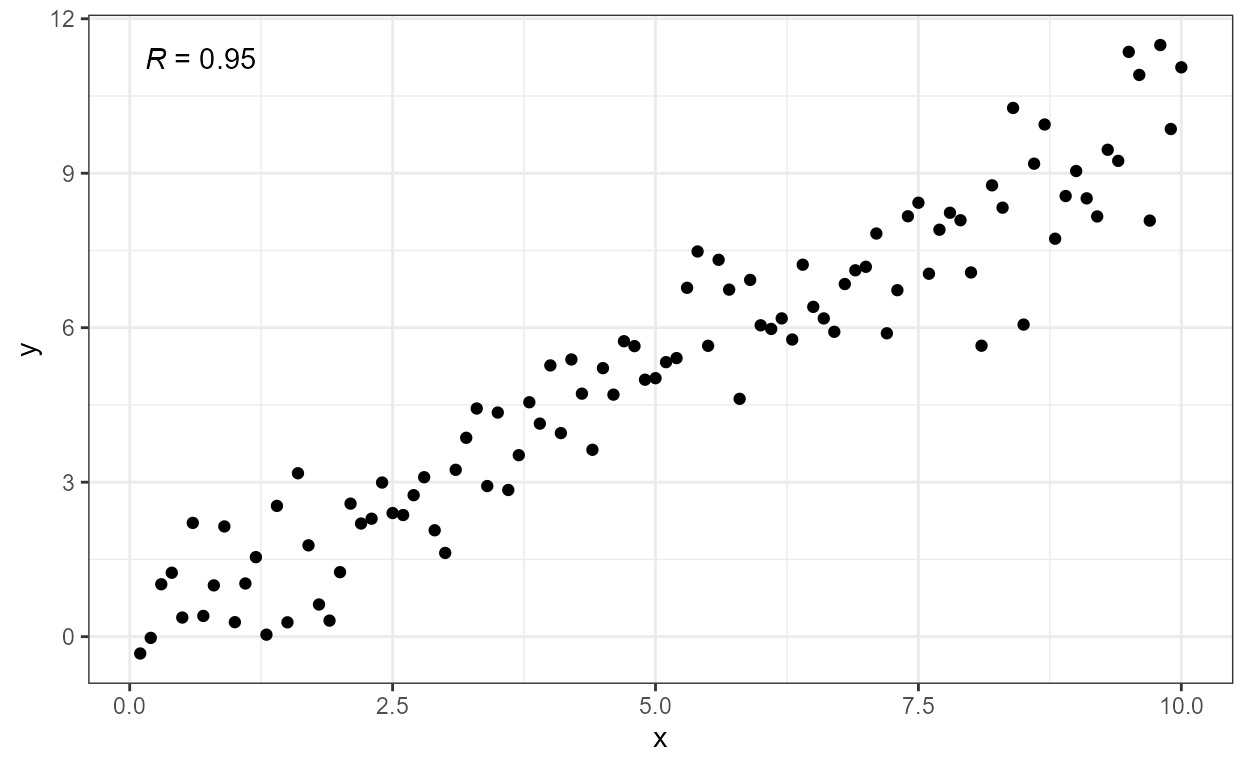
The defaults support grouping by mapping of a factor to an aesthetic,
in this example, colour.
ggplot(my.data, aes(x, y.grp, colour = group)) +
geom_point() +
stat_correlation()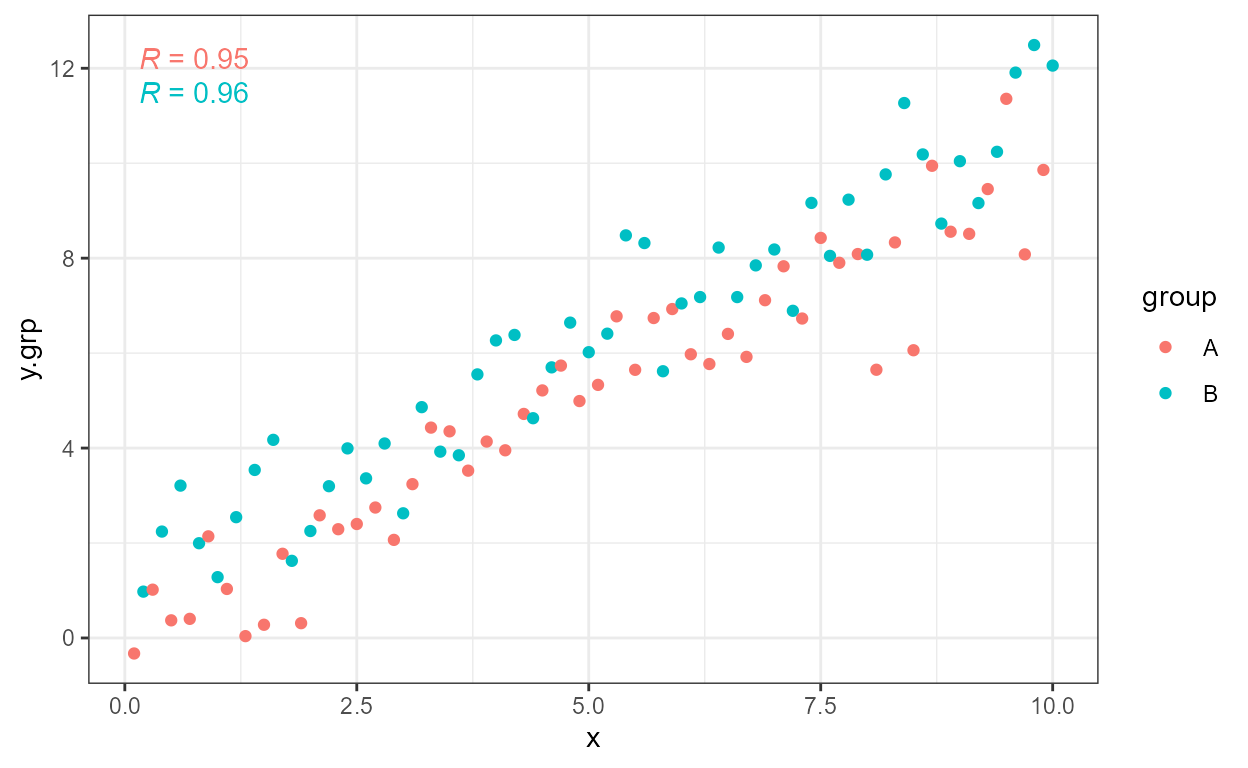
Spearman’s (\rho, rho) and Kendall’s
(\tau, tau) approaches to rank
correlation are also supported, and can be selected with an argument
passed to parameter method.
ggplot(my.data, aes(x, y.grp, color = group)) +
geom_point() +
stat_correlation(method = "spearman")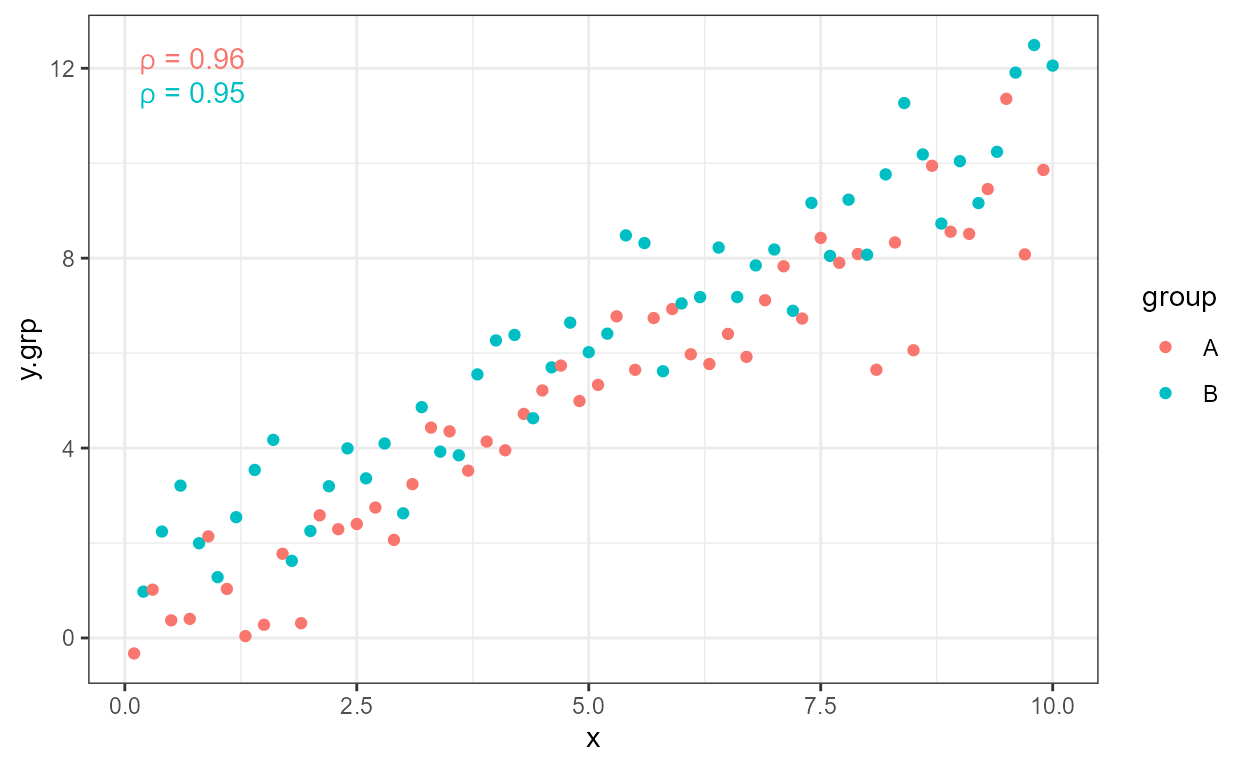
Statistic stat_correlation() returns multiple formatted
character strings that can be mapped to the label
aesthetic. The returned character strings can be combined within a call
to aes() using after_stat() together with
functions such as paste() and mapped to the
label aesthetic. However, using one of the wrapper
functions use_label() or f_use_label() is
simpler. The short “nicknames” with which the strings can be retrieved
with these two functions are displayed in a message to the R console in
interactive R sessions. For example:
'stat_correlation' labels (1 rows): P, n, grp, r, r.confint, method, cor, R2, t.When data are grouped, one message is issued for each set of computed
values or for each model fit. The names of the returned variables, with
some exceptions, have the suffix .label, e.g.,
n corresponds to n.label. These longer names
are also recognised by these two functions, and must always be used when
retrieving them with after_stat(). In the message,
1 rows indicates that the returned data frame has one row
per group.
ggplot(my.data, aes(x, y.grp, color = group)) +
geom_point() +
stat_correlation(mapping = use_label("r", "t", "P", "n"))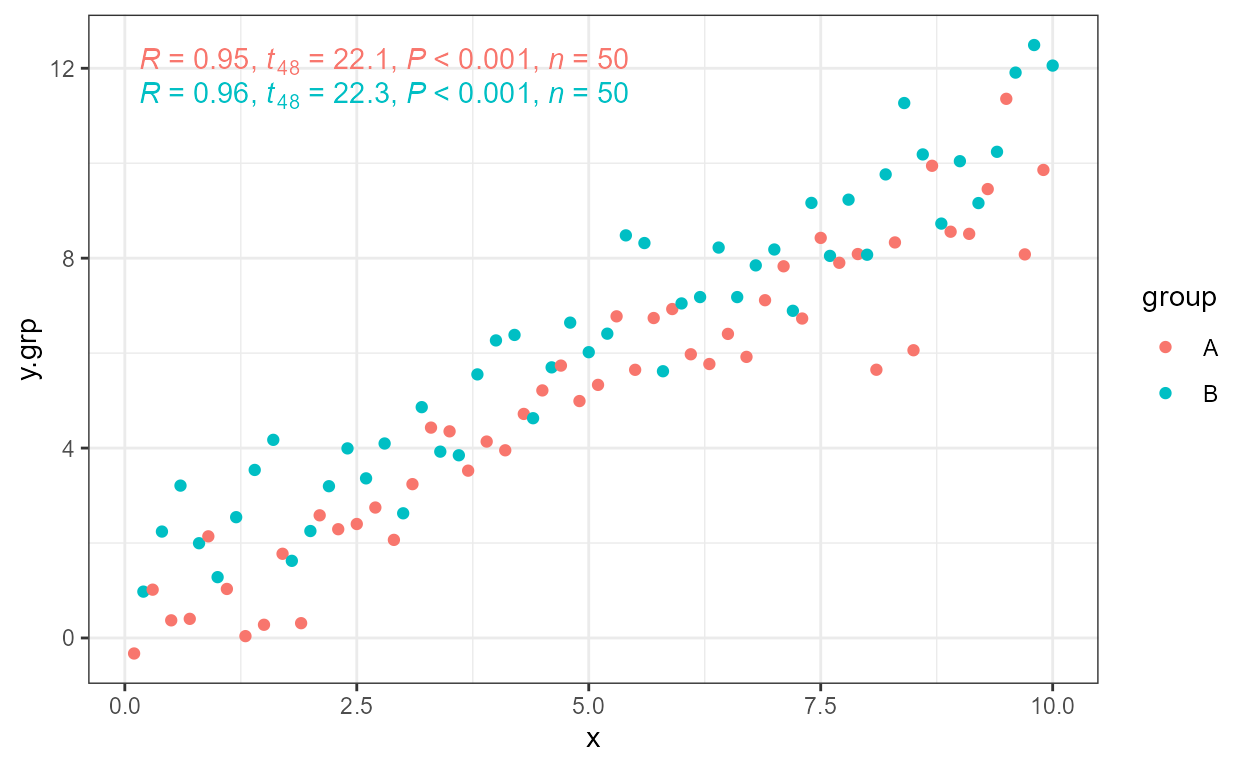
Together with the formatted character strings,
numeric, and in special cases, also logical, values
returned. When passing output.type = "numeric" in the call
to the statistics, these are the only values returned. In this case the
message lists them in interactive R sessions instead of the “label’s”
nicknames.
'stat_correlation' variables (1 rows): t.value, df, p.value, cor, test, n, method, r.conf.level, r.confint.low, r.confint.high, npcx, npcy.It is possible to set other aesthetics based on the outcome of the
correlation test. Within after_stat() the full name of the
variables is used. In this example, cor is the numeric
value and cor.label the matching character string.
ggplot(my.data, aes(x, y.grp)) +
geom_point() +
stat_correlation(mapping =
aes(label = after_stat(cor.label),
color =
after_stat(ifelse(cor > 0.955,
"red", "black")))) +
scale_color_identity() +
facet_wrap(~group)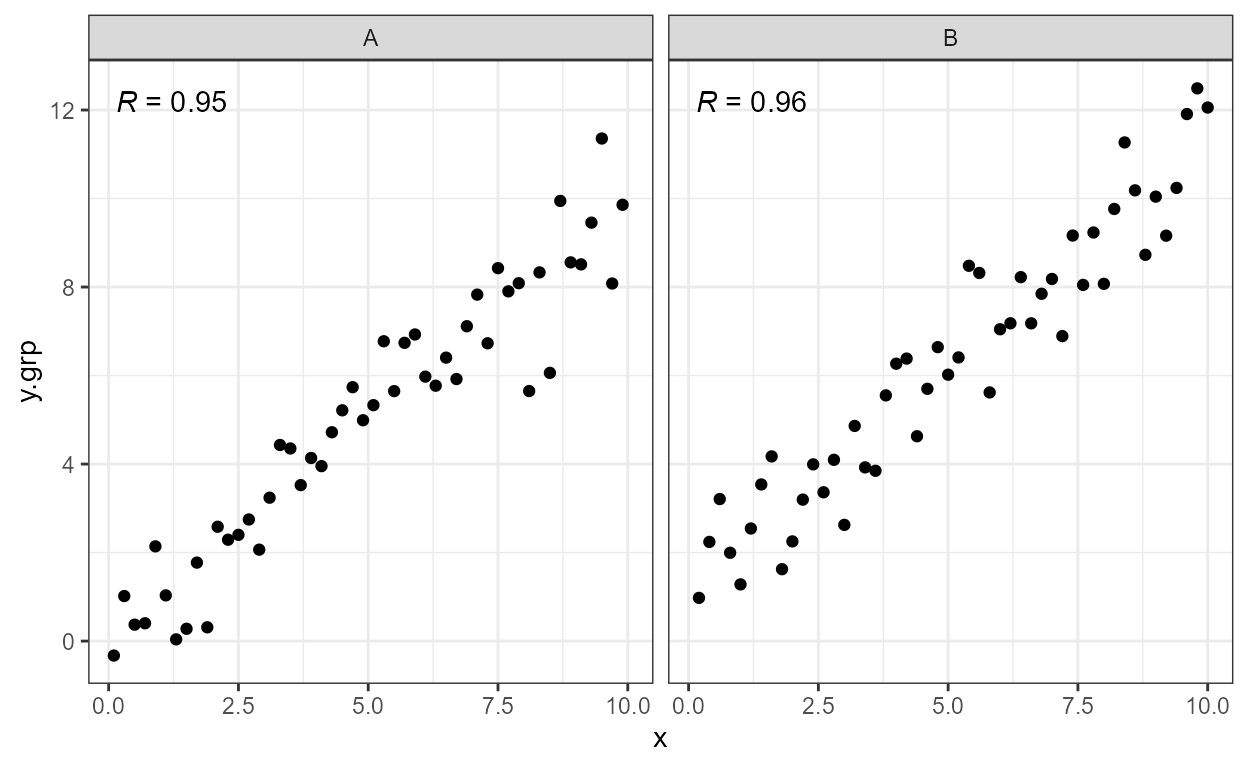
The approach shown above with "red" and
"black" as colours, can be adapted to use NA
(= invisible) as one colour to hide annotations automatically for
individual groups of data based on the statistical outcomes.
In ‘ggplot2’ (>= 4.0.0) parameter layout controls
deterministically on which panels plotting takes place. It is a
parameter inherited by statistics and geometries from their parent
object layer from ‘ggplot2’. For details, see the
documentation of ggplot2::layer().
Above the value of the correlation coefficient was used to set the
colour of the annotation label. All other numeric values returned, such
as p.value can be used similarly. Of course, any aesthetics
recognized by the geometry such as alpha and
fontface can be mapped to. As in ‘ggplot2’, any returned
numeric variable can be also used with continuous scales if
informative.
The statistics described below for adding equations of the fitted
models and other fitted parameter estimates as annotations have user
interfaces very similar to that of stat_correaltion(). To
avoid repetition, the sections are not exhaustive, and focus on the most
common use cases for each statistic. Most examples, with relatively
small edits can be adapted to use other annotation statistics from
‘ggpmisc’.
stat_poly_eq() and stat_poly_line()
A frequently used annotation in plots showing fitted lines is the
display of the parameters estimates from the model fit as an equation.
stat_poly_eq() automates this for models of y on
x or x on y fitted with different model fit
functions when the model formula is that of a regular
polynomial, possibly lacking an intercept term. Even user-defined
wrappers on model fitting functions can implement model selection or
method selection. When the argument for formula is not a
regular polynomial, the formatted character string for the model
equation is set to NA but otherwise, all numeric values and
all character labels for which estimates are available, are
returned normally.
By default stat_poly_line() uses
method = "lm" irrespective of the number of observations,
while stat_smooth() from ‘ggplot2’ the method used by
default depends on the number of observations.
stat_poly_line() also adds features that provide additional
flexibility in the control of the model prediction.
While stat_poly_line() displays the model prediction
graphically like stat_smooth(), stat_poly_eq()
is a “twin” that returns the parameter estimates and other statistics
from the model fit both as formatted character strings ready to be added
as annotations and as numeric values.
A frequently used annotation in plots showing fitted lines is the
display of the parameters estimates from the model fit as an equation.
stat_poly_eq() automates when the model
formula is that of a regular polynomial, possibly lacking
an intercept term. When the argument for formula is not a
regular polynomial, this formatted character string is set to
NA, but all numeric values and all character
labels for which estimates are available, are returned normally. The
formatted strings use different markup encodings depending on the
geometry used: plotmath expressions, \LaTeX for ‘xdvir’, markdown for ‘ggtext’,
markdown for ‘marquee’ and plain ASCII text. Nevertheless, all examples
below use R’s expression syntax.
The statistic stat_poly_line() has an user interface and
default arguments matching those of stat_poly_eq(). It also
supports natively a wide range of model fit functions including wrapper
functions that do model selection and/or method selection based on data
on a per group basis.
First, one example using defaults except for the model
formula. The best practice, ensuring that the formula used
in both statistics is the same is to assign the formula to a
variable, as shown here. This is because the same model is fit twice to
the same data, once in stat_poly_line() and
once in stat_poly_eq().
The terms in model formula for a polynomial can be entered
individually or using R’s function poly(). When using
function poly() it is necessary to set
raw = TRUE as the default is to use orthogonal polynomials
which although fitting the same line will have different estimates for
the coefficients than those in the usual raw polynomials.
As above, messages are displayed in R interactive sessions, one by
each of the two stats. Names of labels that are not available, i.e., set
to NA are not listed.
'stat_poly_line' variables (80 rows): x, y, ymin, ymax, flipped_aes.
'stat_poly_eq' labels (1 rows): eq, R2, adj.R2, R2.confint, AIC, BIC, F, P, n, grp, method.
formula <- y ~ poly(x, 3, raw = TRUE)
ggplot(my.data, aes(x, y.poly)) +
geom_point() +
stat_poly_line(formula = formula) +
stat_poly_eq(formula = formula)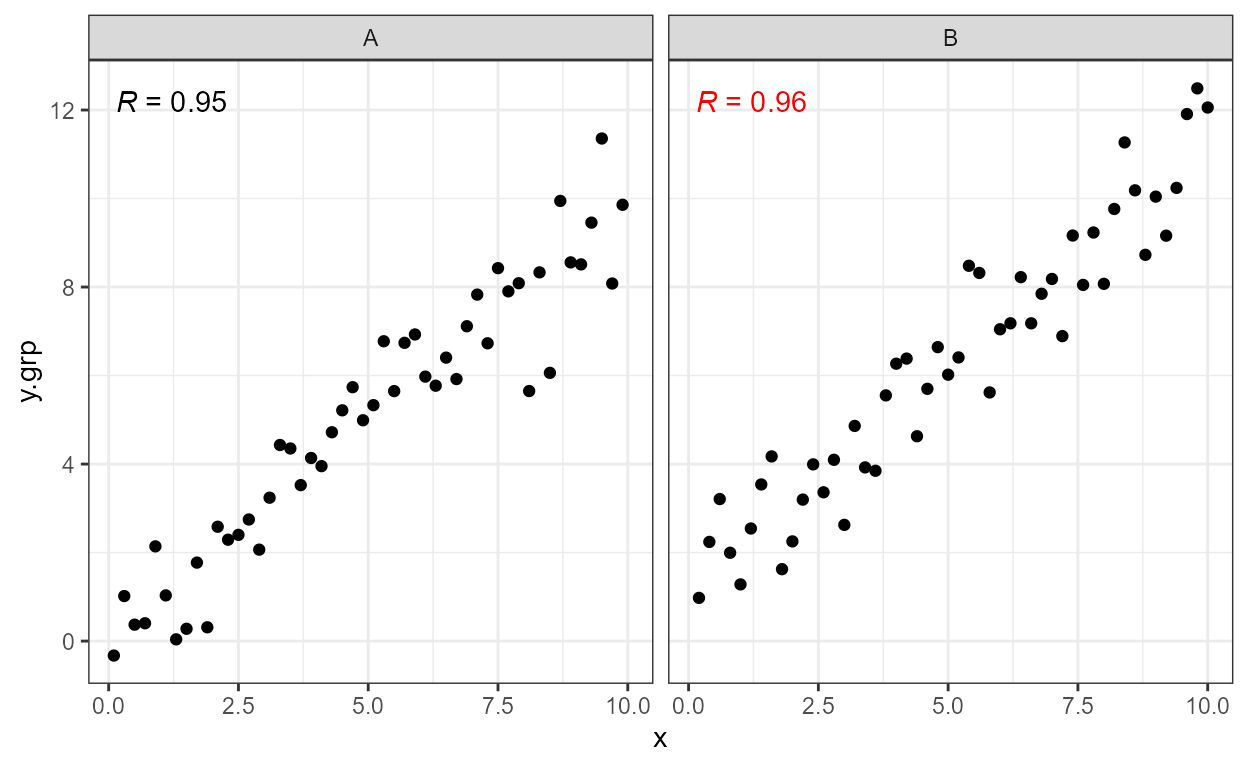
As indicated by the message, a ready formatted equation,
"eq", is returned as a plotmath-formatted
character string ready to be parsed into an
expression. Function use_label() or function
f_use_label() can be used to select or assemble the
expression and map it to the label aesthetic. The default
separator used in use_label() is suitable for labels to be
parsed into R expressions, but it can be over-ridden by passing an
argument to parameter sep. In this example, the fitted
model equation with "eq", R^2 with "R2" and the number of
observations in the group as "n", are are mapped to the
label aesthetic with use_label() .
formula <- y ~ poly(x, 3, raw = TRUE)
ggplot(my.data, aes(x, y.poly)) +
geom_point() +
stat_poly_line(formula = formula) +
stat_poly_eq(mapping = use_label("eq", "R2", "n"), formula = formula)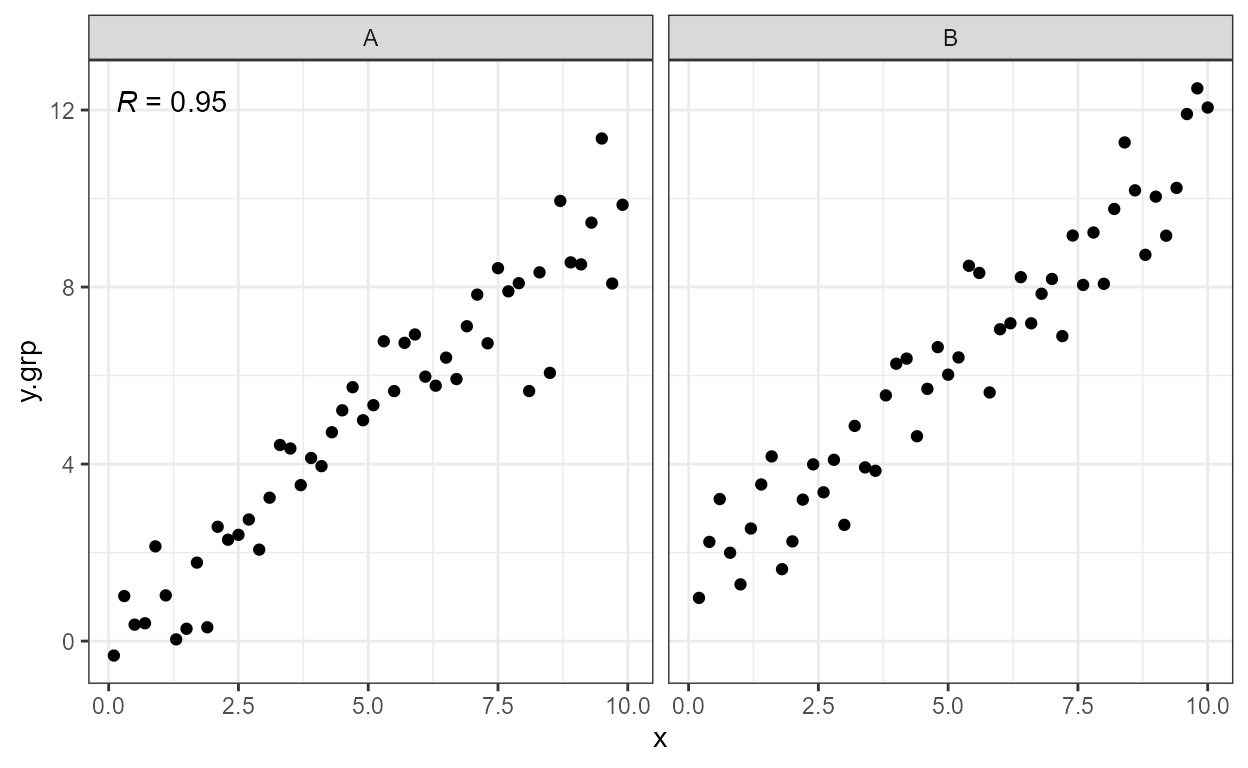
In this case we add another layer with additional information,
creating the mapping to the label aesthetic with function
f_use_label(). The code below shows how the labels are
inserted at the locations marked with %s in the format
string. In this case, to keep the example simple, the labels are
formatted as plain ASCII "text".
formula <- y ~ poly(x, 3, raw = TRUE)
ggplot(my.data, aes(x, y.poly)) +
geom_point() +
stat_poly_line(formula = formula) +
stat_poly_eq(mapping = use_label("eq", "R2"), formula = formula) +
stat_poly_eq(mapping =
f_use_label("method", "n",
format =
"fitted by %s to %s observations"),
output.type = "text",
formula = formula,
label.y = 0.88)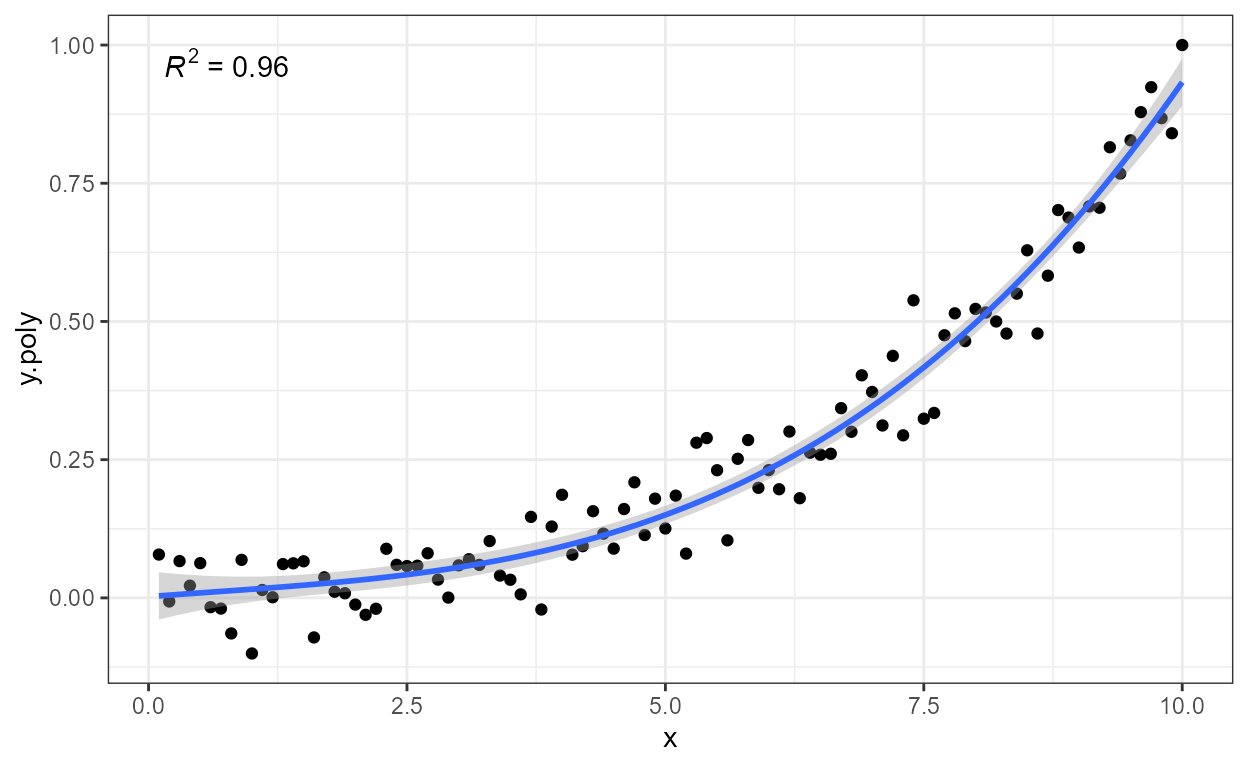
In the example above, two separate layers were needed because plotmath expressions do not support multiple lines of text. This is not the case with \LaTeX and Markdown.
When different annotations are to be at far apart locations on the
plotting area, it is always necessary to add them as separate plot
layers. Below, the adjusted coefficient of determination, R^2_\mathrm{adj}, and Akaike’s information
criterion, AIC, are inserted in different sizes and in opposite corners
using two plot layers, i.e., We call stat_poly_eq()
twice.
formula <- y ~ poly(x, 3, raw = TRUE)
ggplot(my.data, aes(x, y.poly)) +
geom_point() +
stat_poly_line(formula = formula) +
stat_poly_eq(mapping = use_label("adj.R2"), formula = formula) +
stat_poly_eq(mapping = use_label("AIC"), label.x = "right", label.y = "bottom", size = 3,
formula = formula)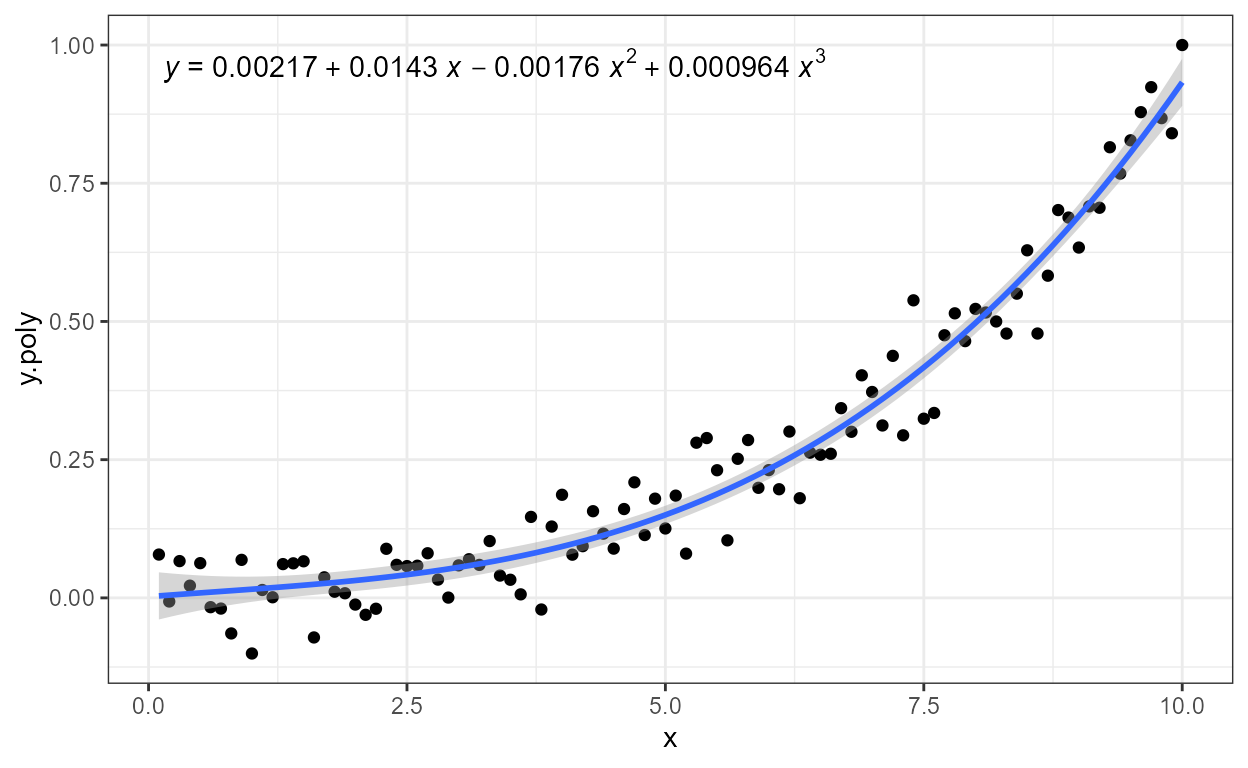
As shown for stat_correlation(), the mapping can also be
done with ggplot2::aes() using the full bare name of the
variable returned using ggplot2::after_stat(). This is
useful when use_label() and f_use_label() are
not flexible enough, such as when mappings are complex or use computed
numeric or logical values in addition or
instead of the ready formatted character strings.
To be able to fully exploit the flexibility of
f_use_label() or when constructing the character string
within a call to aes(), familiarity with the markup
encoding used is needed. For example, inserting a comma plus white space
in a plotmath expression requires some trickery in the argument
passed to parameter sep when paste(), or
use_label() are used. Do also note the need to
escape the embedded quotation marks as \".
Combining the labels in this way ensures correct alignment. To insert
only white space sep = "~~~~~" can be used, with each tilde
character, ~, adding a rather small amount of horizontal
white space. Expressions support in-line font face changes with
plain(), italic(), bold() or
bolditalic() an other commands as described in the help
entry for plotmath.
It can be easier in many cases to insert a literal character string
into an expression, as shown nelow, by enclosing the string in
*. Plotmath expressions can be used in ‘ggplot2’
also for the scale name, including axis titles, as shown
below, to ensure consistency with the typesetting.
formula <- y ~ poly(x, 3, raw = TRUE)
ggplot(my.data, aes(x, y.poly)) +
geom_point() +
stat_poly_line(formula = formula) +
stat_poly_eq(mapping = use_label("eq", "adj.R2", sep = "*\" with \"*"),
formula = formula) +
labs(x = expression(italic(x)), y = expression(italic(y)))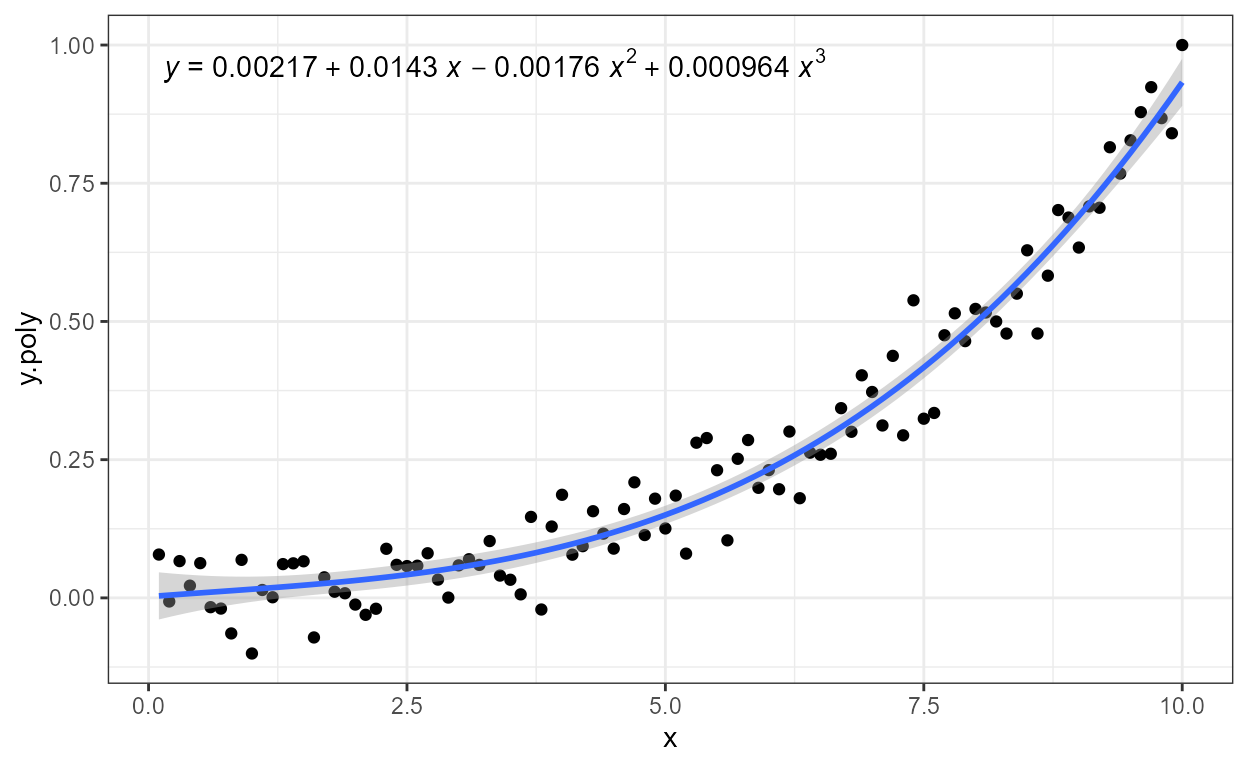
stat_poly_eq() allows some control on the generation of
the formatted fitted model equation and other formatted character
labels. (For details, please, consult the documentation of each
function.) For example the number of significant digits displayed,
whether to use upper- or lower case P
for probabilities, displaying polynomials with increasing or decreasing
powers, as well as the substitution of x and y by more
meaninful symbols. A few examples follow.
Next, one example of how to remove the left hand side (lhs).
formula <- y ~ poly(x, 3, raw = TRUE)
ggplot(my.data, aes(x, y.poly)) +
geom_point() +
stat_poly_line(formula = formula) +
stat_poly_eq(mapping = use_label("eq"),
eq.with.lhs = FALSE,
formula = formula)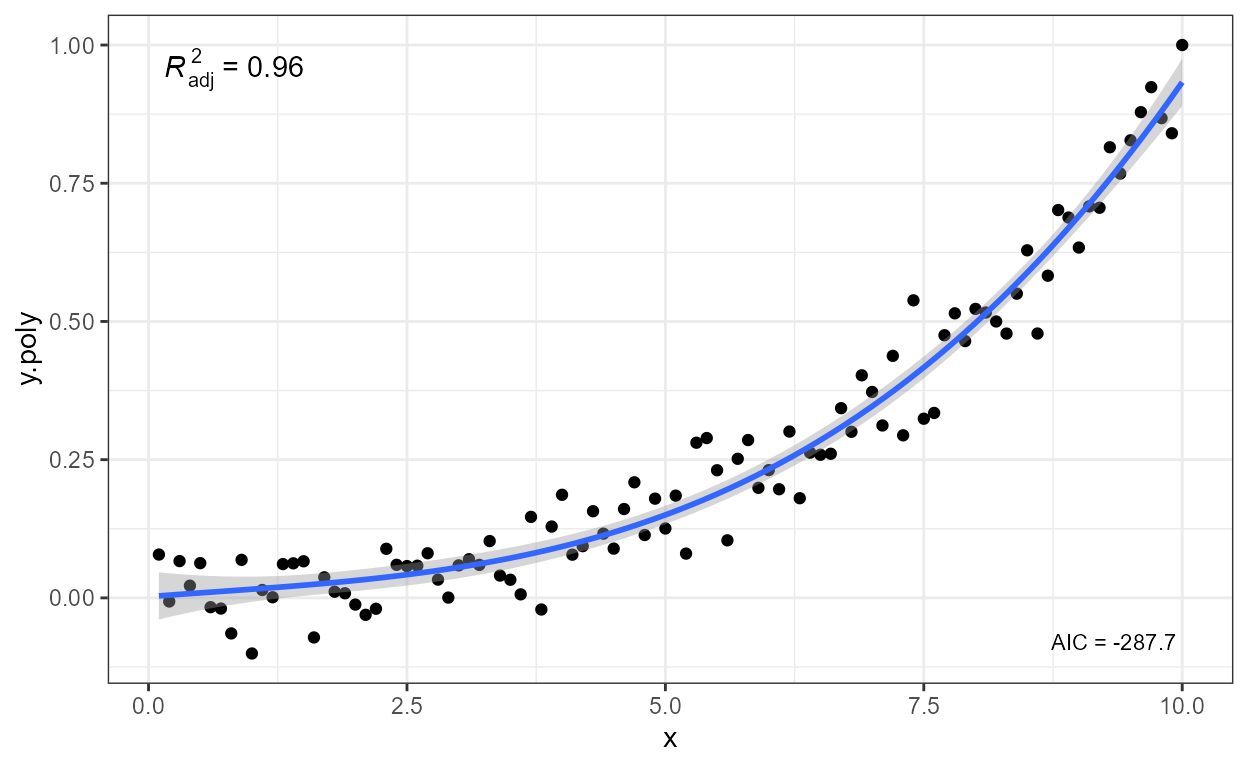
Replacing the default lhs y by \hat{y}.
formula <- y ~ poly(x, 3, raw = TRUE)
ggplot(my.data, aes(x, y.poly)) +
geom_point() +
stat_poly_line(formula = formula) +
stat_poly_eq(mapping = use_label("eq"),
eq.with.lhs = "italic(hat(y))~`=`~",
formula = formula)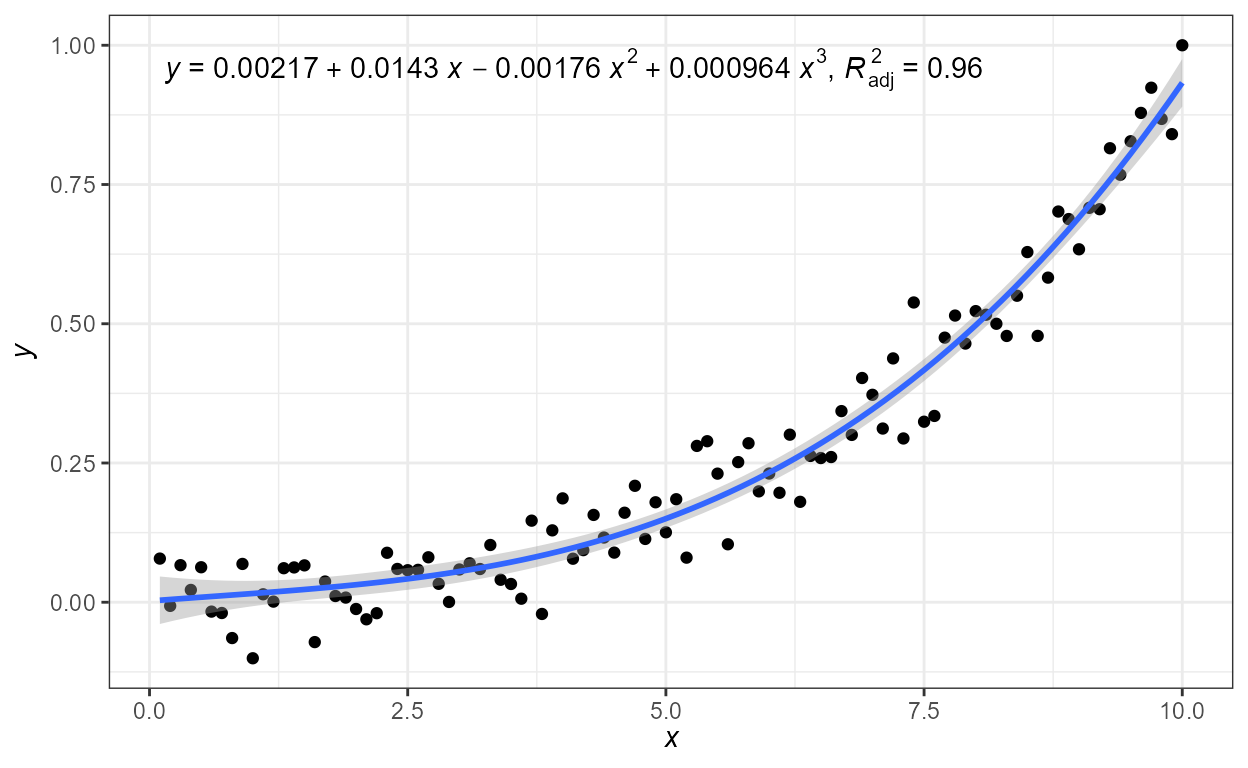
Replacing both the lhs, y, and the variable symbol, x, used on the rhs.
formula <- y ~ poly(x, 3, raw = TRUE)
ggplot(my.data, aes(x, y.poly)) +
geom_point() +
stat_poly_line(formula = formula) +
stat_poly_eq(mapping = use_label("eq", "R2"),
eq.with.lhs = "italic(h)~`=`~",
eq.x.rhs = "~italic(z)",
formula = formula) +
labs(x = expression(italic(z)), y = expression(italic(h)))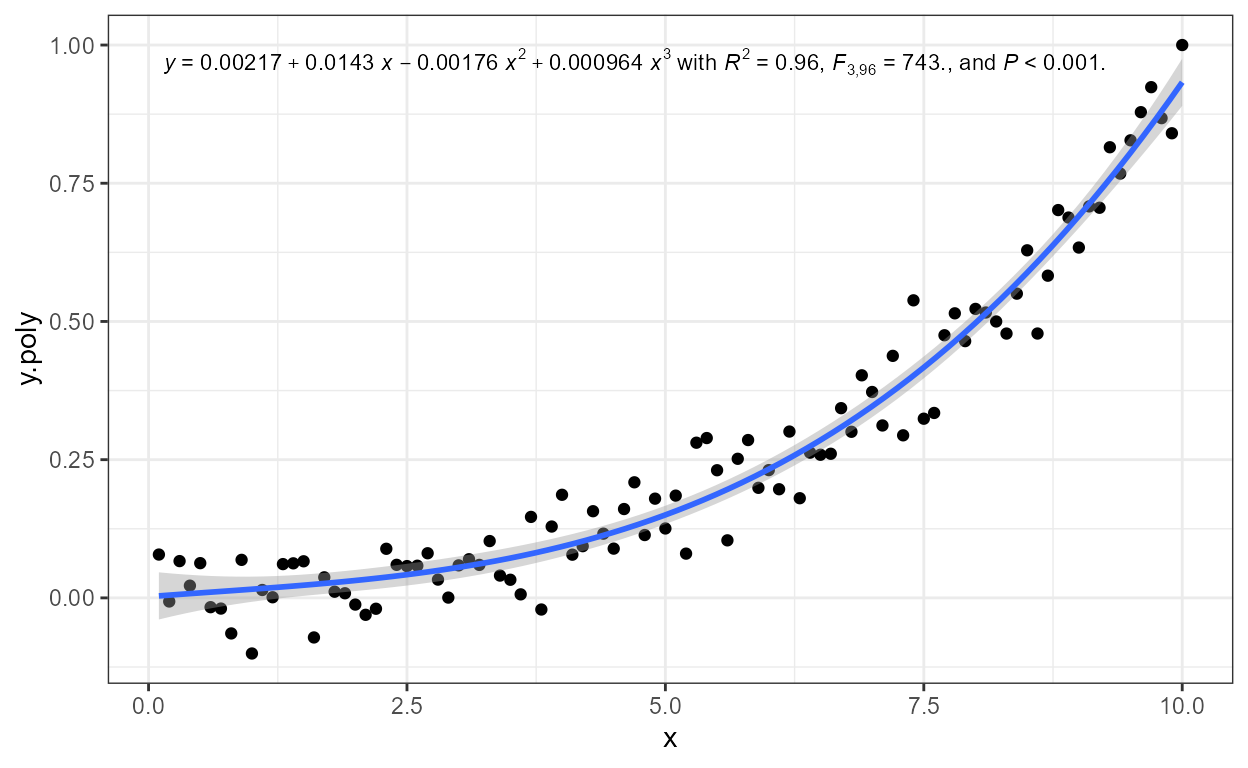
As any valid plotmath expression can be used, Greek letters are also supported, as well as the inclusion in the label of variable transformations used in the model formula or applied to the data. In addition, in the next example we insert white space in between the parameter estimates and the variable symbol in the equation.
formula <- y ~ poly(x, 3, raw = TRUE)
ggplot(my.data, aes(x, log10(y.poly + 1e6))) +
geom_point() +
stat_poly_line(formula = formula) +
stat_poly_eq(mapping = use_label("eq"),
eq.with.lhs = "plain(log)[10](italic(delta)+10^6)~`=`~",
eq.x.rhs = "~Omega",
formula = formula) +
labs(y = expression(plain(log)[10](italic(delta)+10^6)),
x = expression(Omega)) +
scale_y_continuous(expand = expansion(c(0.1, 0.2)),
labels = function(x) {sprintf("6 + %.0e", x - 6)})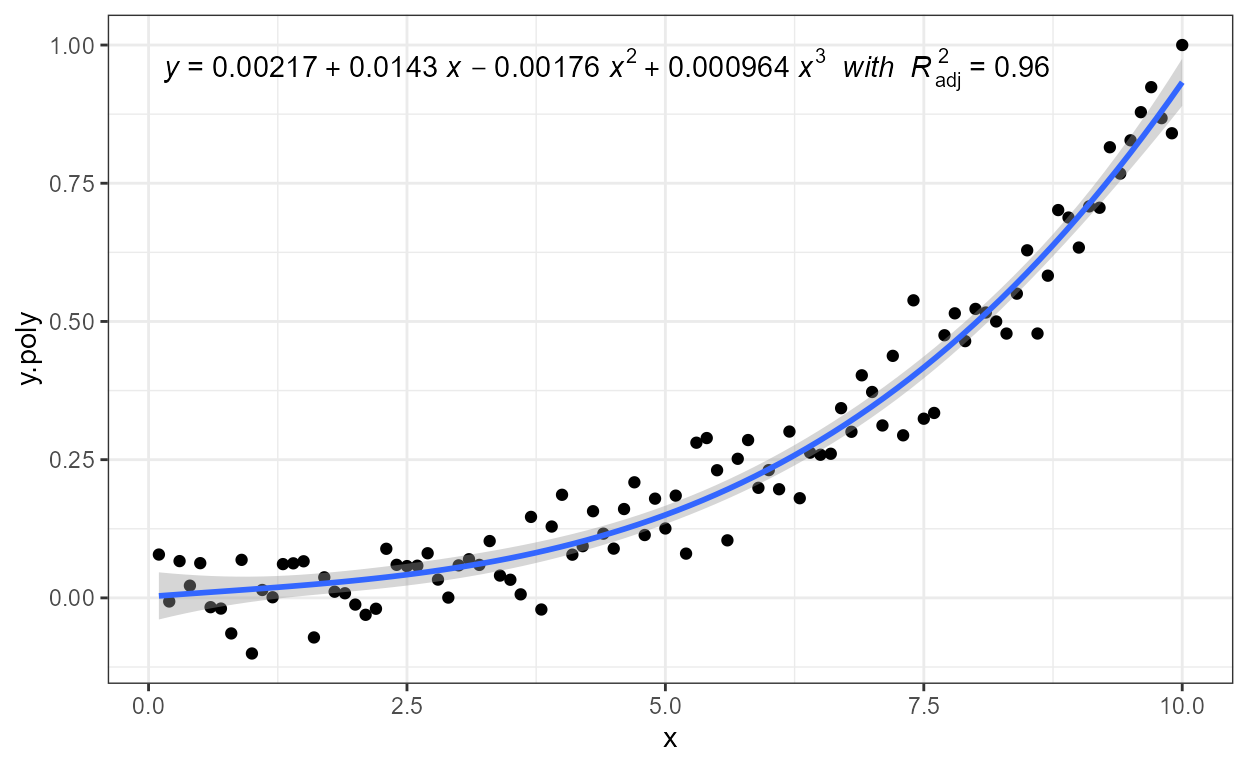
A degree 1 polynomial is linear regression with
formula = y ~ x, which is the default. Linear regression
through the origin is supported by passing
formula = y ~ x - 1, or formula = y ~ x + 0.
High order polynomials are most easily encoded using poly()
in the model formula, as shown above with
formula = y ~ poly(x, 3, raw = TRUE).
Intercept forced to zero for a third degree polynomial defined
explicitly, as this case is not supported by poly().
formula <- y ~ x + I(x^2) + I(x^3) - 1
ggplot(my.data, aes(x, y.poly)) +
geom_point() +
stat_poly_line(formula = formula) +
stat_poly_eq(aes(label = after_stat(eq.label)), formula = formula)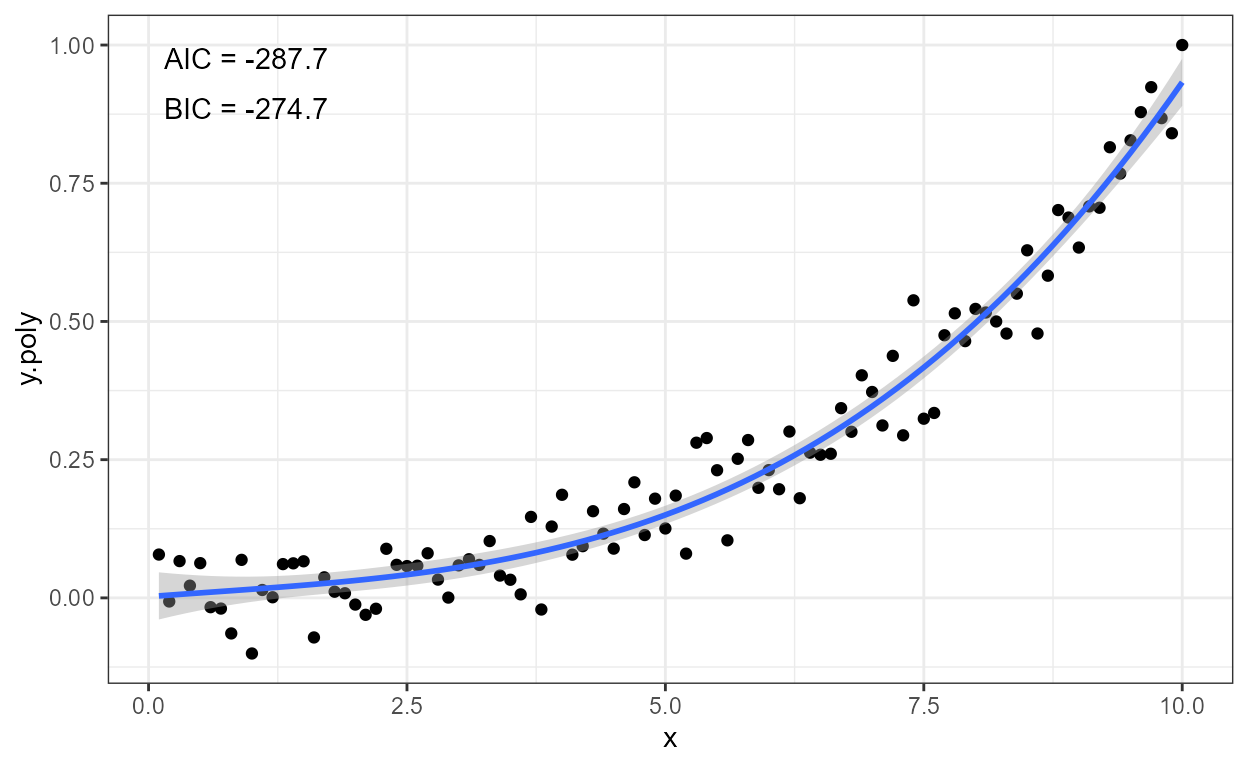
Even when labels are returned, numeric values are also returned. This
can be used in ggplot2::aes() for example to show the
equation only if a certain condition like a minimum value for
r.square or maximum value for p.value has been
exceeded. This is useful when the same model fitting code and plot are
used with different data. This is the case when a report with embedded
code is run repeatedly on different data, but also when the data in
different groupings or planels in a single plot differ.
formula <- y ~ poly(x, 3, raw = TRUE)
ggplot(my.data, aes(x, y.poly)) +
geom_point() +
stat_poly_line(formula = formula) +
stat_poly_eq(aes(label =
after_stat(
ifelse(adj.r.squared > 0.3,
paste(eq.label, adj.rr.label,
sep = "*\", \"*"),
adj.rr.label))),
formula = formula) +
labs(x = expression(italic(x)), y = expression(italic(y)))
We give below several examples to demonstrate how other components of
the ggplot object affect the behaviour of this
statistic.
Facets work as expected both with fixed or free scales. Although below we have to adjust the size of the font used for the equation.
formula <- y ~ poly(x, 3, raw = TRUE)
ggplot(my.data, aes(x, y.poly.grp)) +
geom_point() +
stat_poly_line(formula = formula) +
stat_poly_eq(aes(label = after_stat(eq.label)), size = 2.5,
formula = formula) +
facet_wrap(~group)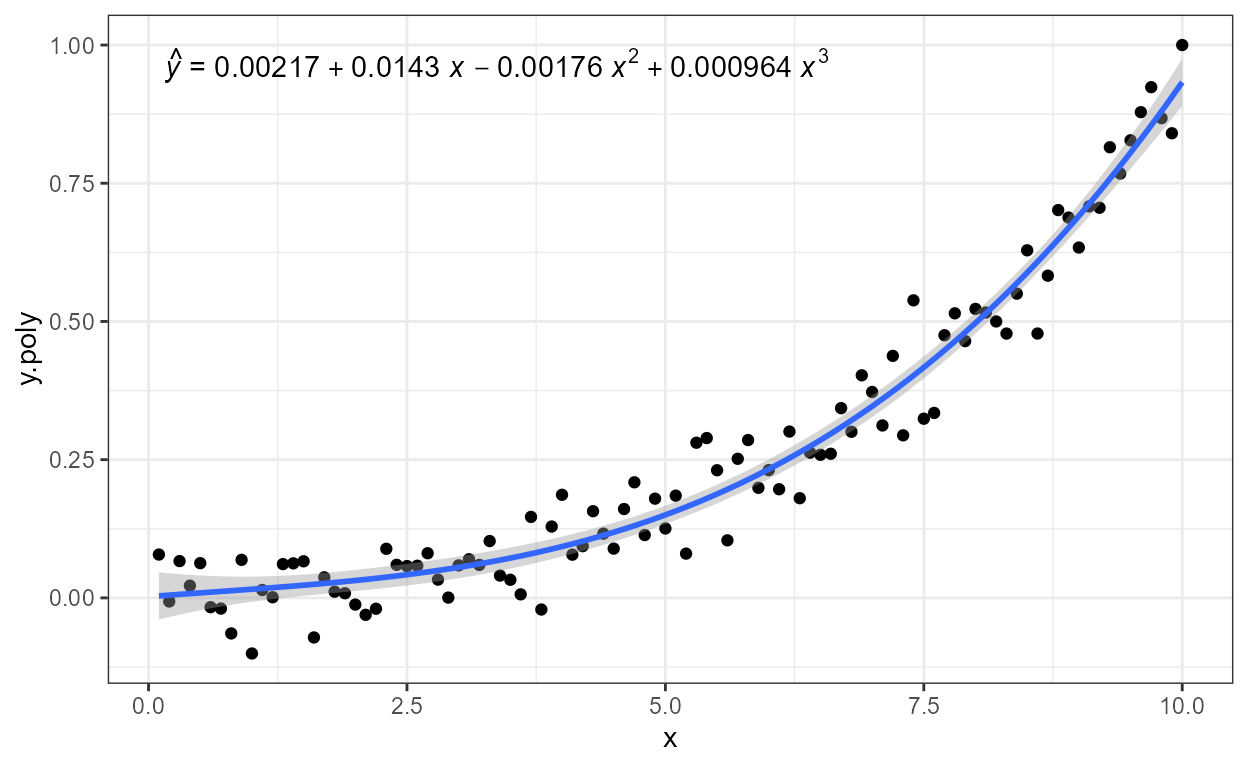
formula <- y ~ poly(x, 3, raw = TRUE)
ggplot(my.data, aes(x, y.poly.grp)) +
geom_point() +
stat_poly_line(formula = formula) +
stat_poly_eq(aes(label = after_stat(eq.label)),
size = 2.5,
formula = formula) +
facet_wrap(~group, scales = "free_y")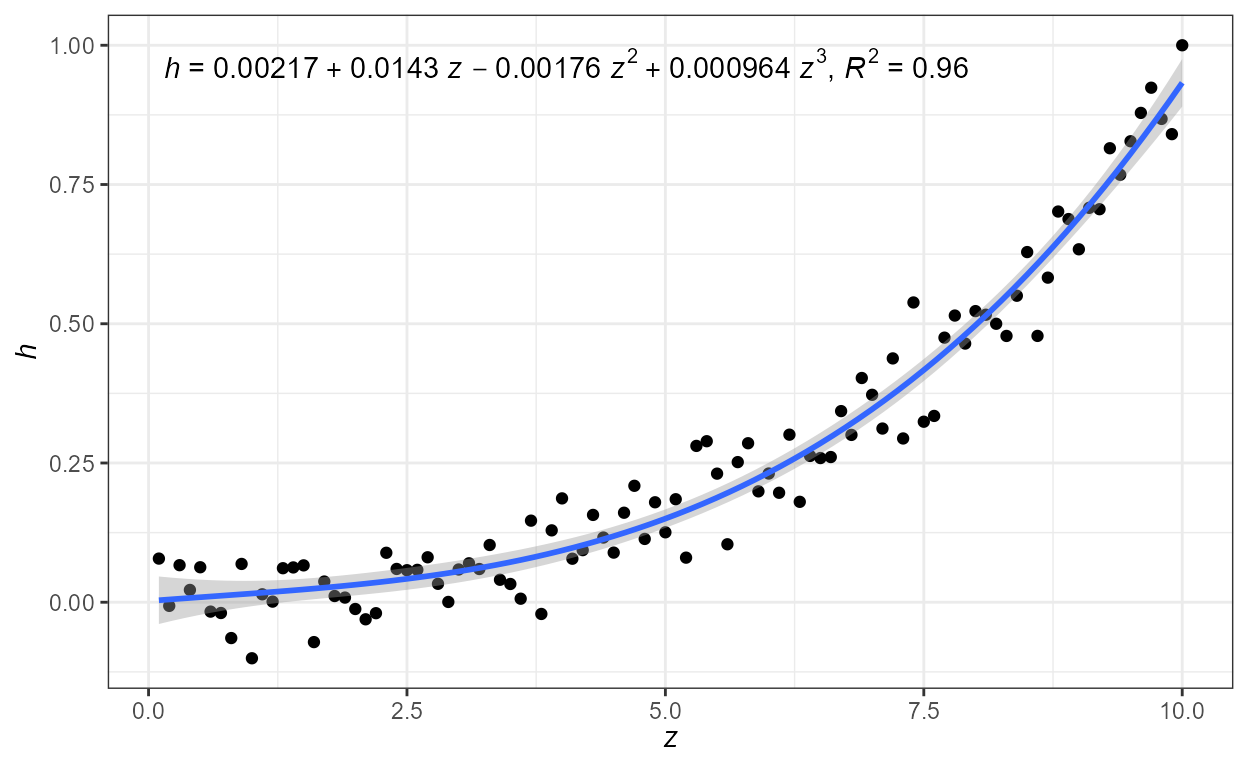
Grouping works as expected. In this example we create groups
using the colour aesthetic, but factors or discrete variables mapped to
other aesthetics including the “invisible” group aesthetic
are handled in the same way.
formula <- y ~ poly(x, 3, raw = TRUE)
ggplot(my.data,
aes(x, y.poly.grp, colour = group)) +
geom_point() +
stat_poly_line(formula = formula) +
stat_poly_eq(aes(label = after_stat(eq.label)),
formula = formula)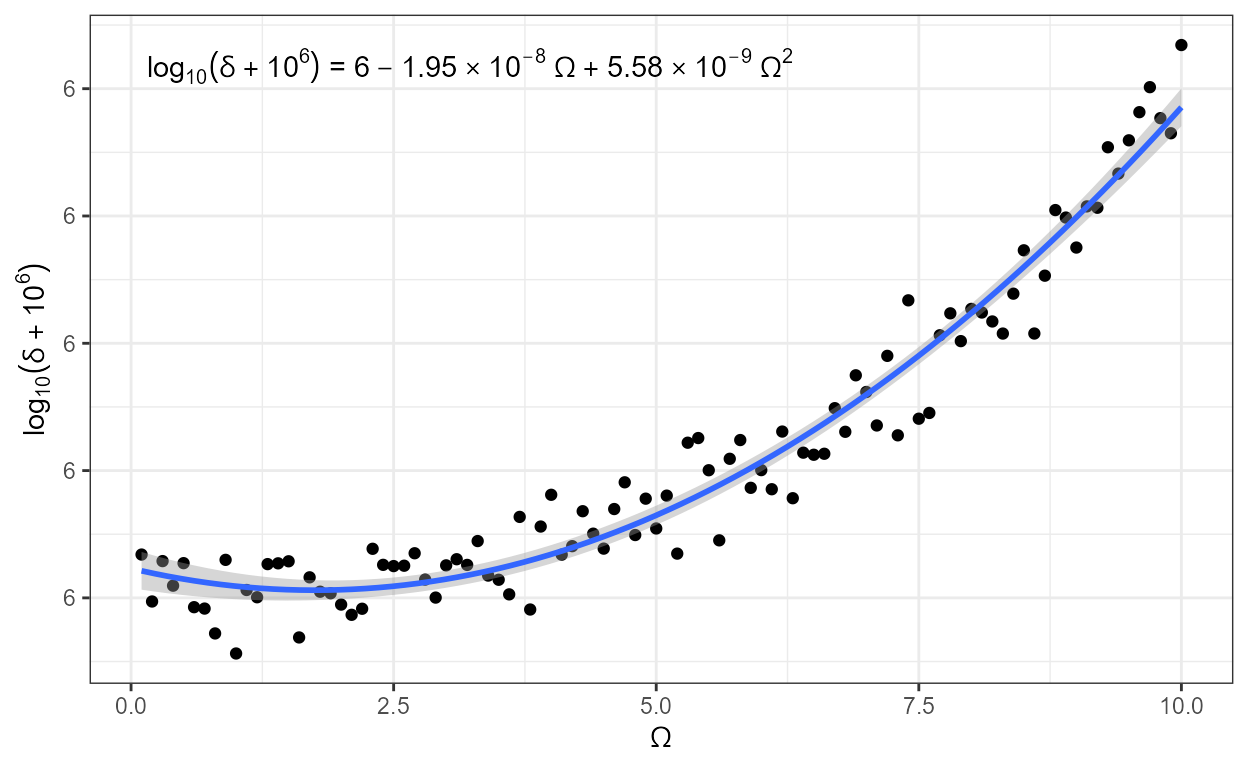
When not using colours, a label can be added to the equation to
identify the group, using a pseudo-aesthetic named
grp.label.
formula <- y ~ poly(x, 3, raw = TRUE)
ggplot(my.data,
aes(x, y.poly.grp,
linetype = group,
grp.label = group)) +
geom_point() +
stat_poly_line(formula = formula, colour = "black") +
stat_poly_eq(aes(label =
after_stat(paste("bold(", grp.label, "*\":\")~~",
eq.label, sep = ""))),
formula = formula)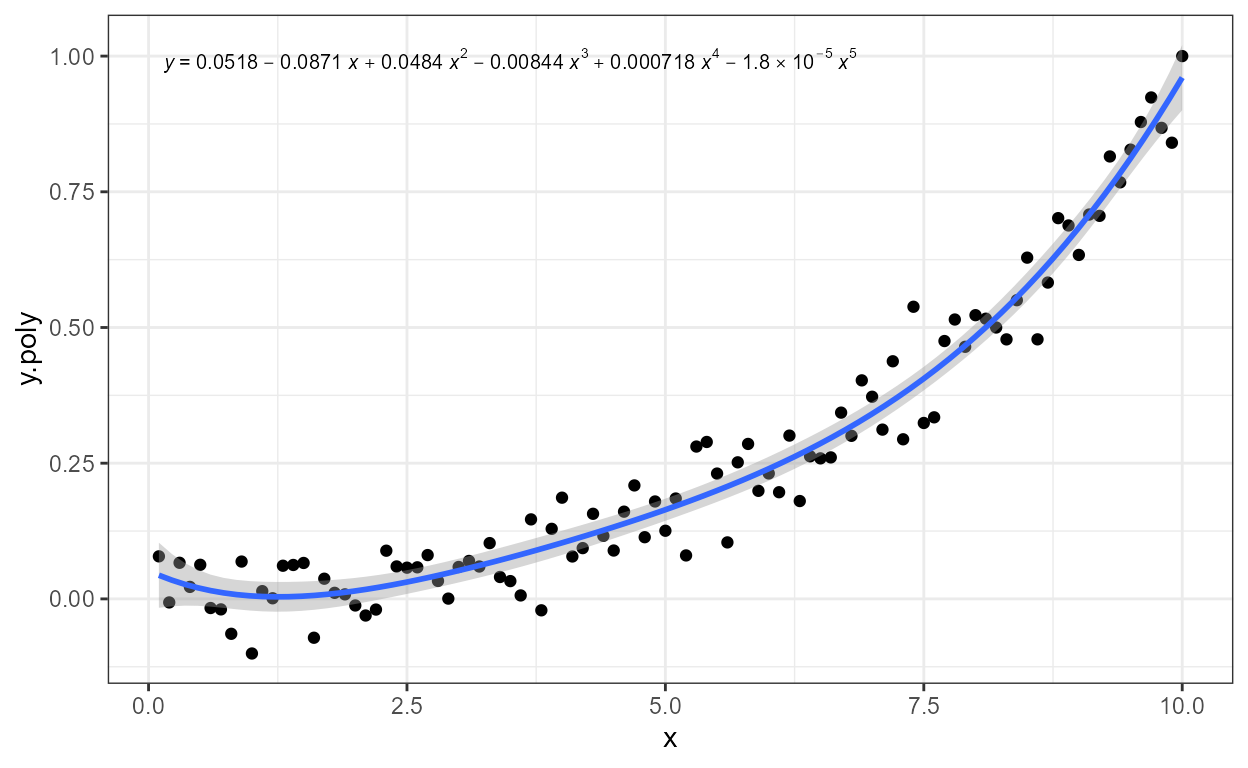
stat_poly_eq() computes the positions of labels for the
different groups to avoid overlaps. Flexibility in this automation is
provided by parameters, vstep and hstep giving
the distance between succesive labels, and label.x and
label.y giving the starting position, when of length equal
to one, all in values ranging between 0 and 1, when using the default
ggpp::geom_text_npc(). label.x and
label.y in addition accept character strings, similarly as
for justification in ‘ggplot2’ geoms.
formula <- y ~ poly(x, 3, raw = TRUE)
ggplot(my.data,
aes(x, y.poly.grp, colour = group)) +
geom_point() +
stat_poly_line(formula = formula) +
stat_poly_eq(aes(label = after_stat(eq.label)),
formula = formula,
label.x = "centre",
vstep = 0.1)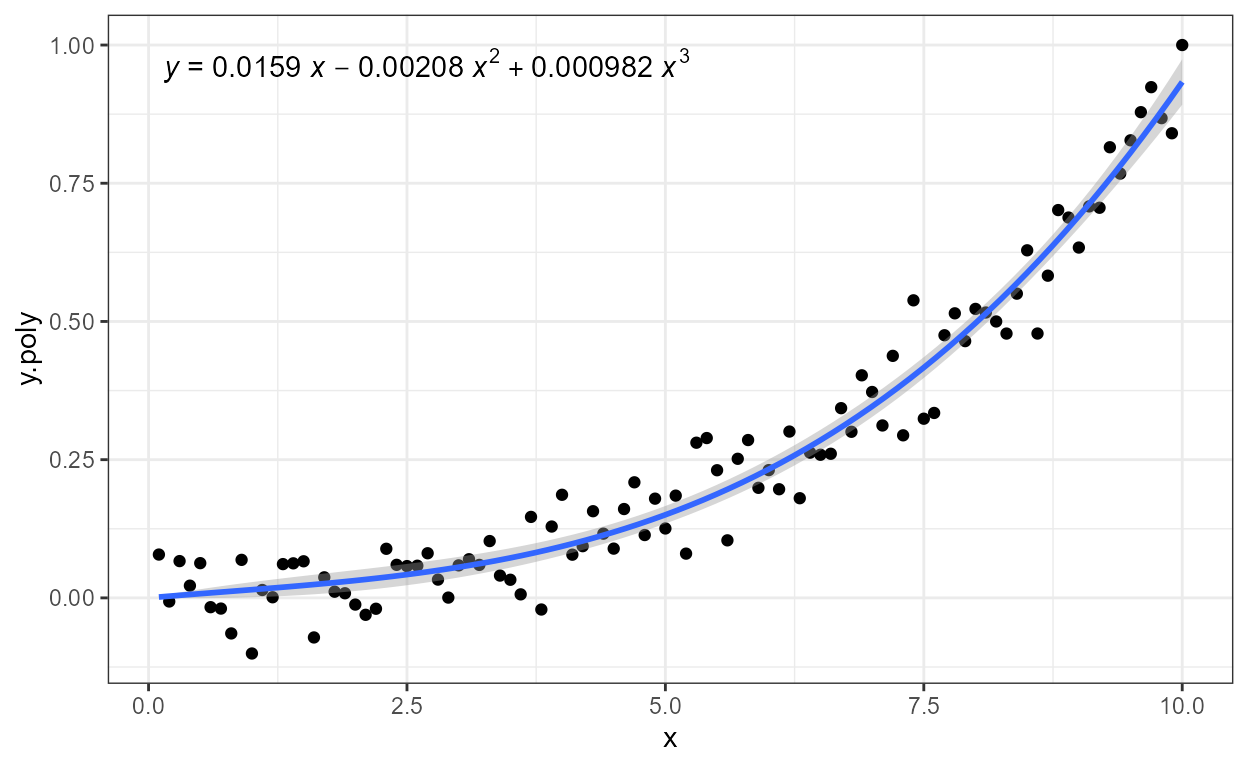
The arguments passed to label.x and label.y
can directly given the positions of each of the labels.
formula <- y ~ poly(x, 3, raw = TRUE)
ggplot(my.data,
aes(x, y.poly.grp, colour = group)) +
geom_point() +
stat_poly_line(formula = formula) +
stat_poly_eq(aes(label = after_stat(eq.label)),
formula = formula,
label.x = c("right", "centre"),
label.y = c("bottom", "top")) +
scale_y_continuous(expand = expansion(c(0.12, 0.12)))
If grouping is not the same within each panel created by faceting, i.e., not all groups have data in all panels, the automatic location of labels results in gaps for the factor levels not present in a given panel as in this example. This behaviour ensures consistent positioning of labels for the same groups across panels. If positioning that leaves no gaps is desired, it is possible to explicitly pass the positions for each individual label as shown above.
In some cases gaps may be desirable to highlight the missing groups, but when not, the positions can be set manually as in the next example.
formula <- y ~ poly(x, 3, raw = TRUE)
ggplot(my.data,
aes(x, y.poly.grp, colour = group.abcd)) +
geom_point(shape = 21, size = 3) +
stat_poly_line(formula = formula) +
stat_poly_eq(aes(label = after_stat(rr.label)),
size = 3,
formula = formula) +
facet_wrap(~group, scales = "free_y")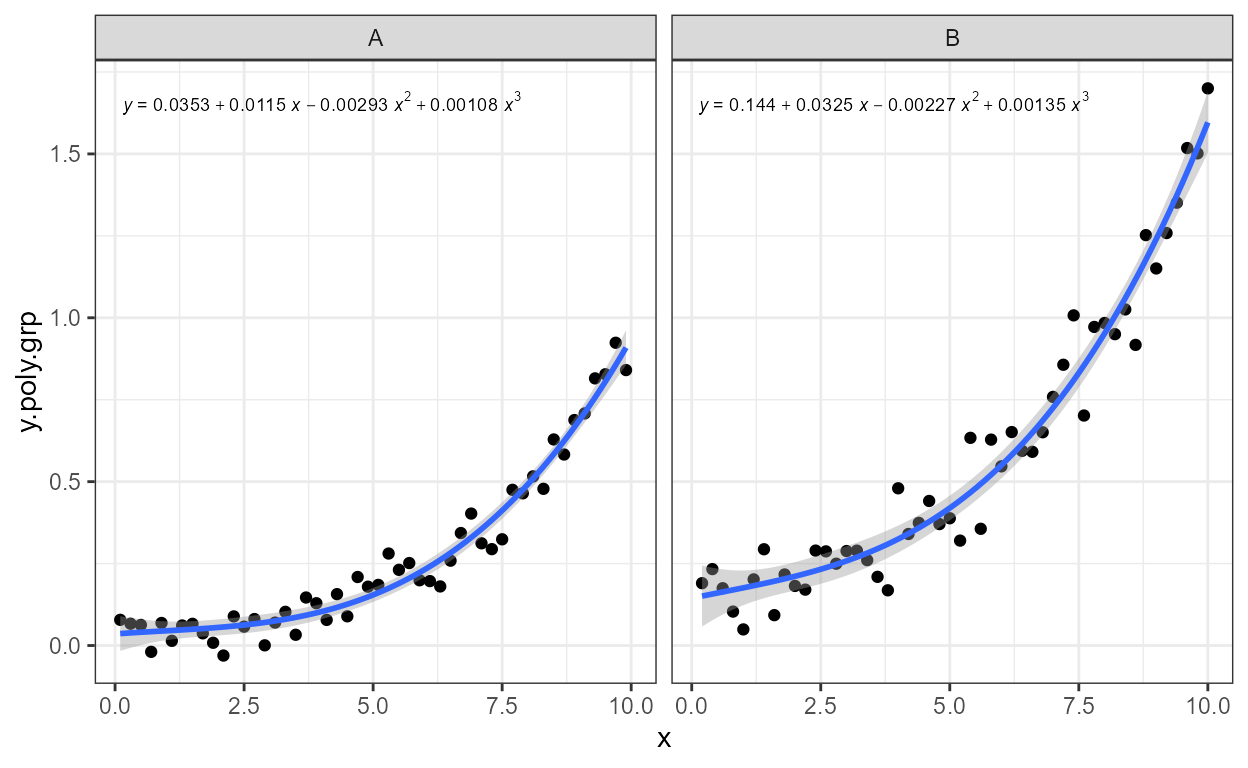
When setting positions manually with arguments (in npc
units, 0..1) passed as argument to label.y (and/or to
label.x), be aware that the positions must be given in the
order of the levels of the groups, e,g,, factor levels in the case of
grouping based on a single aesthetic. This is not necessarily the plot
panel order!
formula <- y ~ poly(x, 3, raw = TRUE)
ggplot(my.data,
aes(x, y.poly.grp, colour = group.abcd)) +
geom_point(shape = 21, size = 3) +
stat_poly_line(formula = formula) +
stat_poly_eq(use_label("R2"),
size = 3,
label.y = c(0.95, 0.95, 0.9, 0.9),
formula = formula) +
facet_wrap(~group, scales = "free_y")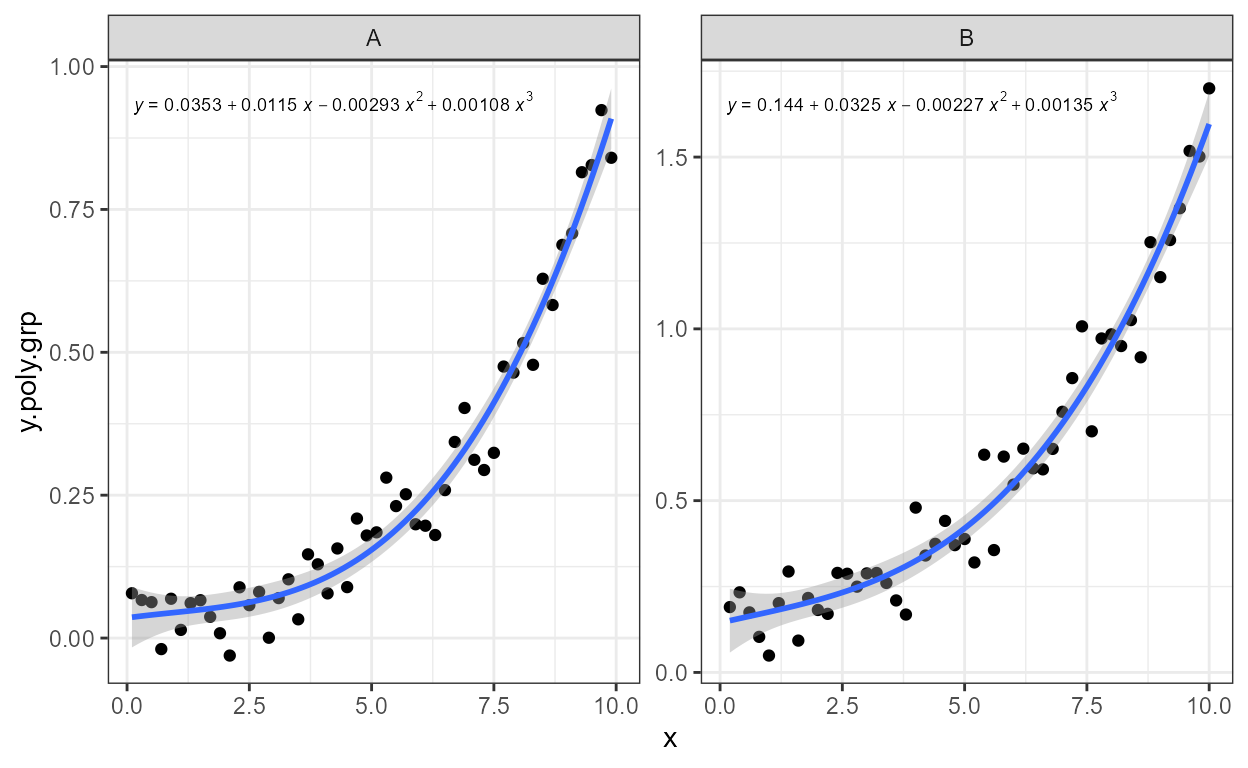
It is possible to use ggplot2::geom_text(),
ggplot2::geom_label(),
ggtext::geom_richtext(),
marquee::geom_marquee(), dvixr::geom_latex(),
ggrepel::geom_text_repel(),
ggrepel::geom_label_repel(),
ggrepel::geom_marquee_repel(), etc., instead of the default
ggpp::geom_text_npc() (or
ggpp::geom_label_npc()) but in such case, if label
coordinates are given as numeric values they should be expressed in
native data coordinates.
formula <- y ~ poly(x, 3, raw = TRUE)
ggplot(my.data,
aes(x, y.poly.grp, colour = group)) +
geom_point() +
stat_poly_line(formula = formula) +
stat_poly_eq(geom = "text",
aes(label = after_stat(eq.label)),
label.x = c(10, 9),
label.y = c(-0.15, 1.8),
hjust = "inward",
formula = formula)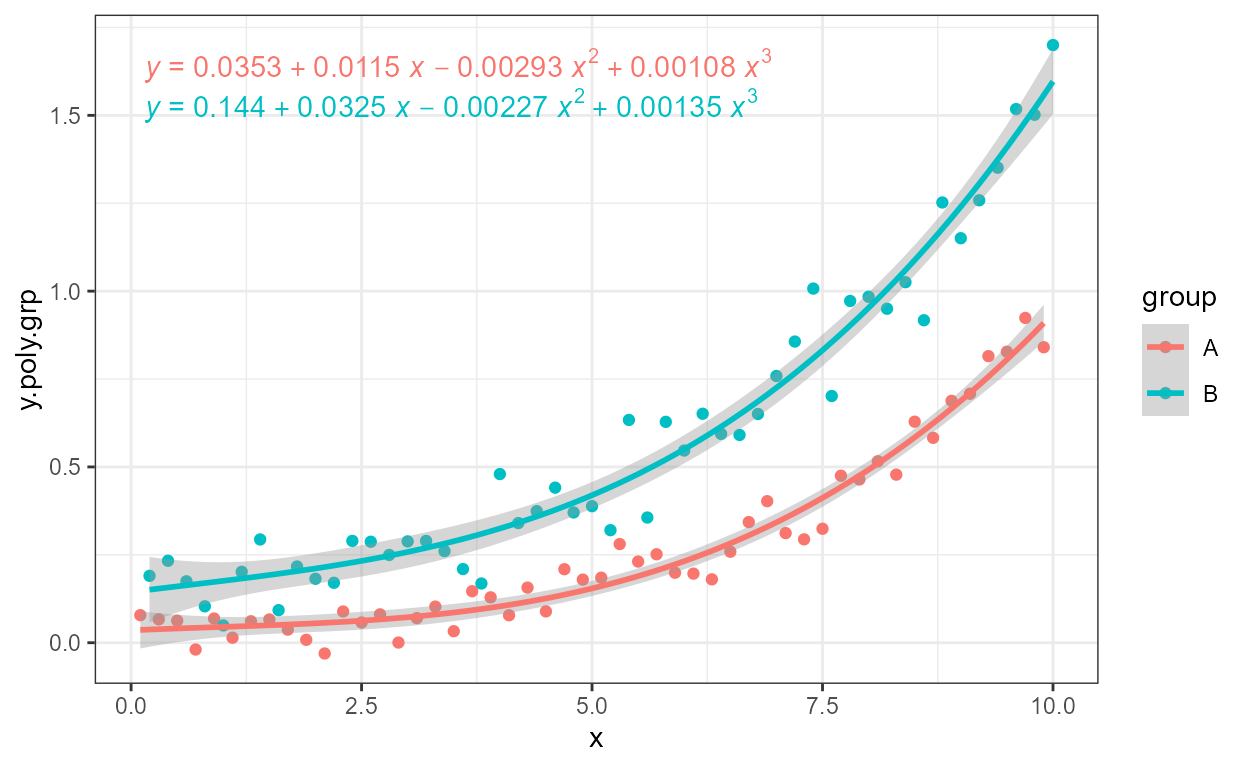
Note: Automatic positioning using
ggplot2::geom_text() and ggplot2::geom_label()
is supported except when faceting uses free scales. In this case
ggpp::geom_text_npc() and/or
ggpp::geom_label_npc() or positions supplied by the user
must be used.
Occasionally, possibly as a demonstration in teaching, we may want to compare a fit of x on y and one of y on x in the same plot. The example below also serves as introduction to the next section, which describes the use of major axis regression or Model II regression.
As is the case for model fitting functions themselves, which variable
is dependent (response) and which is independent (explanatory) is simply
indicated by the model equation passed as argument to
formula, or consistently with
ggplot2::stat_smooth() through parameter
orientation as show below.
ggplot(my.data, aes(x, y.sd3)) +
geom_point() +
stat_poly_line(color = "blue") +
stat_poly_eq(mapping = use_label("R2", "eq"), color = "blue") +
stat_poly_line(color = "red", orientation = "y") +
stat_poly_eq(mapping = use_label("R2", "eq"), color = "red",
orientation = "y", label.y = 0.89)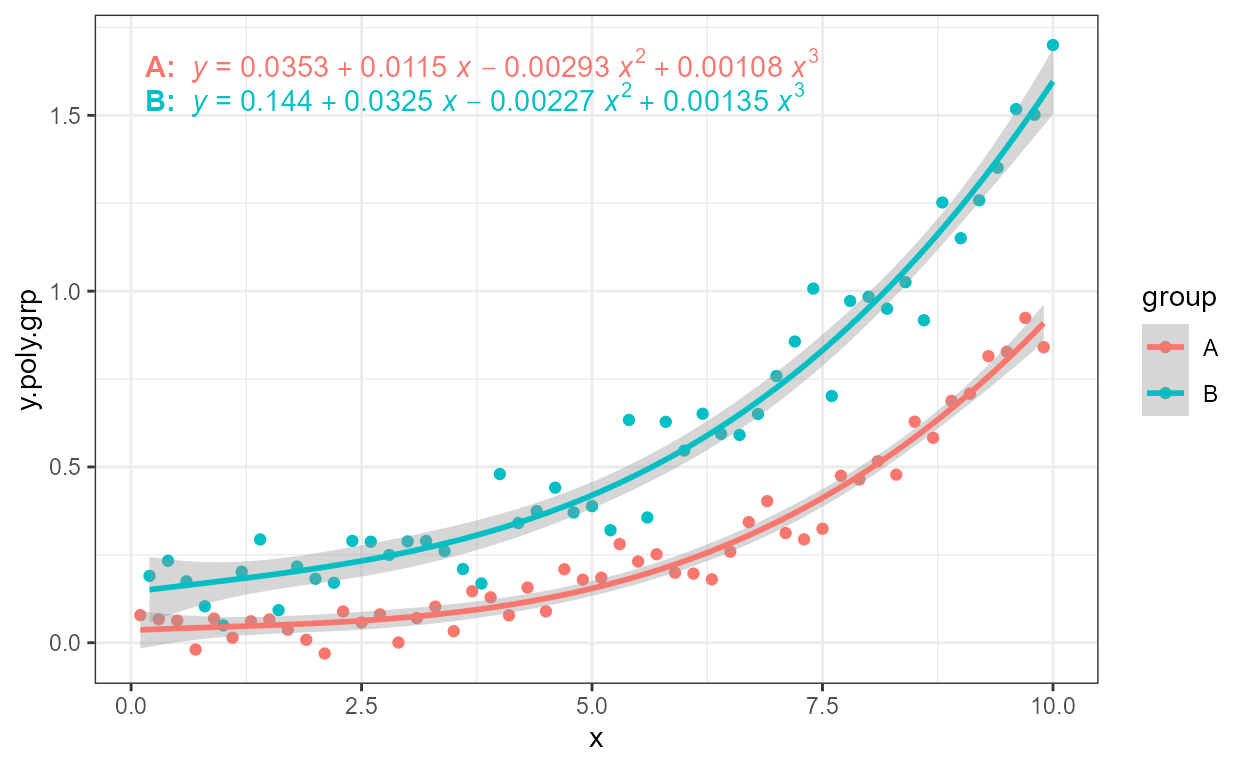
In stat_poly_eq(), similarly as in
stat_smooth() from ‘ggplot2’, the confidence band’s P-value and the computation of the band
boundaries are controlled by parameters level and
se, respectively, while n controls the number
of points at which the prediction is computed and parameter
fullrange determines the range over which the prediction is
computed. Parameter limit.to, not available in
stat_smooth, adds finer control of this range.
Examples of the use of stat_poly_line() and
stat_poly_eq() with other model fitting functions and
formulas are available as articles at the ‘ggpmisc’ web
site.
stat_ma_eq() and stat_ma_line()
Package ‘lmodel2’ implements Model II fits for major axis (MA),
standard major axis (SMA) and ranged major axis (RMA) regression for
linear relationships. These approaches of regression are used when both
variables are subject to random variation and the intention is not to
estimate y from x but instead to describe the slope of
the relationship between them. A typical example in biology are
allometric relationships. Rather frequently, OLS linear model fits are
used in cases where Model II regression would be preferable. **MA and
SMA models can be also fit with stat_poly_line() and
stat_poly_eq() using functions from package ‘smatr’.
In the figure above we see that the ordinary least squares (OLS)
linear regression of y on x and x on
y differ. Major axis regression provides an estimate of the
slope that is independent of the direction of the relationship relation.
R^2 remains the same in all cases, and
with major axis regression while the coefficient estimates in the
equation depend on the orientation, they correspond to
exactly the same line.
The message issued at the R console in an interactive R session is:
'stat_ma_eq' labels (1 rows): eq, R2, P, theta, n, grp, method.As described above for stat_correlation() and
stat_poly_eq(), the message informs about available short
names for labels that can be mapped to the label aesthetic
with use_label() or f_use_label().
ggplot(my.data, aes(x, y.sd3)) +
geom_point() +
stat_ma_line() +
stat_ma_eq(mapping = use_label("eq"))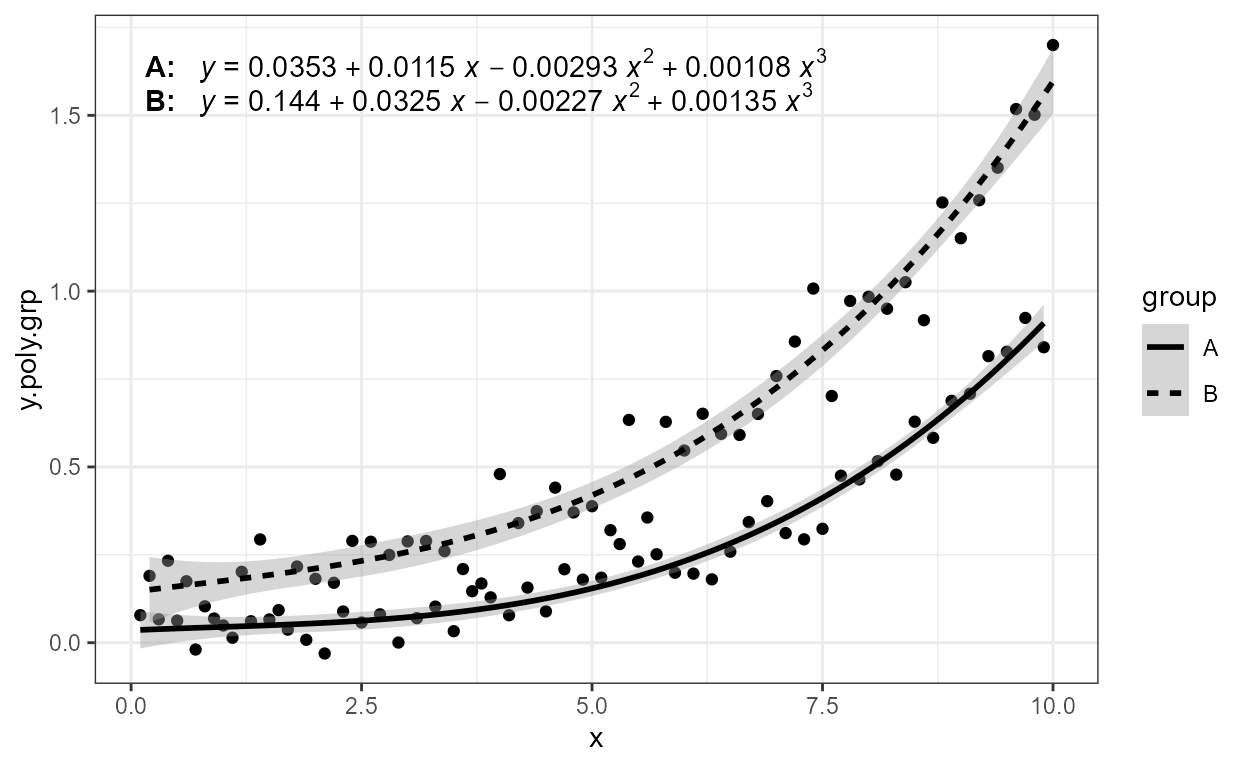
ggplot(my.data, aes(x, y.sd3)) +
geom_point() +
stat_ma_line(color = "blue") +
stat_ma_eq(mapping = use_label("R2", "eq"),
color = "blue") +
stat_ma_line(color = "red",
orientation = "y",
linetype = "dashed") +
stat_ma_eq(mapping = use_label("R2", "eq"),
color = "red",
orientation = "y",
label.y = 0.9)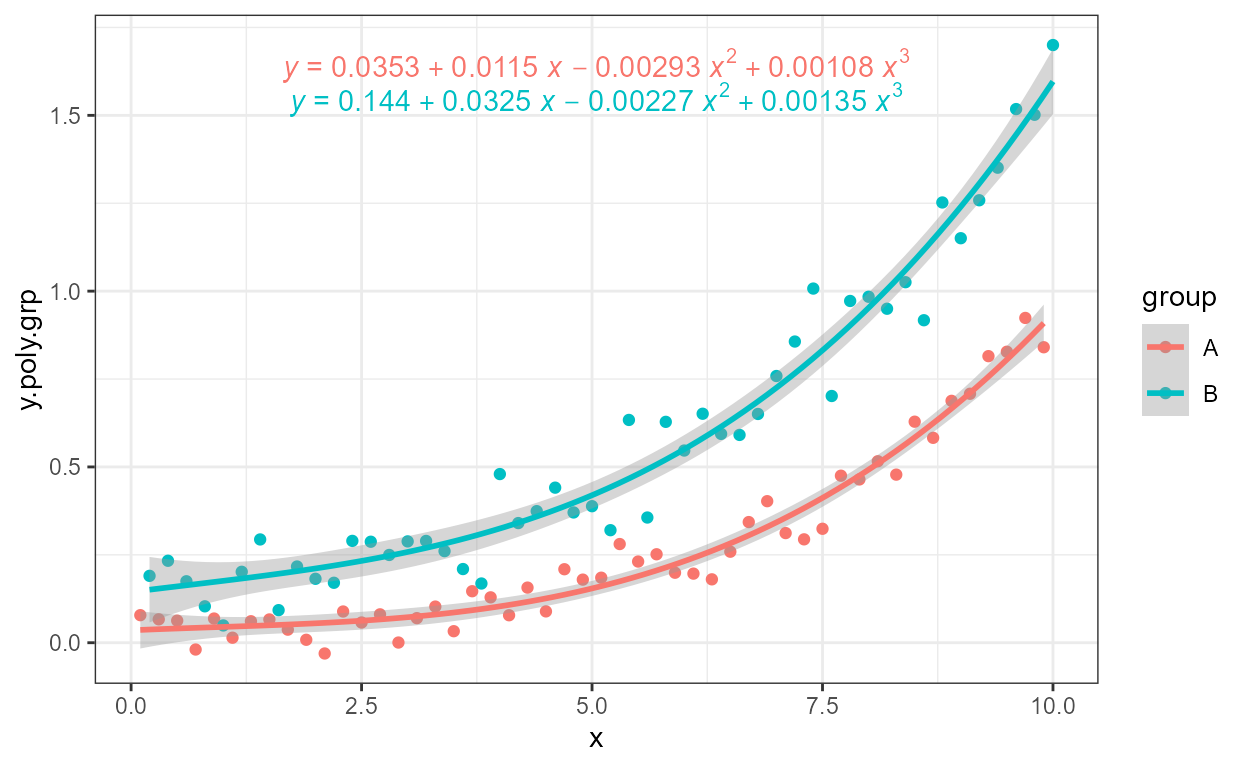
MA and SMA are models describing strictly linear relationships.
Orthogonal least squares can be used to fit polynomials, and other
models and is supported by stat_poly_line() and
`stat_poly_eq().
Additional examples of the use of stat_ma_line() and
stat_ma_equation() and alternatives are available in
articles at the
‘ggpmisc’ web site.
stat_quant_eq(), stat_quant_line() and stat_quant_band()
Package ‘quantreg’ implements quantile regression for multiple types
of models: linear models with function quantreg::rq(),
non-linear models with function quantreg::nlreg(), and
additive models with function quantreg::rqss(). Each of
these functions supports different methods of estimation which can be
passed through parameter method.args or more easily using a
character string such as "rq:br" argument to parameter
method of the statistic, where quantreg::rq()
is the model fit function and "br" the argument passed to
the method parameter of quantreg::rq(). As
with the statistics for polynomials described in the previous section,
all the statistics described in the current section support linear
models while stat_quant_line() and
stat_quant_band() also support additive models. (Support
for quantreg::nlreg() is not yet implemented.)
In the case of quantile regression it is frequently the case that
multiple quantile regressions are fitted simultaneously. This case is
not supported by stat_poly_eq() but instead by
stat_quant_eq(). This statistics is similar to
stat_poly_eq() both in behaviour and parameters. It
supports quantile regression of y on x or x
on y fitted with function quantreg::rq.
The statistic stat_quant_line() is substitute for
ggplot2::stat_quantile() with enhancements. It adds a layer
similar to that created by stat_poly_line() including
confidence bands for quantile regression, by default for p =
0.95. It has the an interface and default arguments consitant with
stat_quant_eq(), and supports both x and
y as explanatory variable in formula and also
orientation. Confidence intervals for the fits to
individual quantiles fulfil the same purpose as in OLS fits: providing a
boundary for the estimated line computed for each individual
quantile. They are not shown by default, unless a single quantile is
passed as argument, but can be enabled with se = TRUE and
disabled with se = FALSE.
The statistic stat_quant_band() creates a line plus band
plot that is, with the quantiles used by default similar to a boxplot in
its interpretation. In this case, the band informs about the local
spread of the observations in the same way as the box in box
plots does. Which three quantiles are used can be set through parameter
quantiles but in contrast to stat_quant_line()
and stat_quant_eq() only a vector of three quantiles is
accepted.
Similarly to ggplot2::stat_quantiles(),
stat_quant_eq() and stat_quant_line() accept a
numeric vector as argument to quantiles and
output one equation or one line per group and quantile. Statistic
stat_quant_eq() also returns variable
grp.label containing by default a character string
indicating the value of the quantile, and if a variable is mapped to the
pseudo aesthetic grp.label, its value is prepended to the
quantiles.
With default quantiles, 0.25, 0.50, 0.75, equivalent to those used for the box of box plots, a plot with a line for median regression and a band highlighting the space between the quartiles is plotted.
ggplot(my.data, aes(x, y.poly)) +
geom_point() +
stat_quant_band(formula = y ~ poly(x, 2))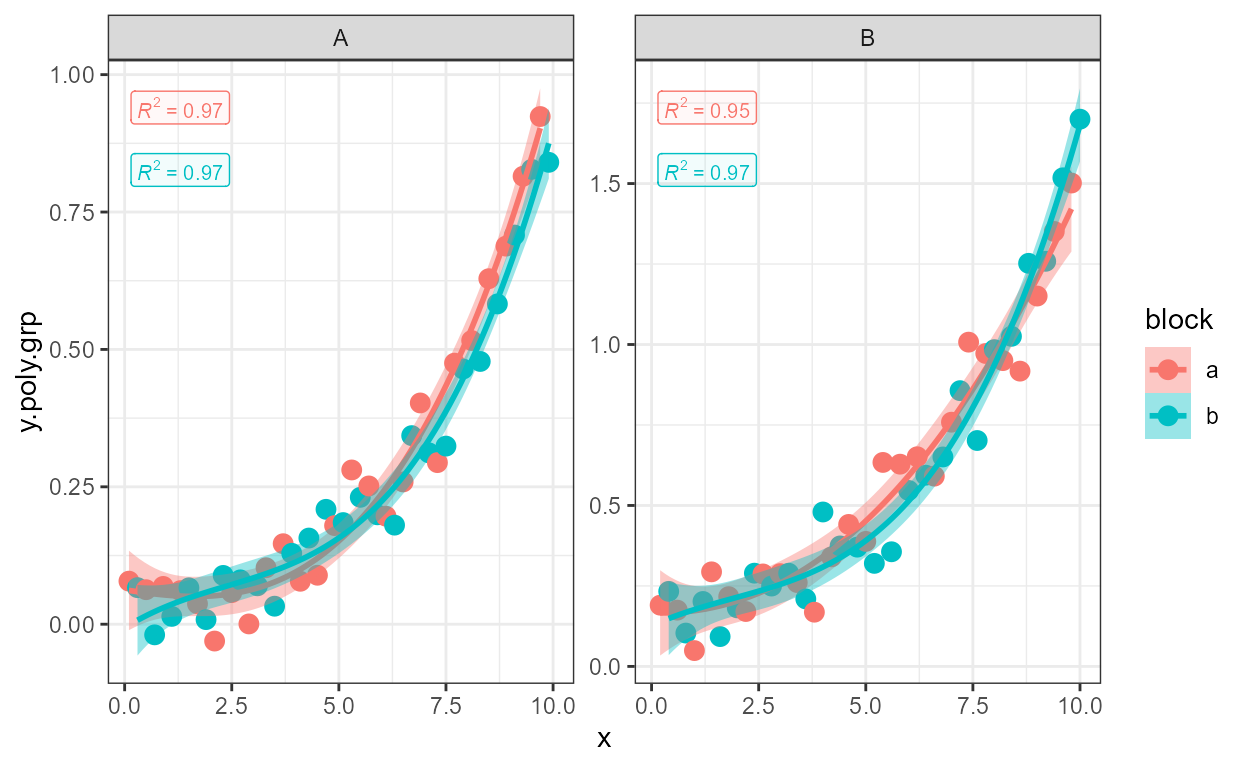
Overriding the values for quantiles we find a boundary
containing 90% of the observations. We add the observations as points
after the lines so that points are plotted on top of the lines.
ggplot(my.data, aes(x, y.poly)) +
stat_quant_line(formula = y ~ poly(x, 2),
quantiles = c(0.05, 0.95)) +
geom_point()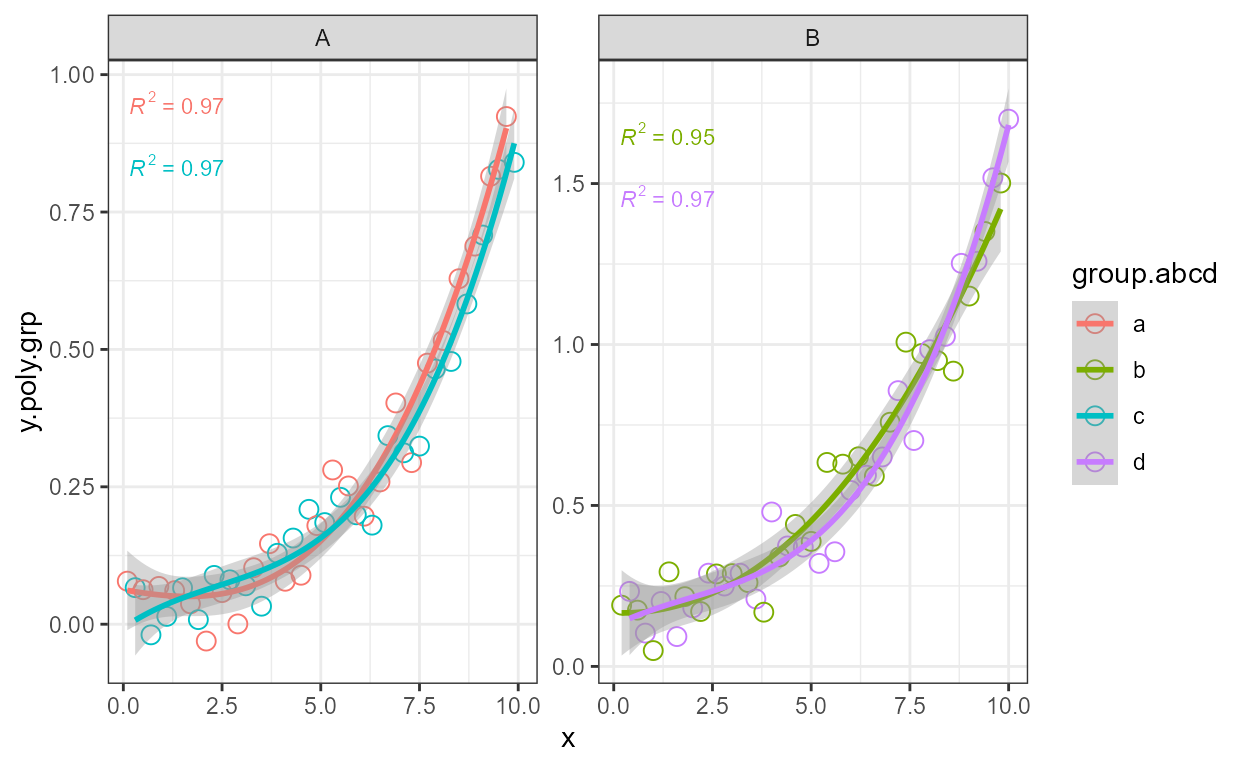
A line for the quantile regression plus a confidence band for it is the default for a single quantile.
ggplot(my.data, aes(x, y.poly)) +
geom_point() +
stat_quant_line(formula = y ~ poly(x, 2),
quantiles = 0.5)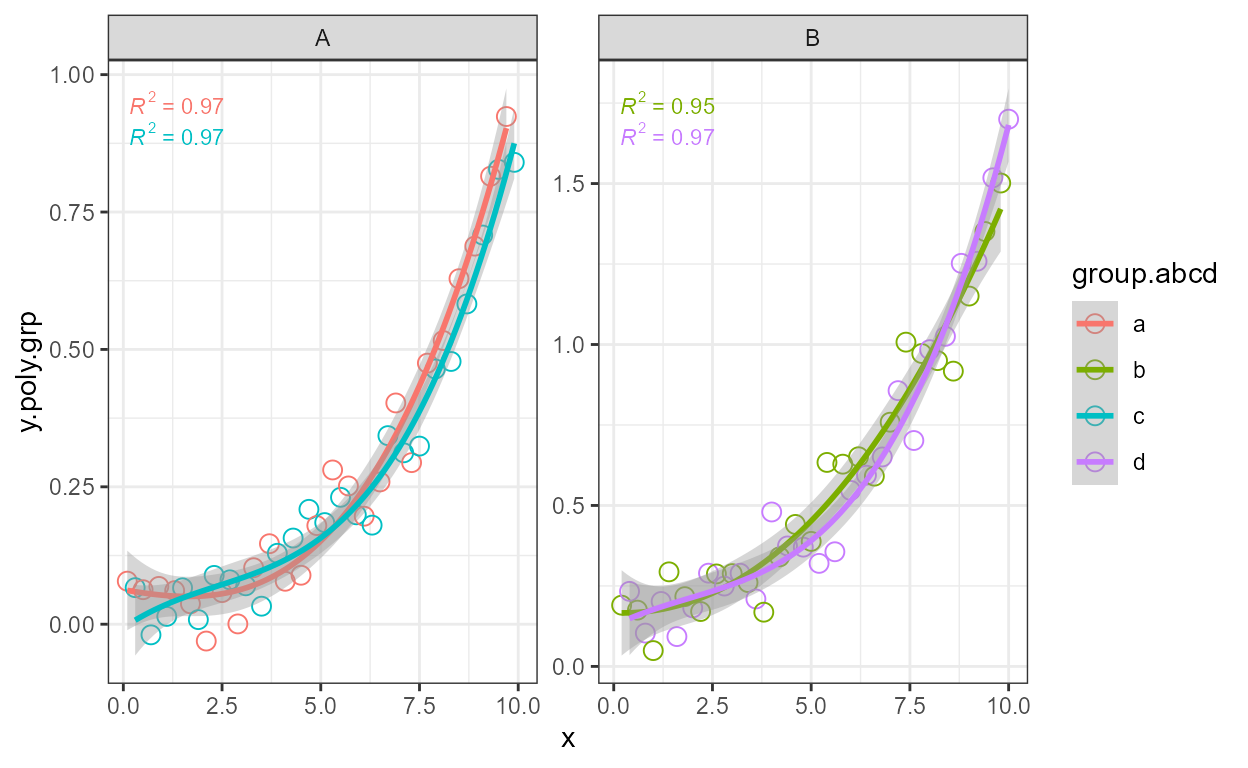
stat_quant_eq() assembles the fitted equations that are
combined and mapped to the label aesthetic using
f_use_label(). A message at the R console shows the short
names of the formatted character strings available for use in
use_label() or f_use_label() as:
'stat_quant_eq' labels (3 rows): eq, AIC, rho, n, grp, qtl, method.
ggplot(my.data, aes(x, y.poly)) +
geom_point() +
stat_quant_band(formula = formula,
color = "black",
fill = "grey60") +
stat_quant_eq(f_use_label("qtl", "eq", format = "%s*\": \"*%s"),
formula = formula) +
theme_classic()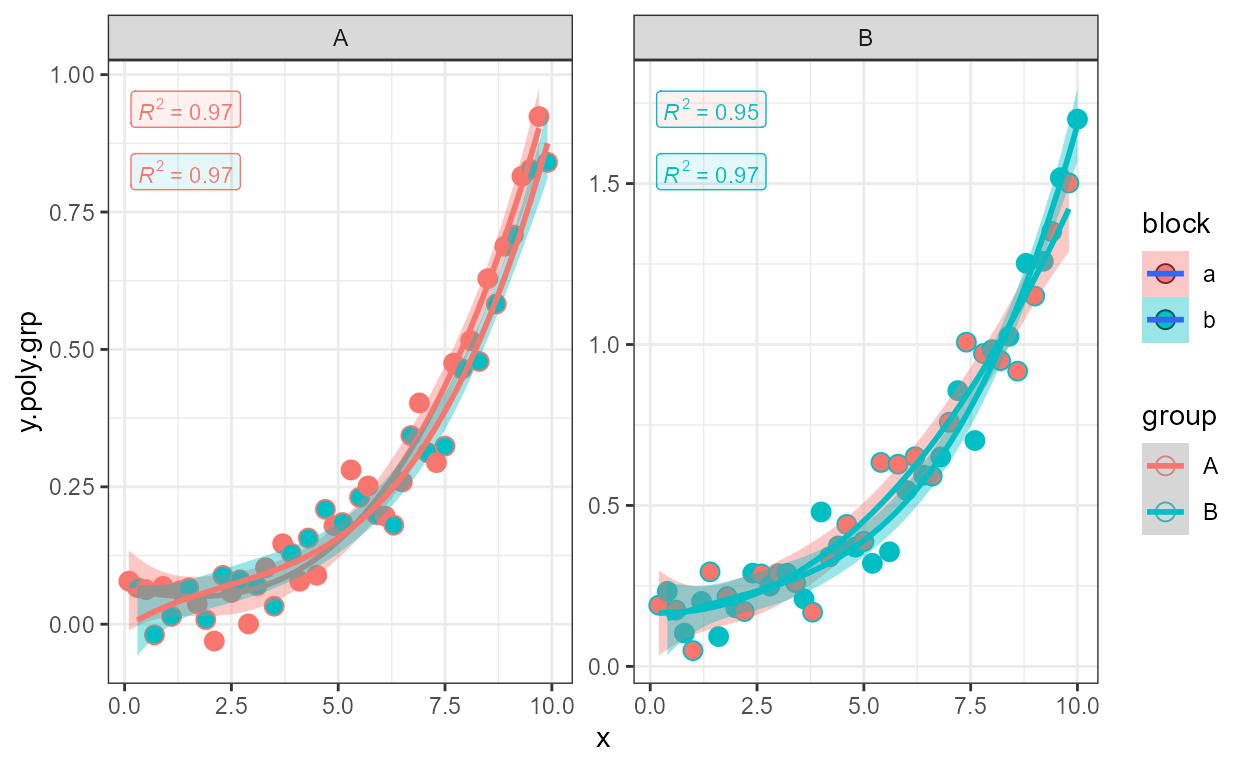
Grouping and faceting are supported by stat_quant_eq(),
stat_quant_line() and stat_quant_band() as
described above for the other statistics described above. The main
difference is that for each data group more than one model can be fit
with one prediction line and one equation for each model. The positions
are as in other cases computed automatically or set manually.
ggplot(my.data,
aes(x, y.poly.grp, group = group, grp.label = group)) +
geom_point() +
stat_quant_line(formula = formula) +
stat_quant_eq(f_use_label("grp", "qtl", "eq",
format = "%s*\" \"*%s*\": \"*%s"),
size = 2.7,
formula = formula)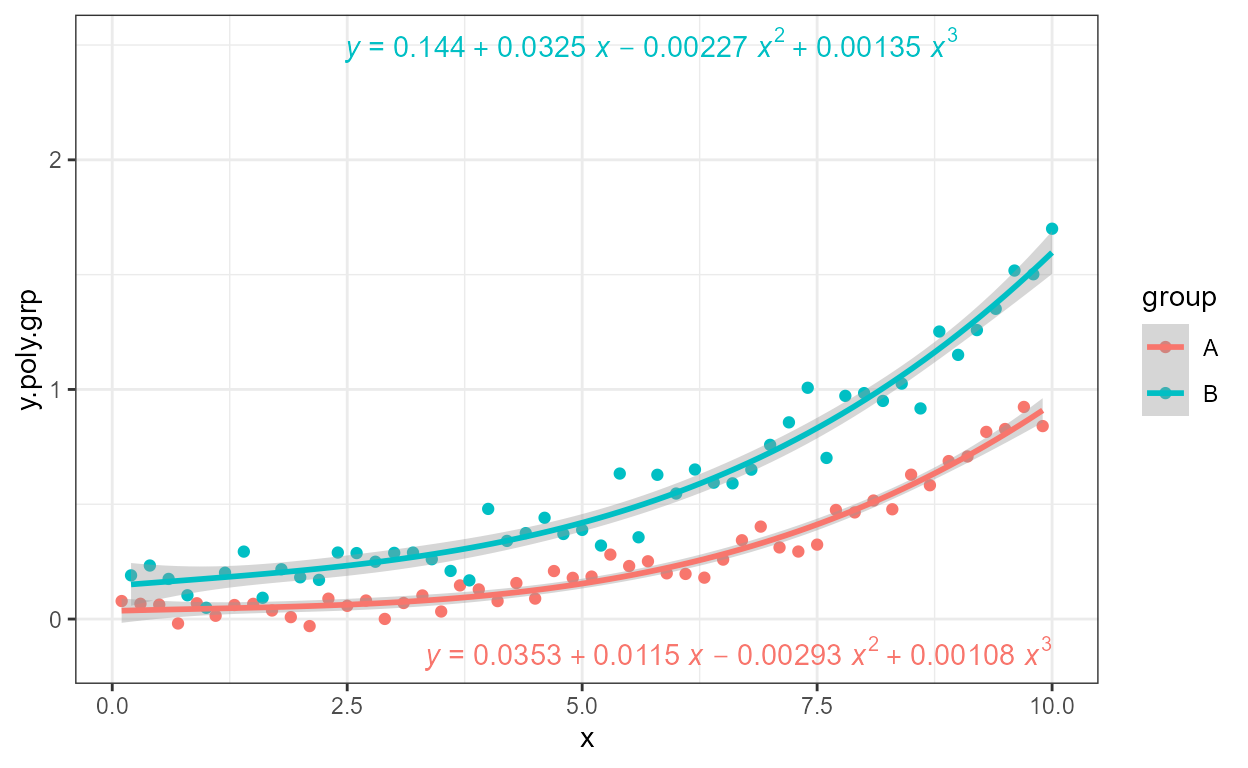
Grouping can be combined with a group label by mapping in
aes() a character variable to grp.label.
ggplot(my.data,
aes(x, y.poly.grp, group = group, linetype = group,
shape = group, grp.label = group)) +
geom_point() +
stat_quant_line(formula = formula,
quantiles = c(0.05, 0.95),
color = "black") +
stat_quant_eq(aes(label =
after_stat(
paste(grp.label, "*\", \"*",
qtl.label, "*\": \"*",
eq.label,
sep = ""))),
size = 2.7,
formula = formula,
quantiles = c(0.05, 0.95)) +
theme_classic()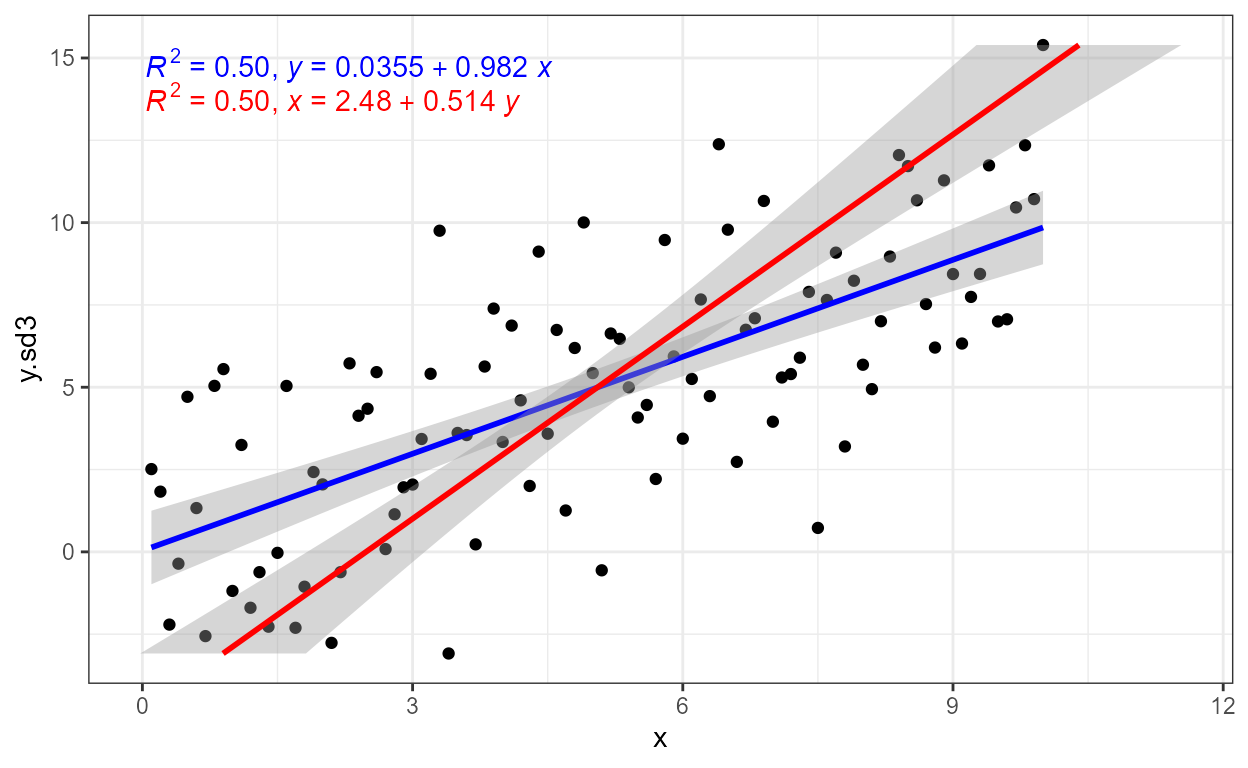
In some cases double quantile regression is an informative
method to assess reciprocal constraints. For this a fit of x on
y and one of y on x in the same plot are
computed for a large quantile. As is the case for model fitting
functions themselves this is simply indicated by the model passed as
argument to formula, or consistently with
ggplot2::stat_smooth() through parameter
orientation.
ggplot(my.data, aes(x, y.sd3)) +
geom_point() +
stat_quant_line(formula = y ~ x,
color = "blue",
quantiles = 0.05,
se = FALSE) +
stat_quant_eq(mapping = use_label("eq"),
formula = y ~ x,
color = "blue",
quantiles = 0.05) +
stat_quant_line(formula = x ~ y,
color = "red",
quantiles = 0.95,
se = FALSE) +
stat_quant_eq(mapping = use_label("eq"),
formula = x ~ y,
color = "red",
quantiles = 0.95,
label.y = 0.9)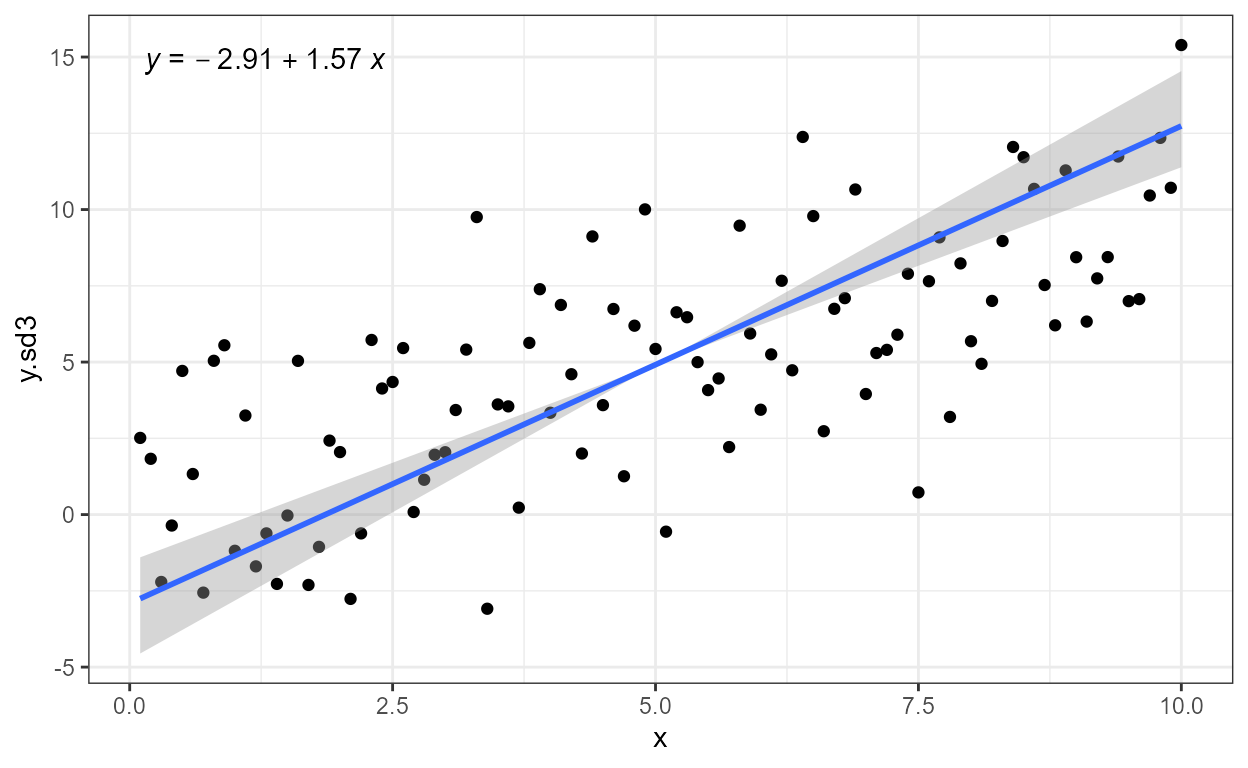
Please, see examples in the previous sections, as they can be
adapted. Examples of the use of stat_quant_line(),
stat_quant_band() and stat_quant_eq() with
other model fitting functions and formulas are available as articles at
the ‘ggpmisc’ web
site.
stat_distrmix_eq(), stat_distrmix_line() and stat_distrmix_area()
Package ‘mixtools’ implements the fitting of univariate mixture
models. Currently, ‘ggpmisc’ only supports fitting of mixtures of
univariate Normals with function normalmixEM(). Fitting of
a single Normal distribution is also supported. The fit is done
numerically based on maximum likelihood with an EM or ECM algorithm.
In the case of density distributions the position of quantiles,
especially near the tails is a frequent addition to plots. These
positions are computed in stat_distrmix_line() and
stat_distrmix_area() from the cumulated density (CDF) both
for the mix and for the individual components. The DF, the CDF and
positions of quantiles are all returned.
In all cases the distributions are extended to encompass their whole
range. The returned data cover With the default
fullrange = TRUE this whole range, possibly extended to the
limits of the scale if broader. In contrast, with
fullrange = FALSE the distributions are trimmed to the
range of the data.
Messages listing the available variables and labels are issued to the R console in interactive R sessions. In this case:
'stat_distrmix_line' variables (600 rows): x, component, density, quant.splits, flipped_aes.
'stat_distrmix_eq' labels (1 rows): eq, n, method.
ggplot(faithful, aes(x = waiting)) +
stat_distrmix_line() +
stat_distrmix_eq() +
scale_x_continuous(limits = c(0, 110))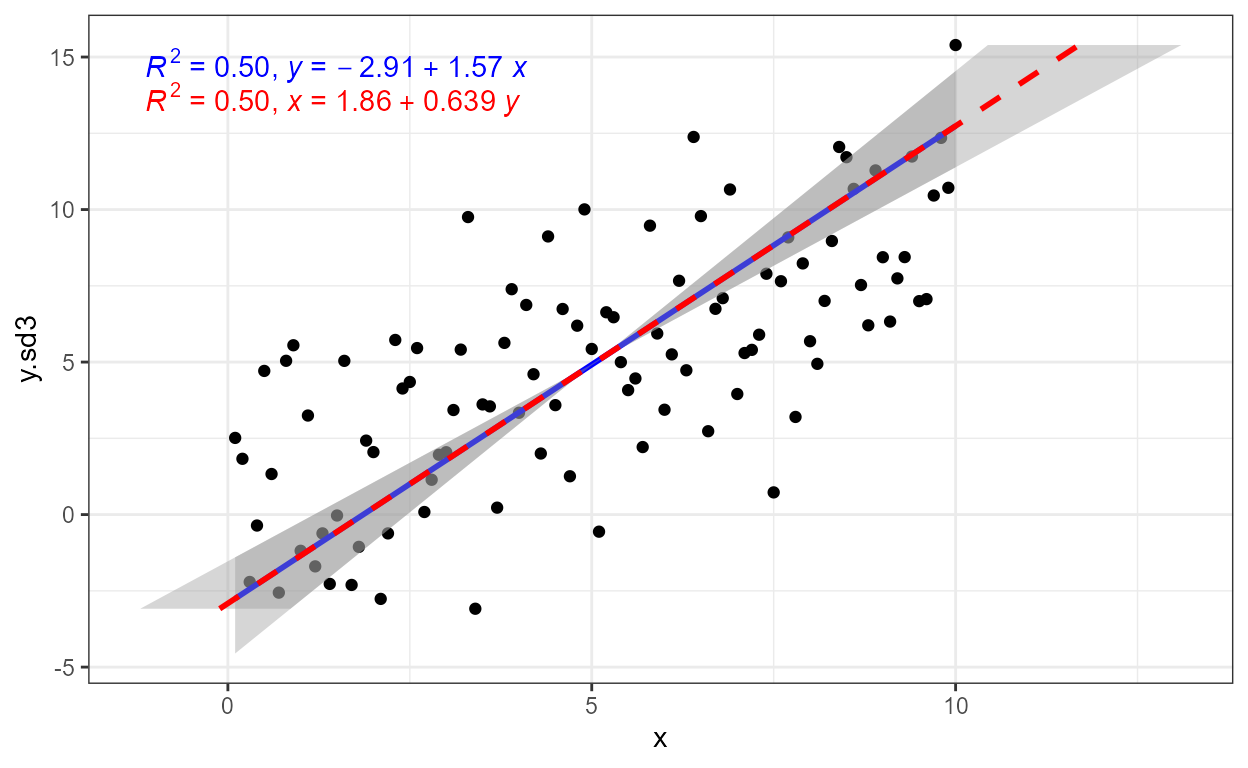
Orientation is set automatically based on the mapping of the data to
the x or the y aesthetic.
ggplot(faithful, aes(y = waiting)) +
stat_distrmix_line() +
stat_distrmix_eq(label.x = "right", label.y = "bottom")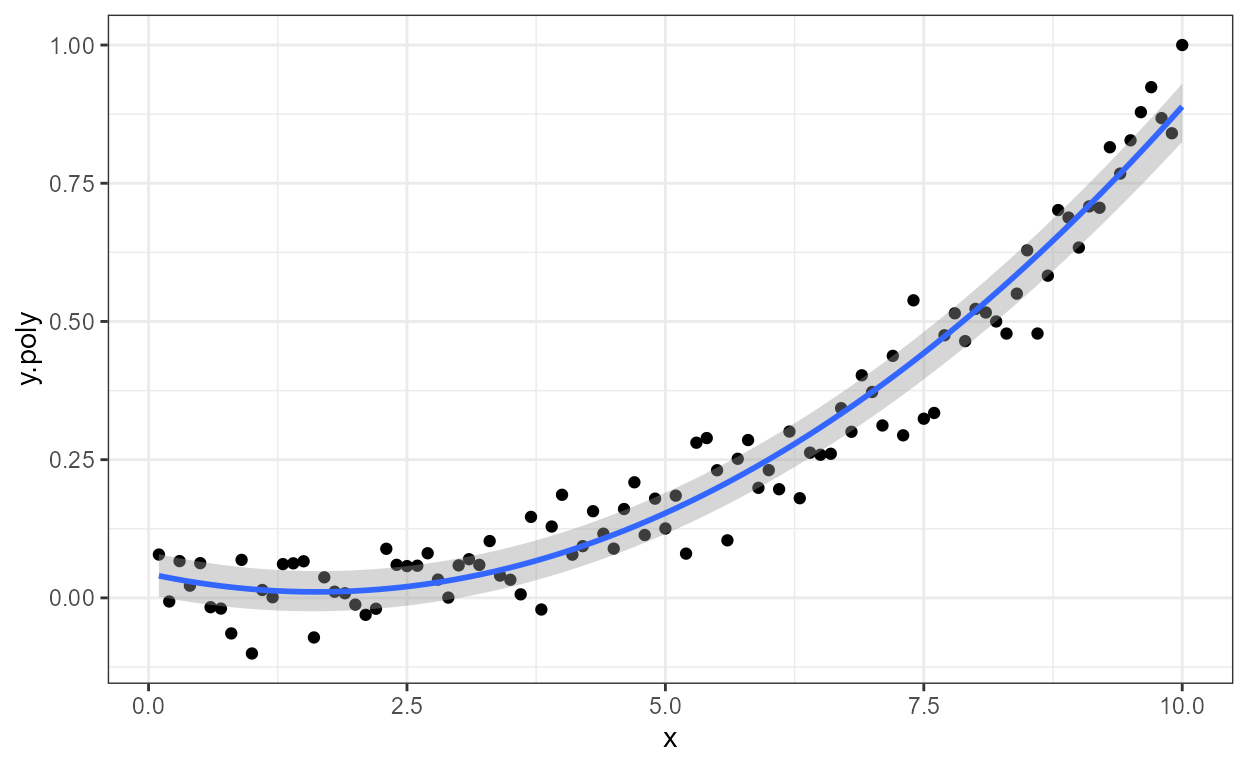
The default for stat_distrmix_line() is to return
densities for components and their sum, below only the sum is returned.
With "members" only the components would have been
returned.
ggplot(faithful, aes(x = waiting)) +
stat_distrmix_line(components = "sum") +
stat_distrmix_eq(label.x = "middle", label.y = "bottom")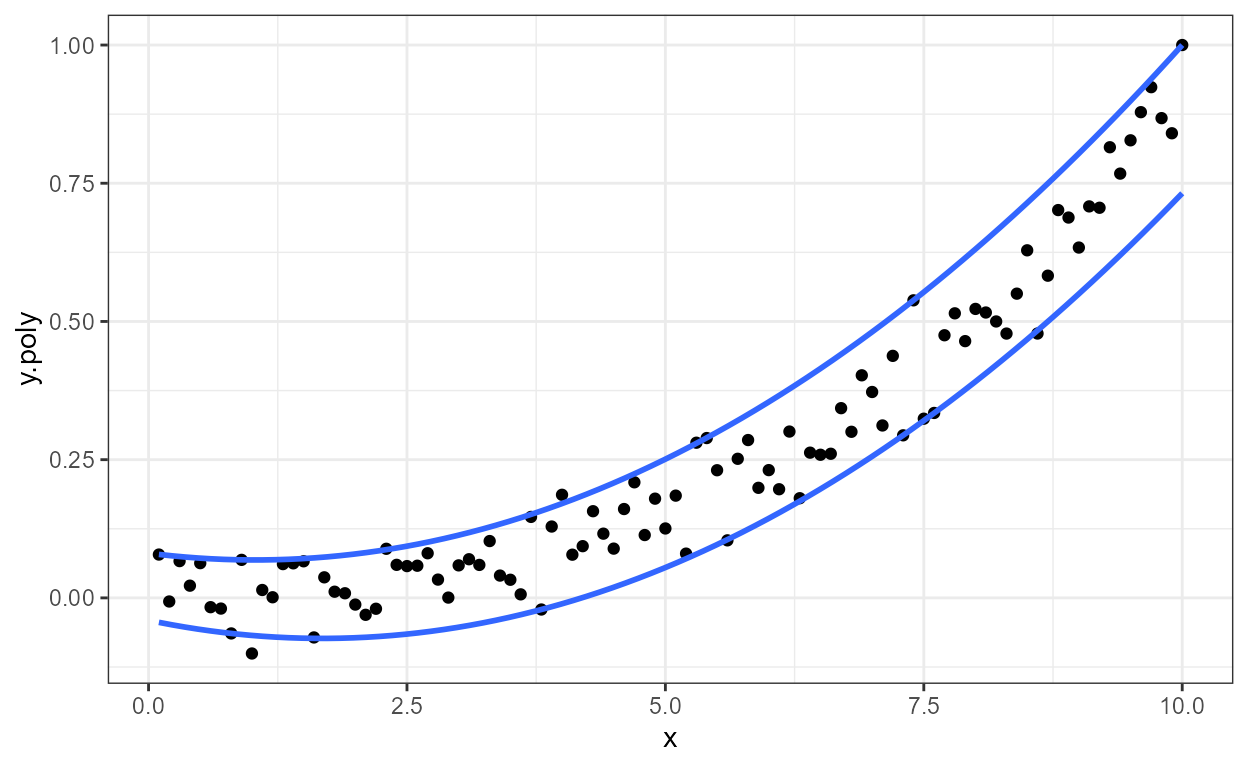
stat_distrmix_area() returns by default only the sum of
the components and plots it with geom_area().
ggplot(faithful, aes(x = waiting)) +
stat_distrmix_area() +
stat_distrmix_eq(colour = "white",
label.x = "middle", label.y = 0.08)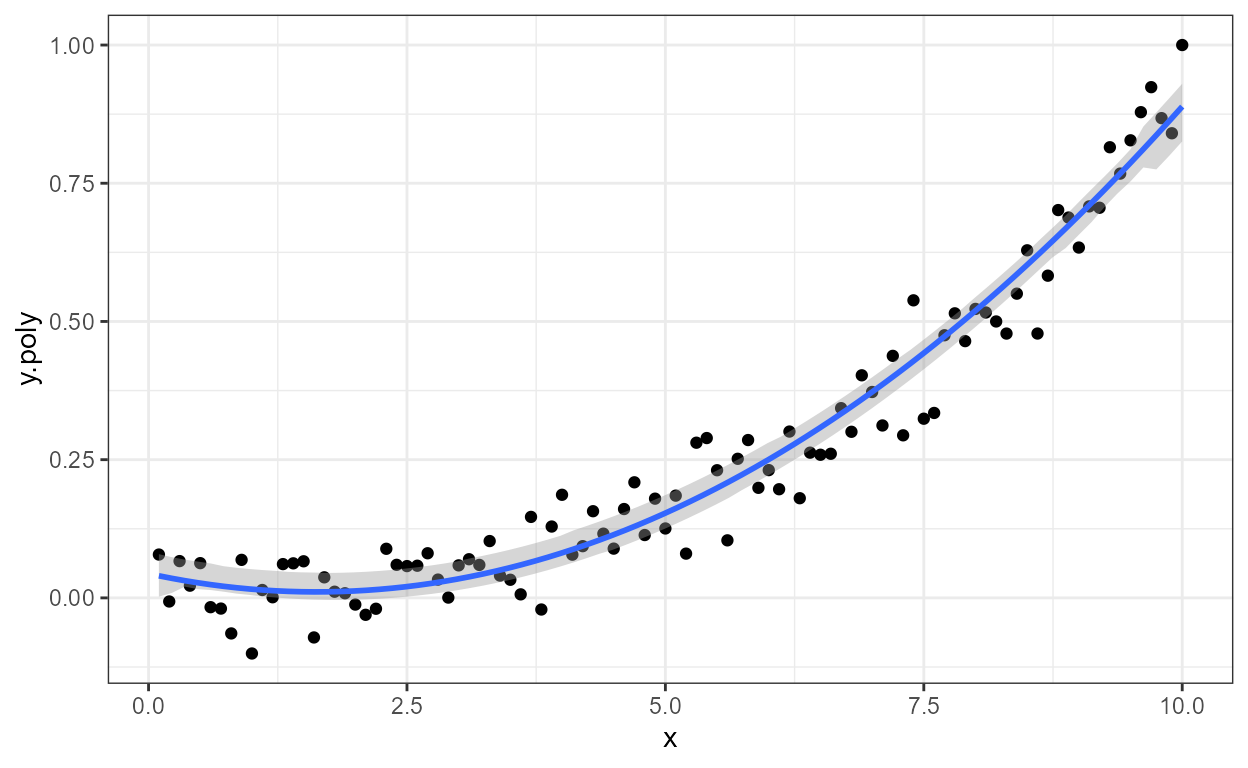
The position of the quantiles can be highlighted in a single plot
layer by mapping the returned integer variable quant.splits
to the fill aesthetic.
ggplot(faithful, aes(x = waiting)) +
stat_distrmix_area(aes(fill = after_stat(quant.splits != 2)),
colour = "black", outline.type = "upper",
quantiles = c(0.025, 0.975),
show.legend = FALSE) +
scale_fill_manual(values = c("grey80", "grey20"))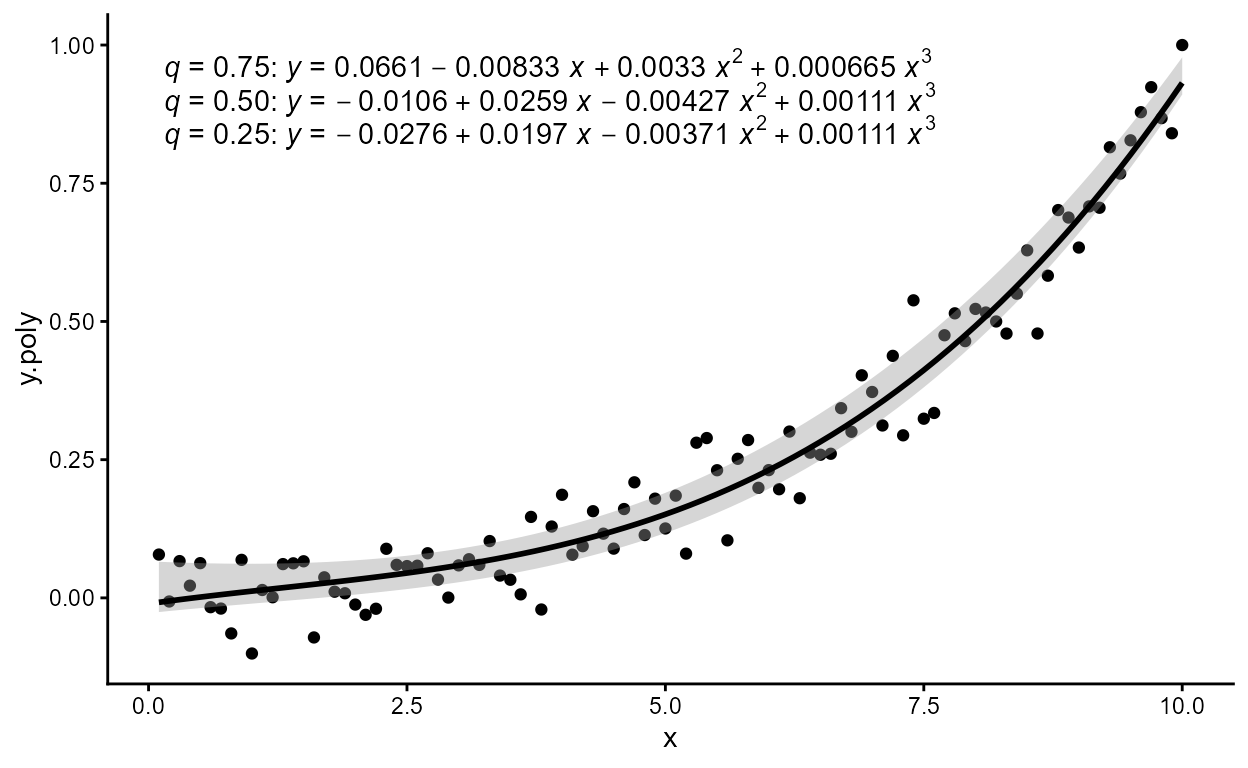
stat_multcomp
Multiple comparisons are frequently used when the effect of different
levels of a factor are individually of interest. Function
stat_multcomp() computes adjusted P-values for
pairwise comparison using Tukey or Dunnet contrasts with function
glht() from package ‘multcomp’.
The default is Tukey contrasts (all pairs) using Tukey’s HSD (honestly significant difference) approach. The message displayed at the R console is:
'stat_multcomp' available labels (6 rows): stars, P, delta, t, default.
ggplot(mpg, aes(factor(cyl), hwy)) +
geom_boxplot(width = 0.33) +
stat_multcomp() +
expand_limits(y = 0)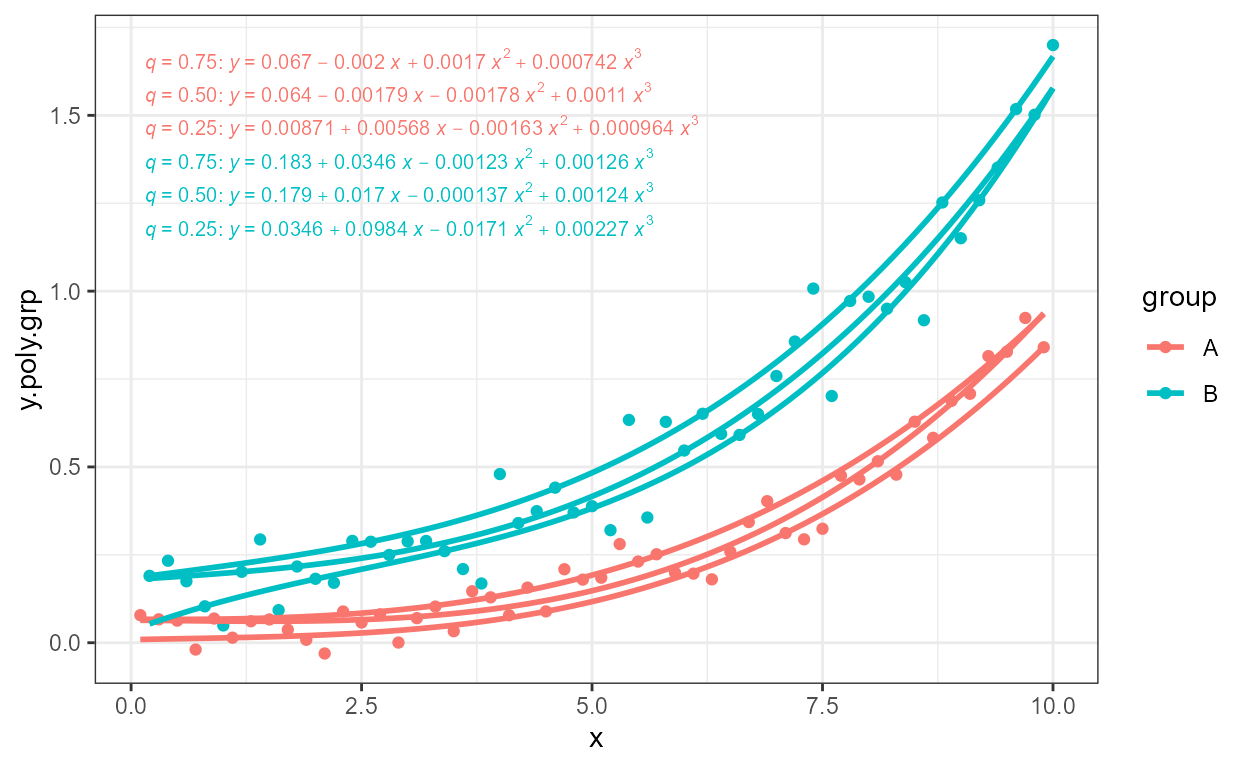
To complement the examples in the documentation of the function, below are examples that override several defaults.
Alternatives to the default “tag” values used to describe the
adjustment method can be obtained with arguments passed to parameter
adj.method.tag. In the first example the abbreviation is
three characters long, instead of the default of four.
# position of contrasts' bars (manual)
ggplot(mpg, aes(factor(cyl), hwy)) +
geom_boxplot(width = 0.33) +
stat_multcomp(p.adjust.method = "holm",
adj.method.tag = 3,
size = 2.75) +
expand_limits(y = 0)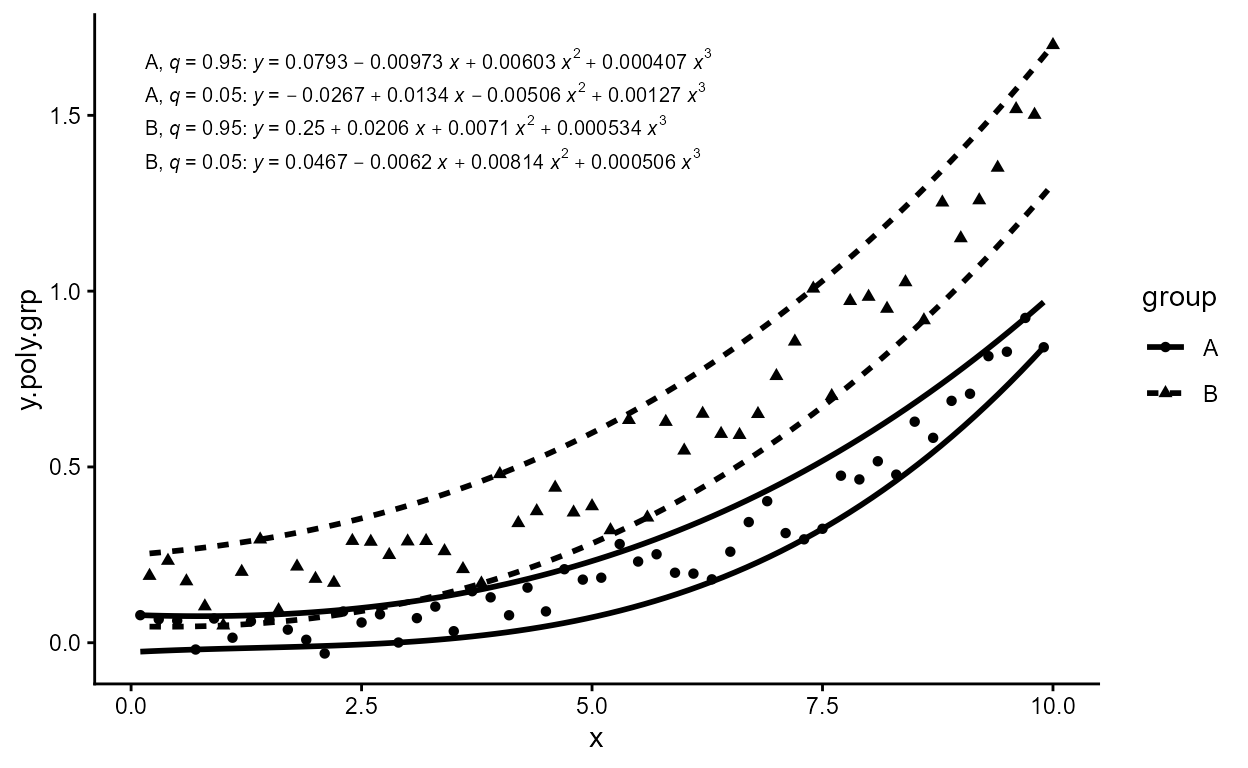
Here we use a negative value to use an abbreviation of the word “adjusted” to three characters.
# position of contrasts' bars (manual)
ggplot(mpg, aes(factor(cyl), hwy)) +
geom_boxplot(width = 0.33) +
stat_multcomp(p.adjust.method = "holm",
adj.method.tag = -3,
size = 2.75) +
expand_limits(y = 0)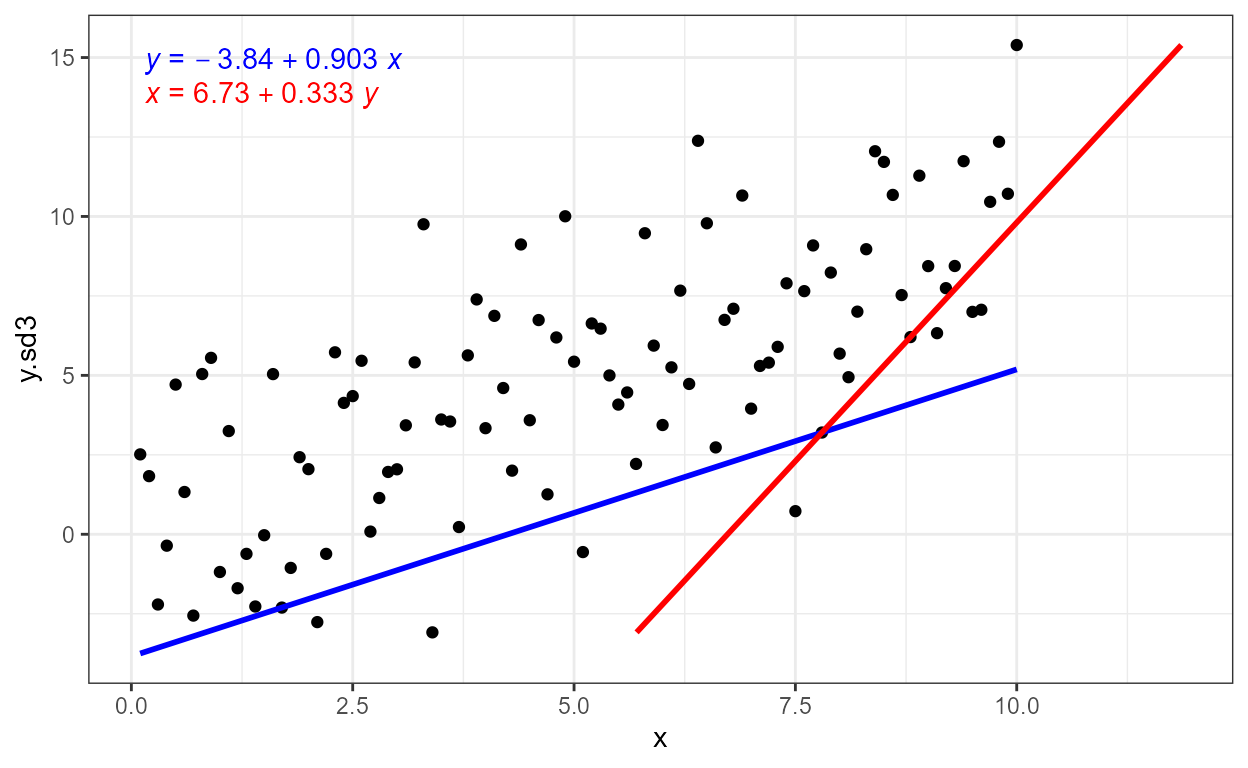
A character string passed as argument is used as is, here to set the tag in Spanish.
# position of contrasts' bars (manual)
ggplot(mpg, aes(factor(cyl), hwy)) +
geom_boxplot(width = 0.33) +
stat_multcomp(adj.method.tag = "ajustada",
size = 2.75) +
expand_limits(y = 0)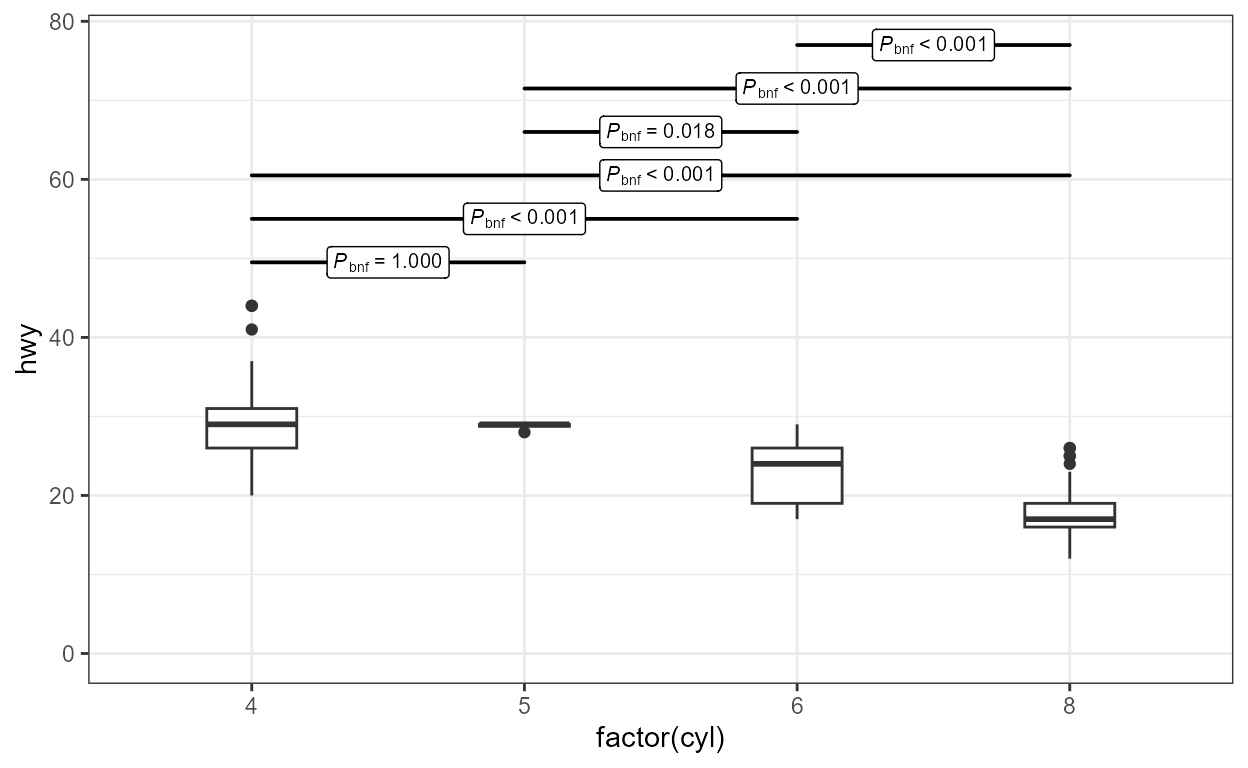
A numeric vector passed to label.y can be used to
manually set the location of each label along the y axis.
# position of contrasts' bars (manual)
ggplot(mpg, aes(factor(cyl), hwy)) +
geom_boxplot(width = 0.33) +
stat_multcomp(label.y = c(7, 4, 1),
contrasts = "Dunnet",
size = 2.75) +
expand_limits(y = 0)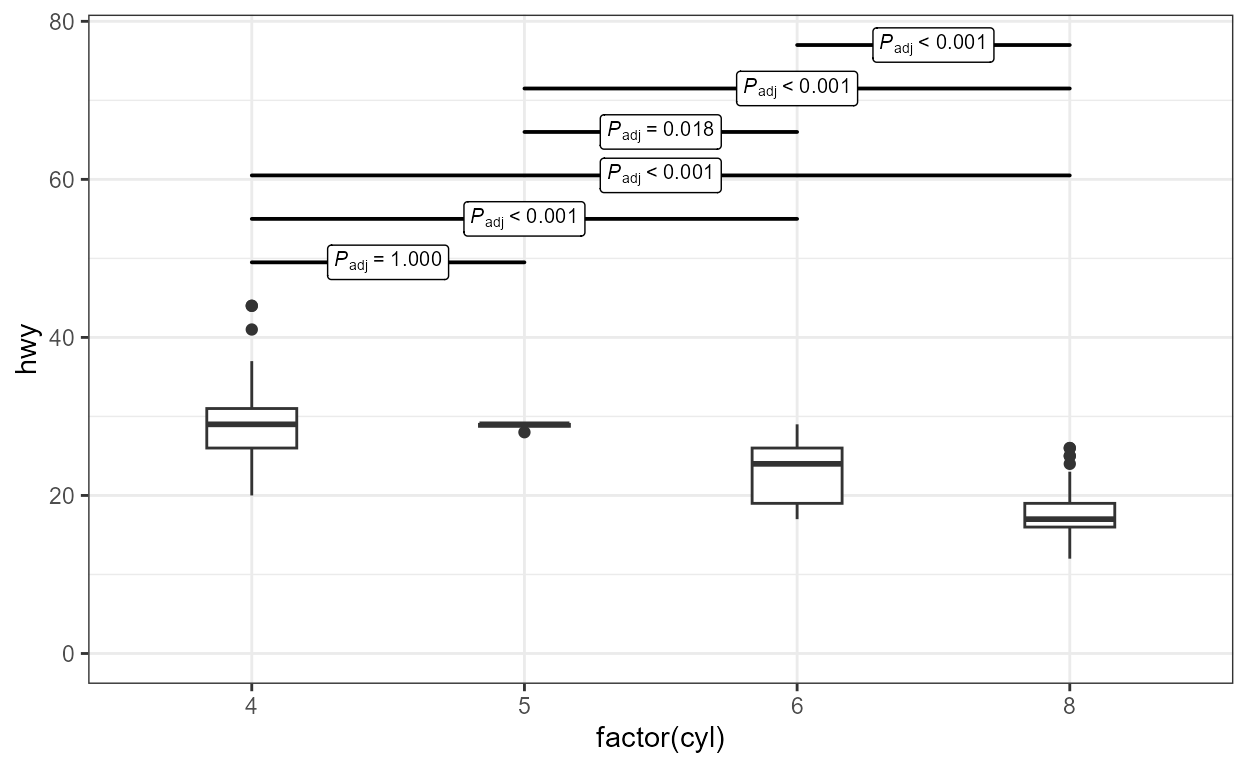
ggplot(mpg, aes(factor(cyl), hwy)) +
geom_boxplot(width = 0.33) +
stat_multcomp(label.y =
seq(from = 15,
by = -3,
length.out = 6),
size = 2.5) +
expand_limits(y = 0)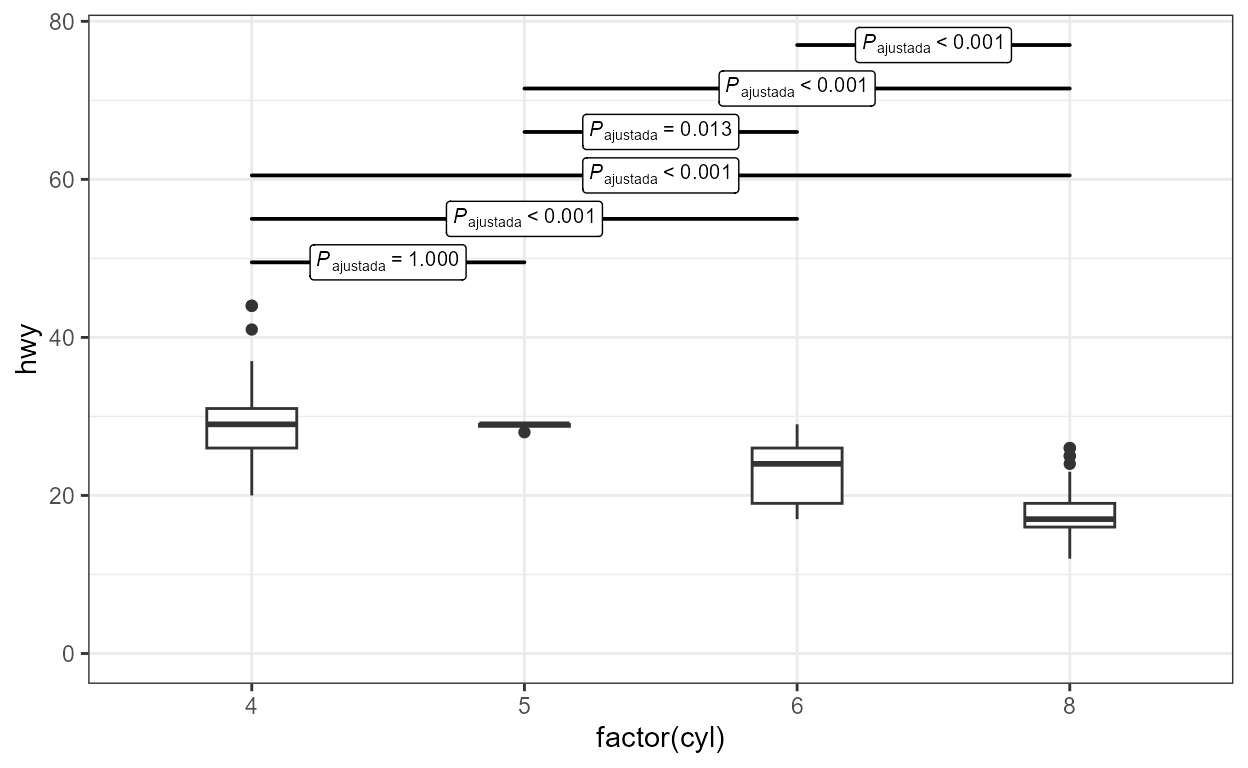
We can pre-compute the numeric vector to achieve special positioning, in this case, next to each observation.
means <-
aggregate(mpg$hwy,
by = list(mpg$cyl),
FUN = mean,
na.rm = TRUE)[["x"]]
ggplot(mpg, aes(factor(cyl), hwy)) +
stat_summary(fun.data = mean_se) +
stat_multcomp(label.type = "letters",
label.y = c(18, means), # 18 is for critical P label
position = position_nudge(x = 0.1))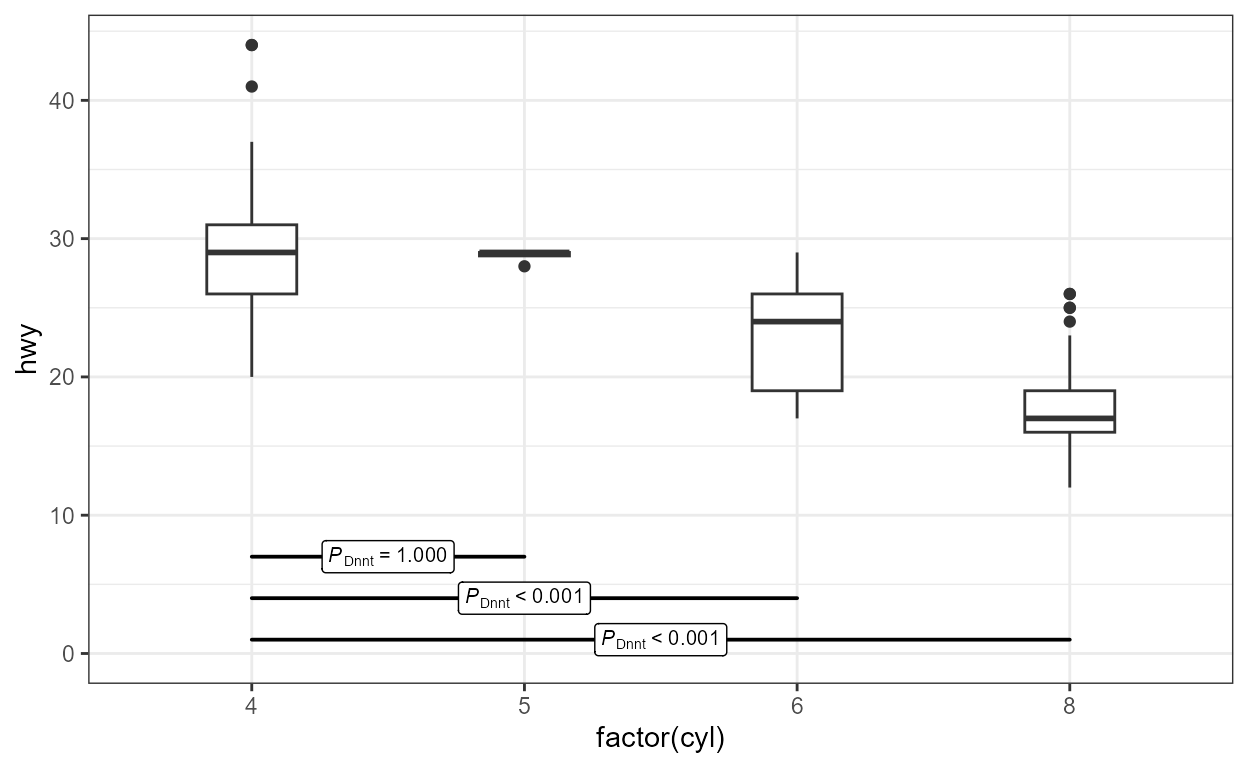
We can override the default use of geom_text() and also
remove the P critical label.
# Using other geometries
ggplot(mpg, aes(factor(cyl), hwy)) +
geom_boxplot(width = 0.33) +
stat_multcomp(label.type = "letters",
adj.method.tag = FALSE,
geom = "label")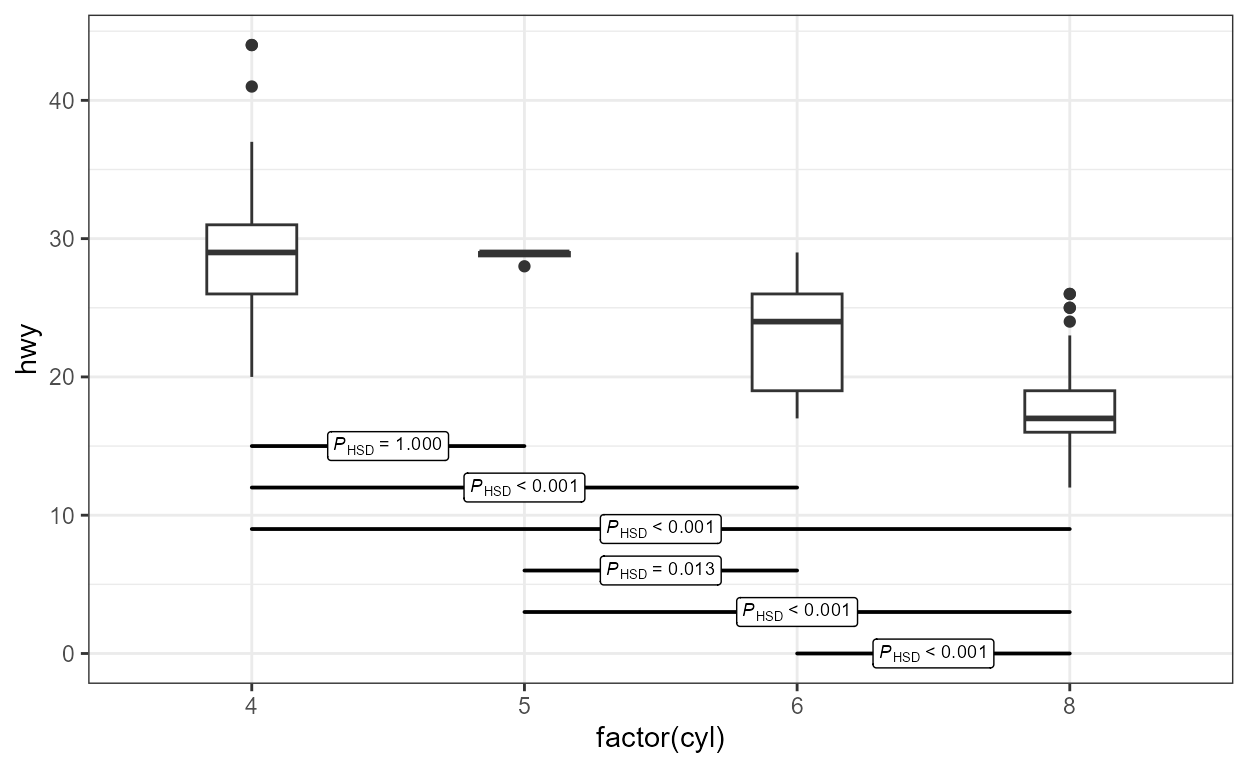
Orientation is set automatically based on the mapping of a factor to
either the x or y aesthetic. Currently,
label.type = "bars" is not supported in flipped plots like
this one.
# Using other geometries
ggplot(mpg, aes(hwy, factor(cyl))) +
geom_boxplot(width = 0.33) +
stat_multcomp(label.type = "letters",
adj.method.tag = FALSE,
geom = "label")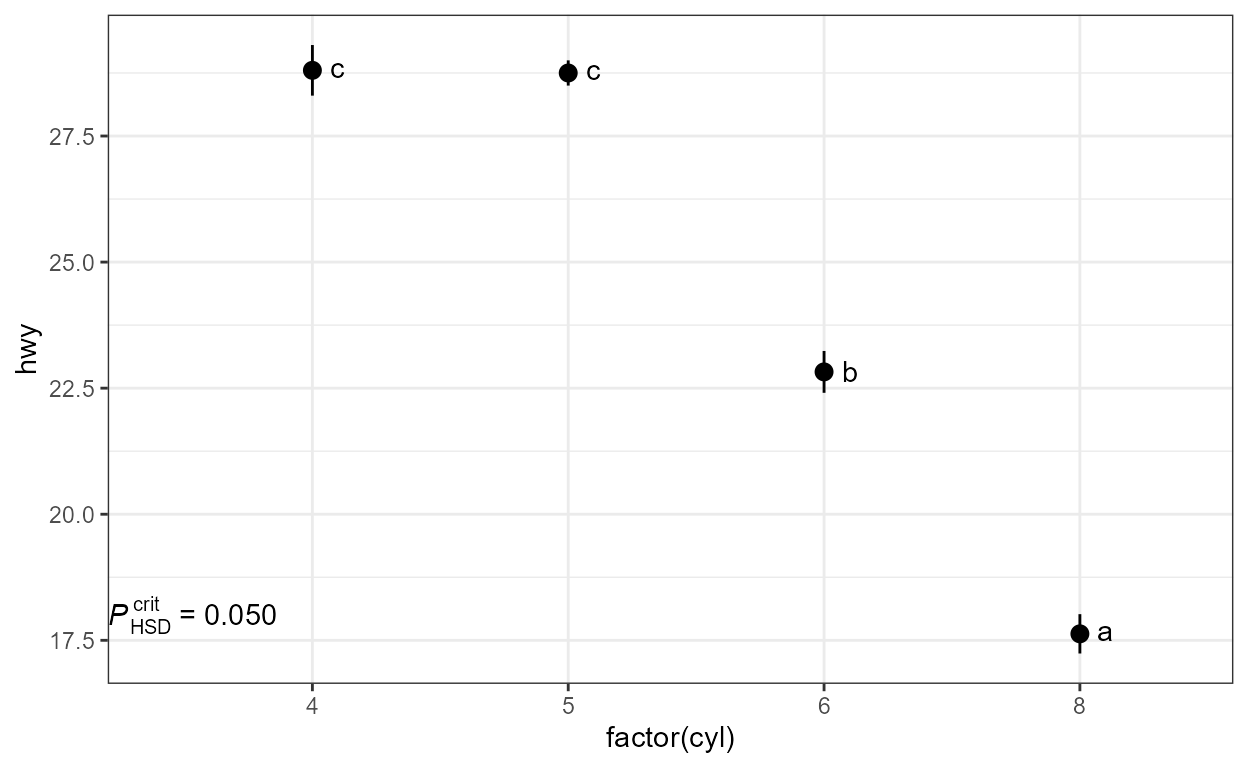
With Dunnet contrasts, the use of bars can clutter a plot, and we can alternatively show the outcome for each level that has been compared to a control, the first level.
ggplot(mpg, aes(factor(cyl), hwy)) +
geom_boxplot(width = 0.33) +
stat_multcomp(aes(x = stage(start = factor(cyl),
after_stat = xmax)),
geom = "text",
label.y = "bottom",
vstep = 0,
contrasts = "Dunnet")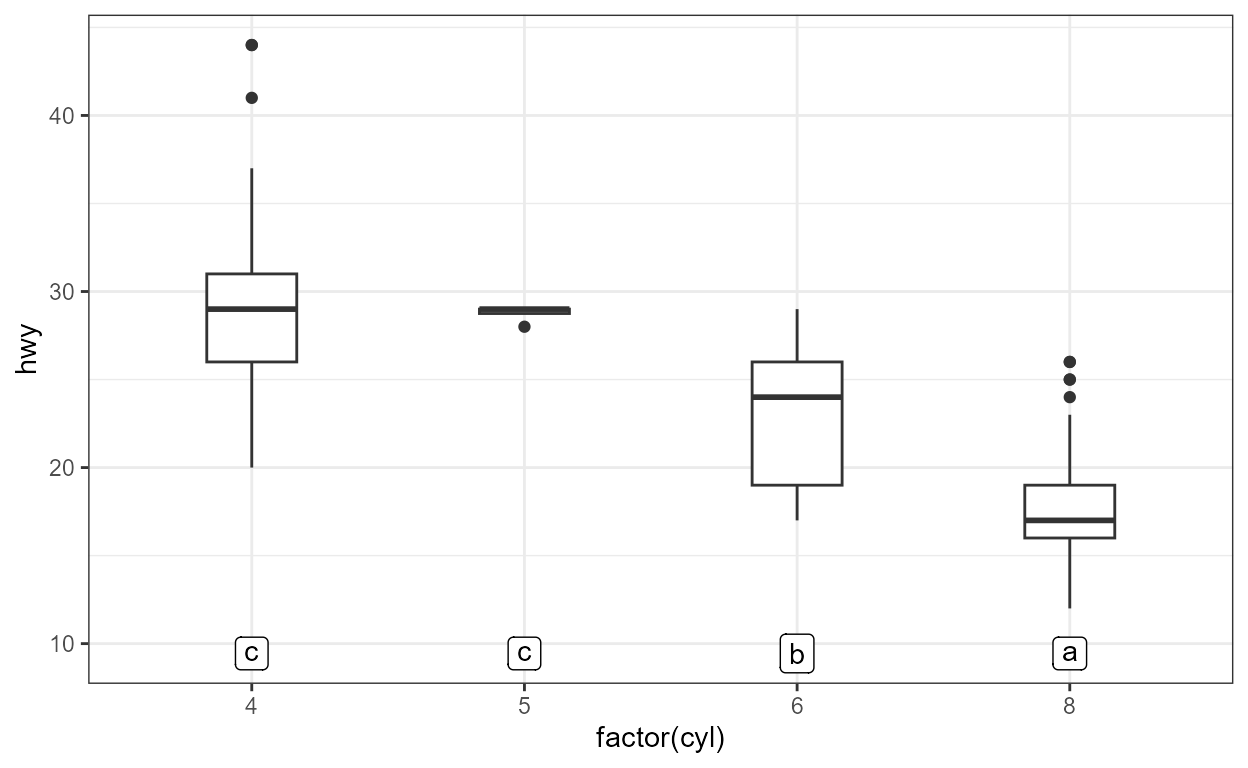
ggplot(mpg, aes(factor(cyl), hwy)) +
geom_boxplot(width = 0.33) +
stat_multcomp(aes(x = stage(start = factor(cyl),
after_stat = xmax),
label = after_stat(stars.label)),
geom = "text",
label.y = "bottom",
vstep = 0,
contrasts = "Dunnet")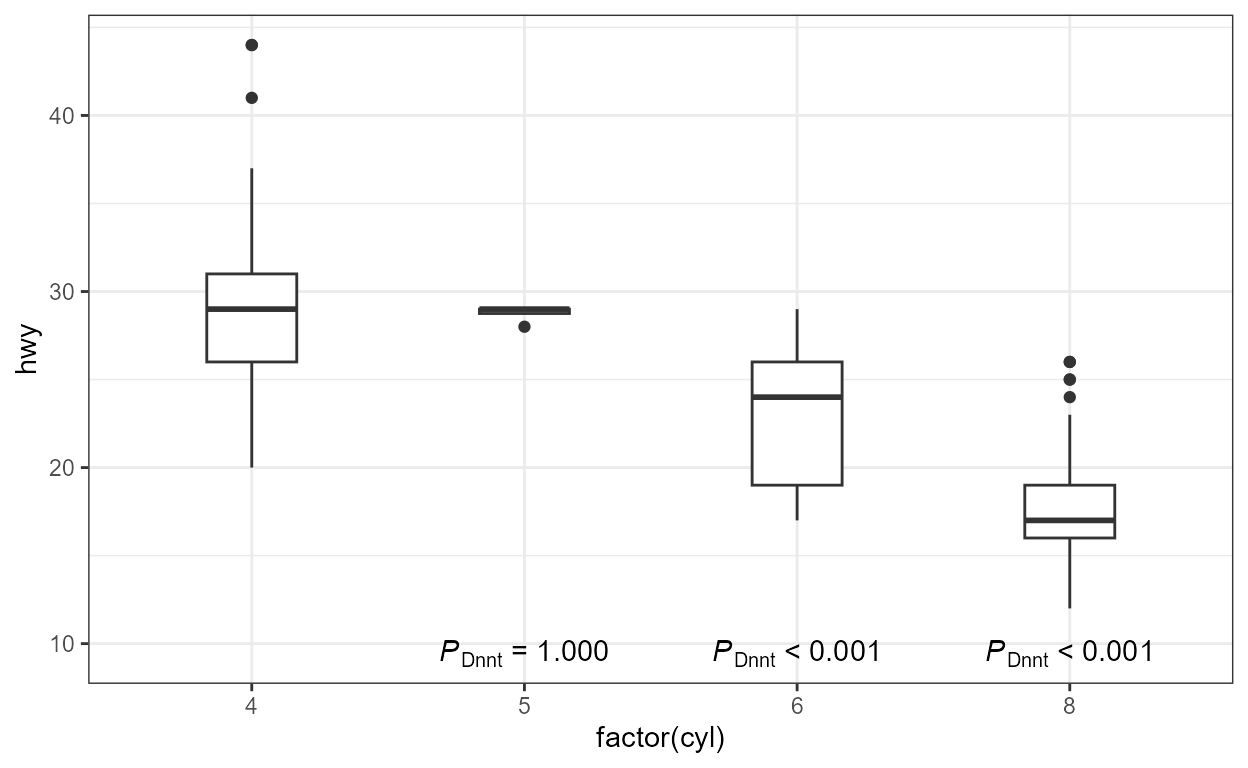
The returned value includes numeric and logical values in addition to
character strings mapped to the label aesthetic. These
values can be used to encode the outcomes using additional or different
aesthetics than the default ones. Variable p.signif is
TRUE if p.value < mc.critical.p.value. In
this example colour is used to highlight significant
pairwise differences based on the default critical value of 0.05.
ggplot(mpg, aes(factor(cyl), hwy)) +
geom_boxplot(width = 0.33) +
stat_multcomp(aes(colour = after_stat(p.signif)),
size = 2.75) +
scale_colour_manual(values = c("grey60", "black")) +
theme_bw()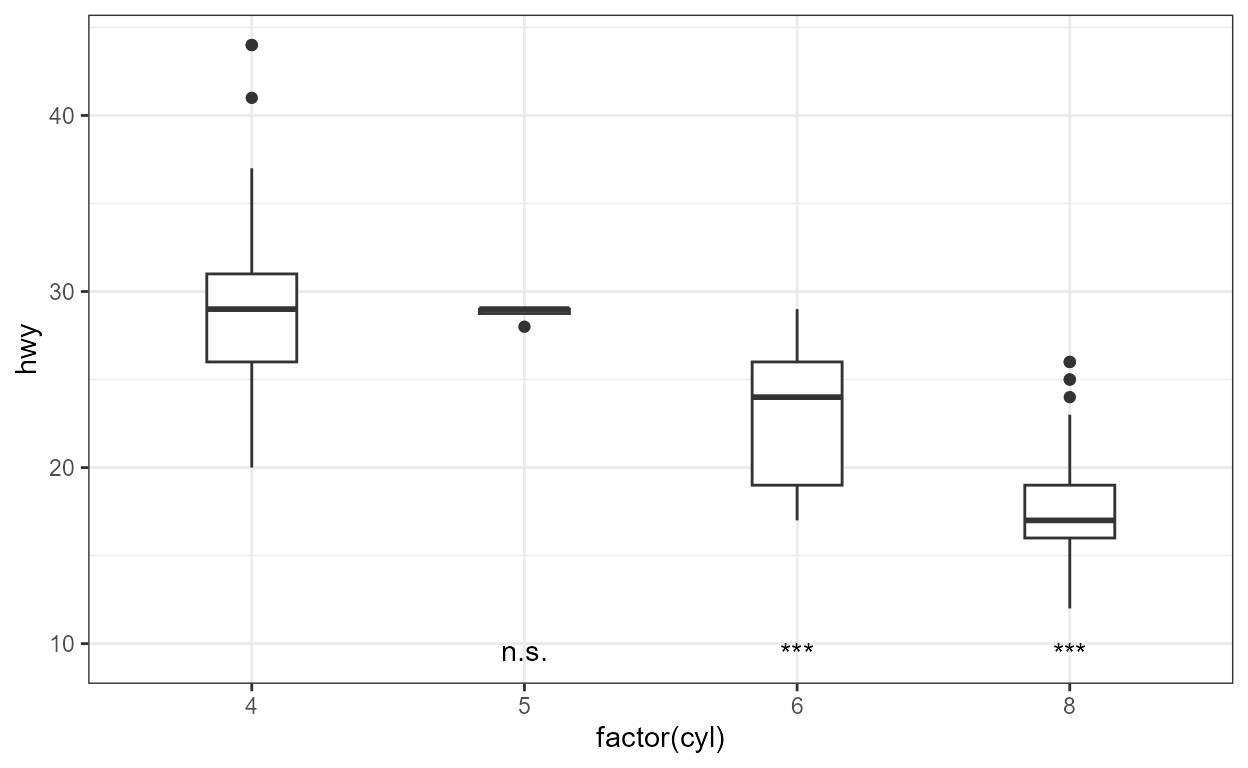
Alternatively, the test can be done against the numeric
variable p.value. In this example fill is used
to highlight significant pairwise differences and arrows heads added to
segments.
ggplot(mpg, aes(factor(cyl), hwy)) +
geom_boxplot(width = 0.33) +
stat_multcomp(aes(fill = after_stat(p.value) < 0.01),
size = 2.5,
arrow = grid::arrow(angle = 45,
length = unit(1, "mm"),
ends = "both")) +
scale_fill_manual(values = c("white", "lightblue"))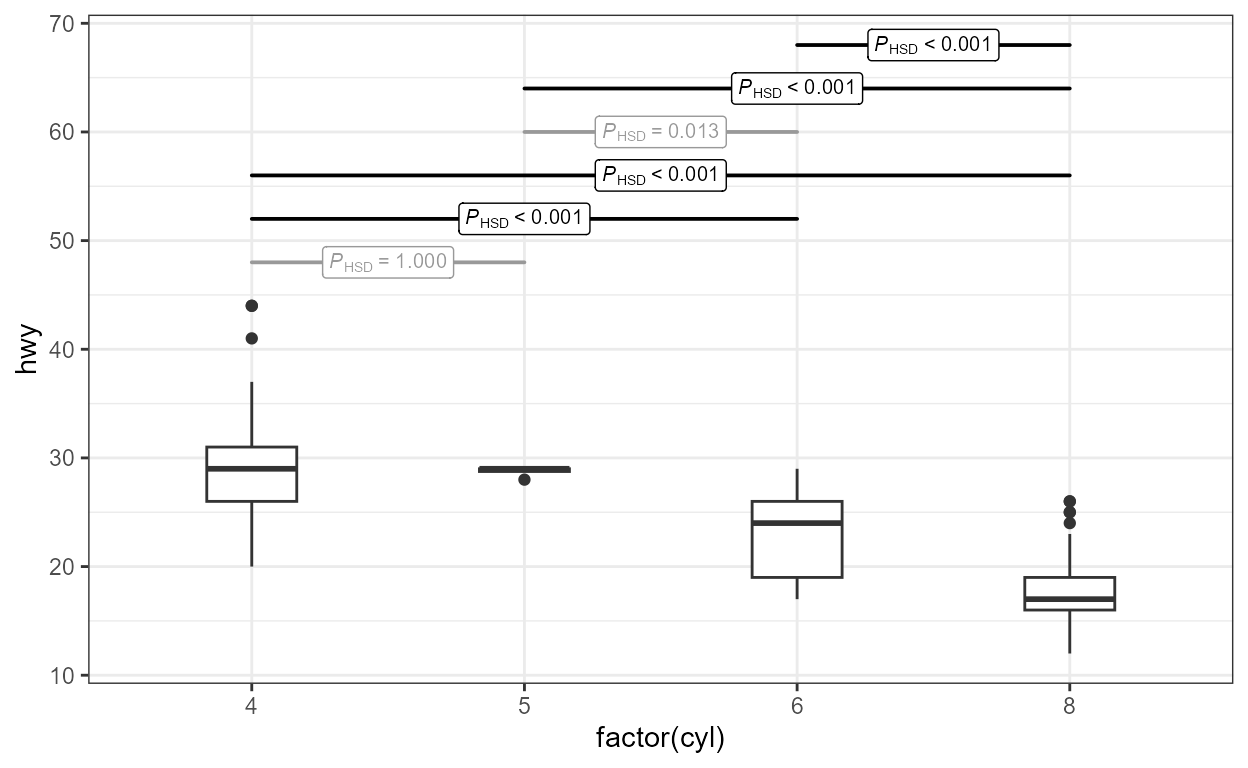
stat_fit_residuals
Sometimes we need to quickly plot residuals matching fits plotted
with stat_poly_line(), stat_quant_line(),
stat_ma_line() or ggplot2::stat_smooth()
(e.g., using grouping and facets). Function
stat_fit_residuals() makes this easy. In teaching it is
specially important to avoid distractions and plots residuals from
different types of models consistently.
stat_fit_residuals() can be used to plot the residuals
from models of y on x or x on y
fitted with function lm, MASS:rlm,
quantreg::rq (only median regression) or a user-supplied
model fitting function and arguments. In the data frame returned by the
statistic the response variable, y or x, is replaced
by the residuals from the fit and thus also by default mapped to the
aesthetic of the same name. The default geom is
"point".
ggplot(my.data, aes(x, y.otlr, colour = group)) +
geom_hline(yintercept = 0, linetype = "dashed") +
stat_fit_residuals()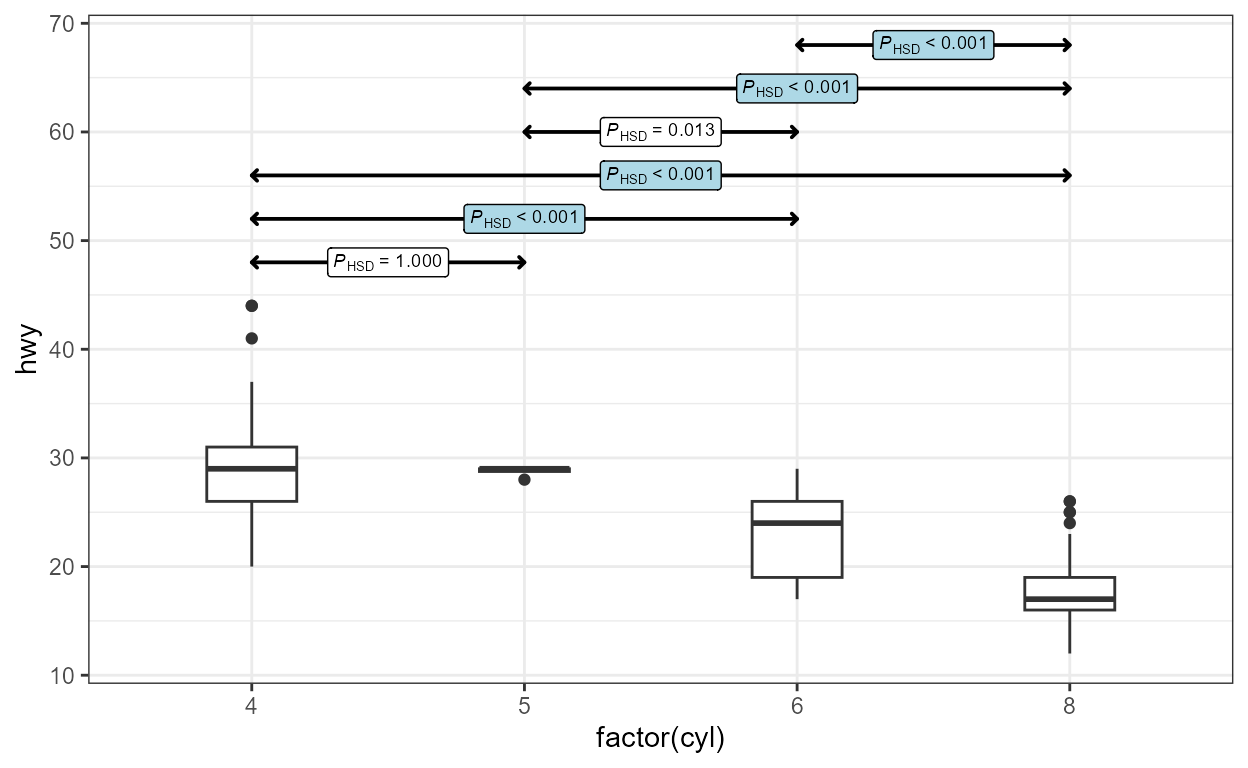
Depending on the model fit method, two types of
weights are available: prior weights given by a numeric
variable mapped to weight aesthetic and posterior weights,
actually used, and possibly computed during model fitting. Depending on
the model fit method, prior and posterior weights can be
the same or not. Function stat_fit_residuals() returns the
prior weights supplied as input in the variable named
weights and the posterior actually used weights, possibly
computed “robustness” weights, in the variable named
posterior.weights. Both weights can be mapped to
aesthetics, in the example below posterior.weights are
mapped to size. In a model fit with lm(),
prior and posterior weights are the same, and by default equal to 1. In
a fit with rlm() prior and posterior weights differ.
ggplot(my.data, aes(x, y.otlr, colour = group)) +
geom_hline(yintercept = 0, linetype = "dashed") +
stat_fit_residuals(method = "rlm",
mapping = aes(size = after_stat(posterior.weights)),
alpha = 1/2) +
scale_size_area(name = "Posterior\nweights", max_size = 3)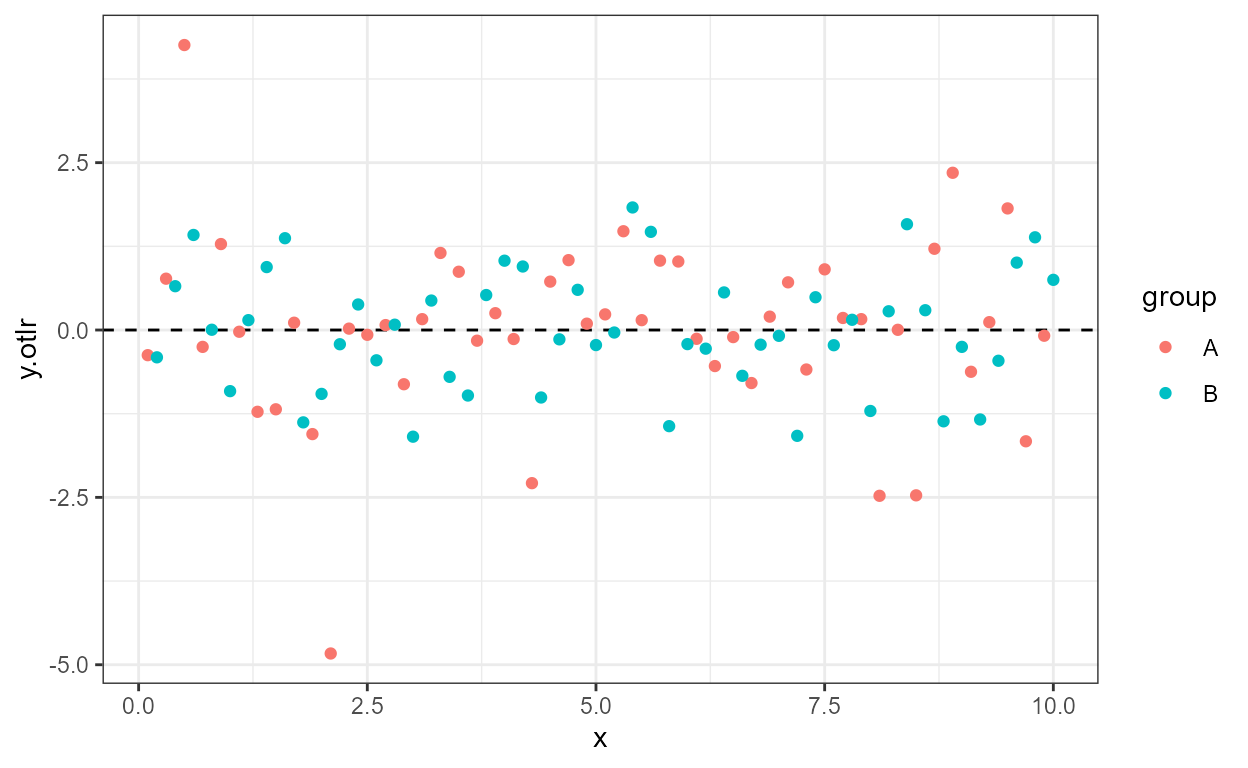
Of course it is also possible to plot the weights themselves.
ggplot(my.data, aes(x, y.otlr, colour = group)) +
geom_hline(yintercept = 0, linetype = "dashed") +
stat_fit_residuals(method = "rlm",
mapping =
aes(y = stage(start = y.otlr,
after_stat = posterior.weights)),
alpha = 1/2) +
scale_y_continuous(name = "Posterior weights")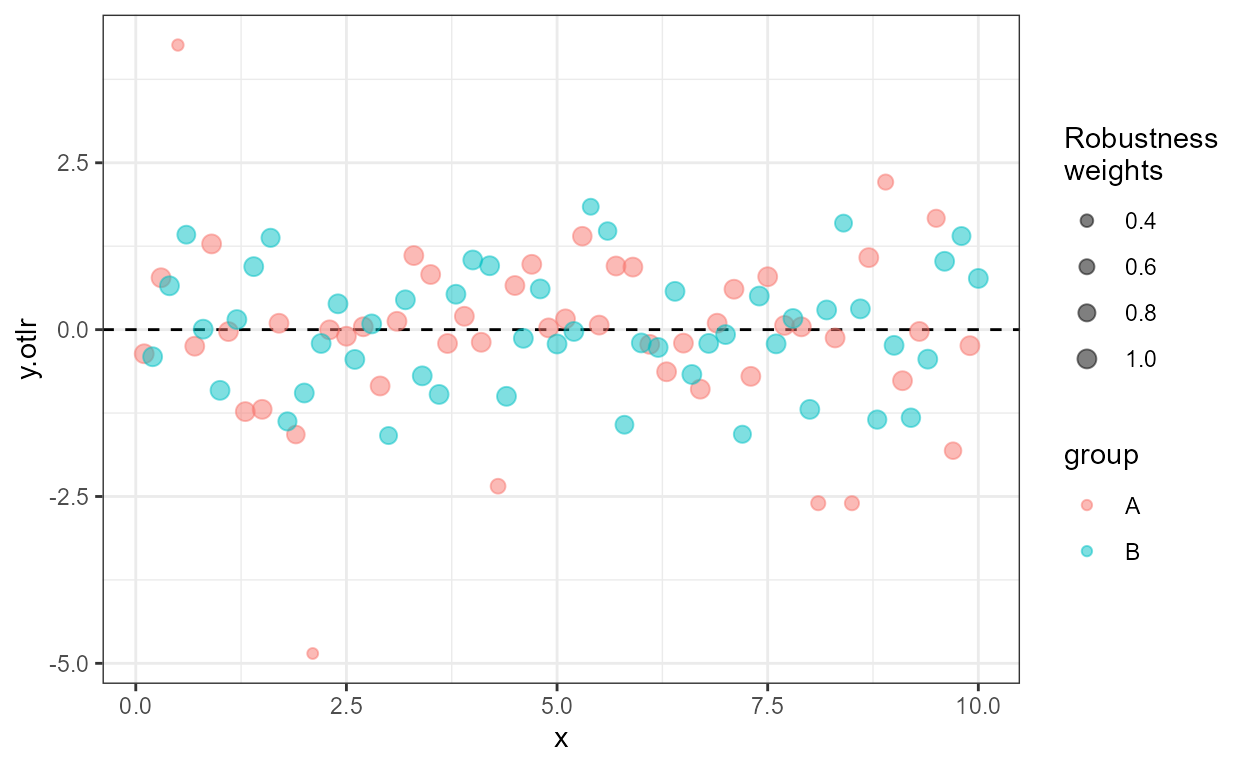
Weighted residuals are available, and in this case they differ from
the raw residuals as we have mapped variable wght.otlr to
the weight aesthetic. Compare the two figures below.
ggplot(my.data, aes(x, y.otlr,
weight = wght.otlr,
colour = group)) +
geom_hline(yintercept = 0, linetype = "dashed") +
stat_fit_residuals(formula = formula,
mapping = aes(size = after_stat(posterior.weights)),
weighted = FALSE) +
scale_size_area(name = "Posterior\nweights", max_size = 3)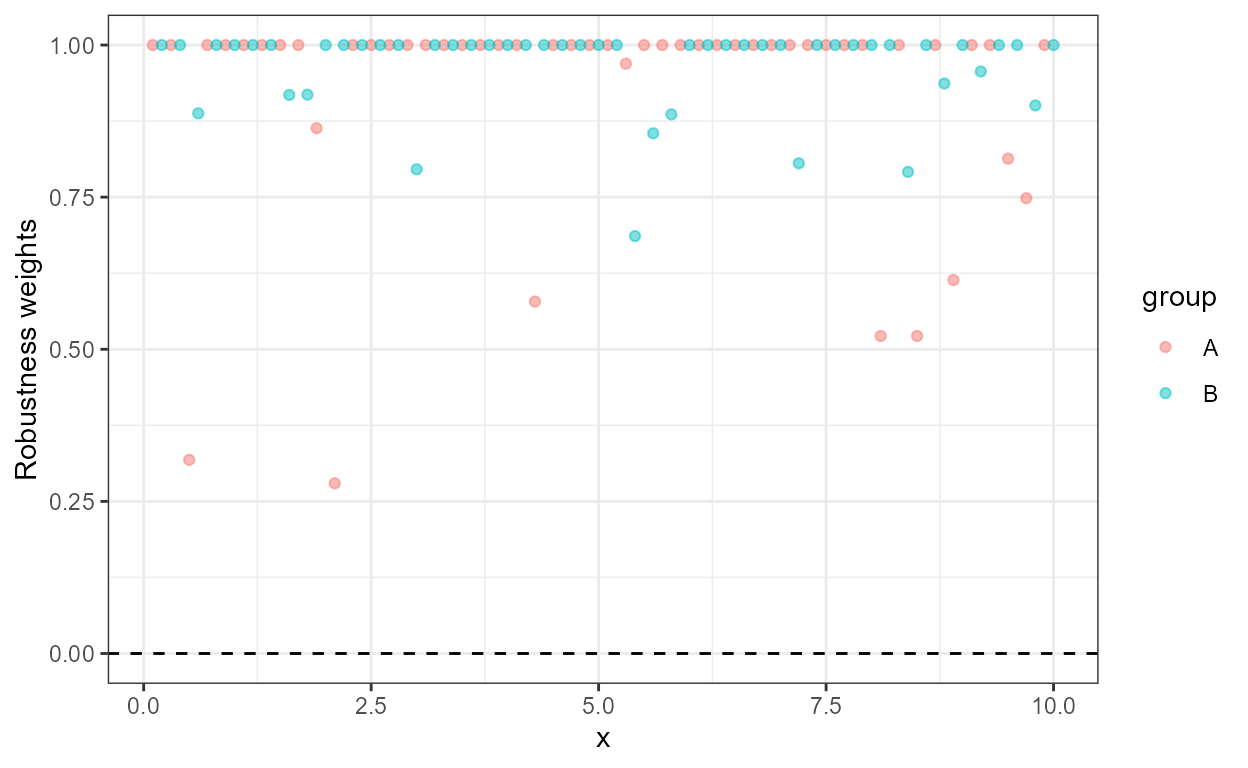
ggplot(my.data, aes(x, y.otlr,
weight = wght.otlr,
colour = group)) +
geom_hline(yintercept = 0, linetype = "dashed") +
stat_fit_residuals(formula = formula,
mapping = aes(size = after_stat(posterior.weights)),
weighted = TRUE) +
scale_size_area(name = "Posterior\nweights", max_size = 3)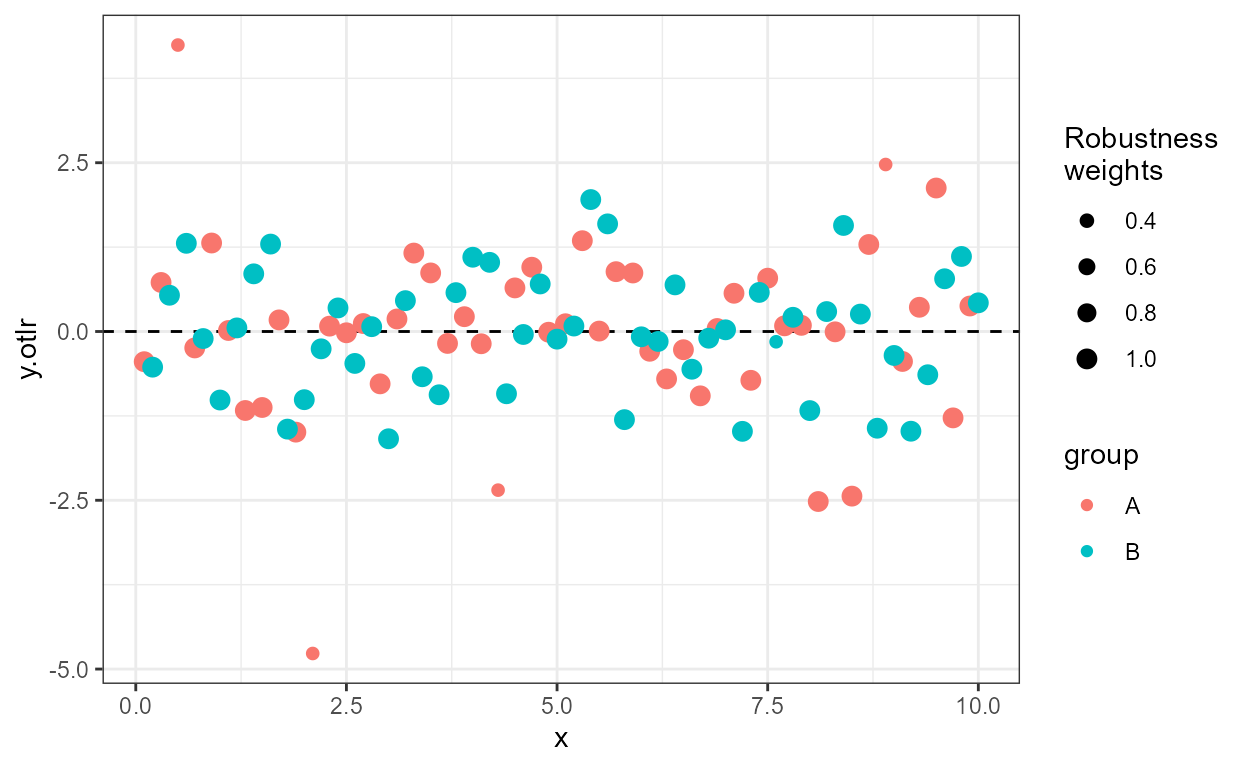
stat_fit_deviations
When teaching we may wish to highlight residuals in plots used in
slides and notes. Statistic stat_fit_deviations() makes it
easy to achieve this for the residuals from models of y on
x or x on y fitted with function
lm, MASS:rlm, quantreg::rq (only
median regression) or a user-supplied model fitting function and
arguments. The observed values are mapped to aesthetics x and
y, and the fitted values are mapped to aesthetics xend
and yend. As the default geom is "segment", each
deviation is displayed as a segment.
ggplot(my.data, aes(x, y)) +
stat_poly_line() +
stat_fit_deviations(colour = "red") +
geom_point()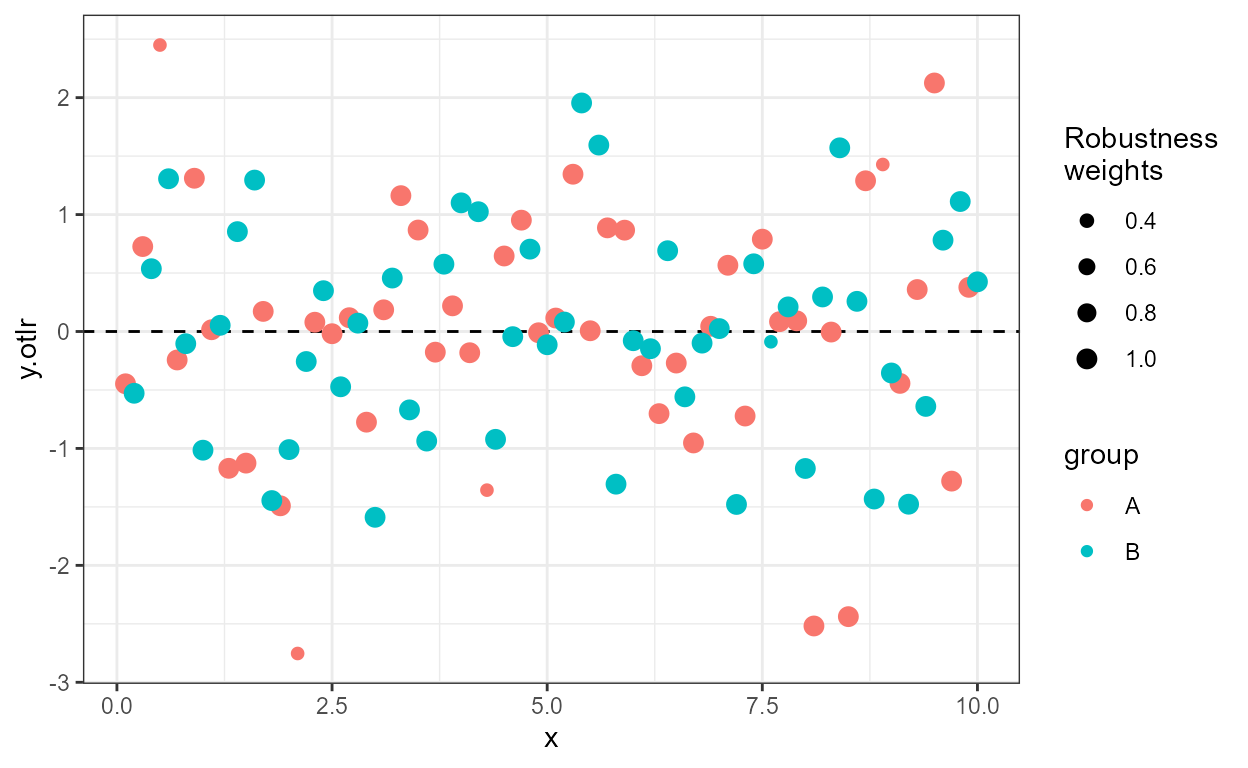
The geometry used by default is ggplot2::geom_segment()
and additional aesthetics can be mapped or set to constant values. Here
we add arrowheads.
ggplot(my.data, aes(x, y)) +
stat_poly_line() +
geom_point() +
stat_fit_deviations(arrow = arrow(length = unit(0.015, "npc"),
ends = "both"))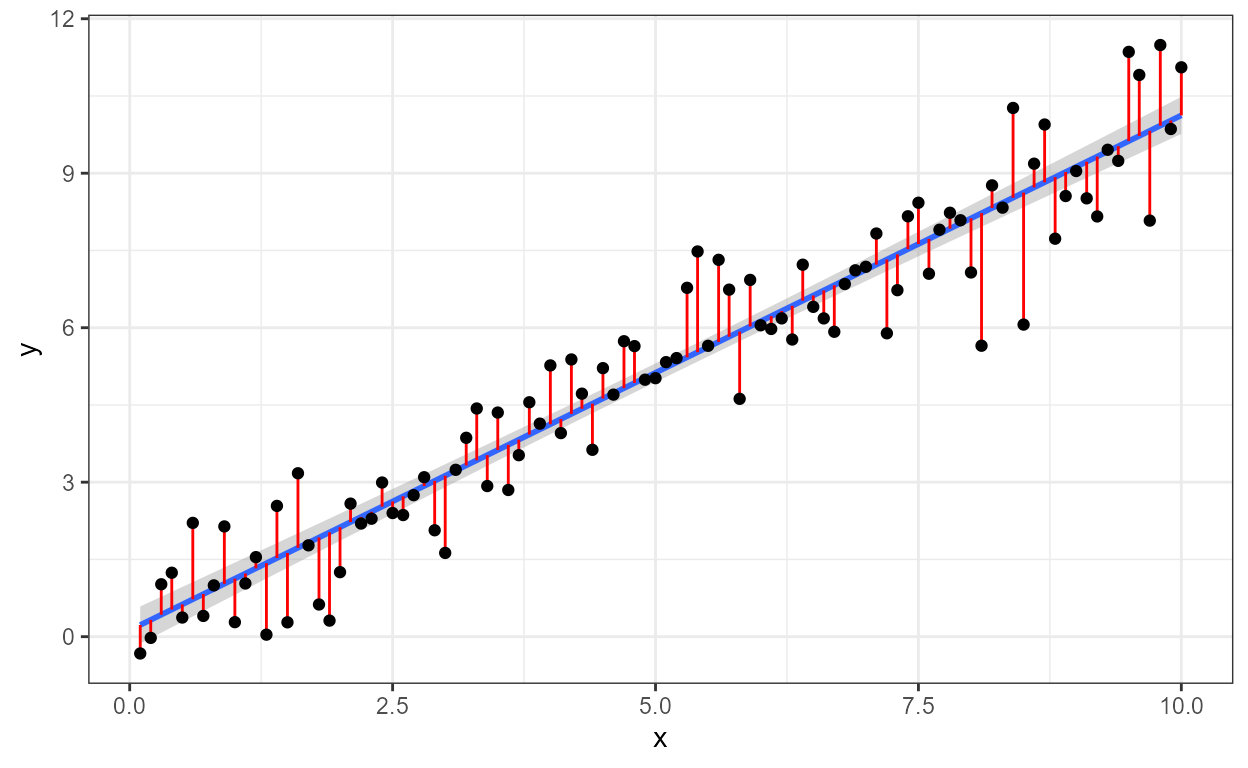
When weights are available, either supplied by the user, or computed
as part of the fit, they are returned in data. Having
weights available allows encoding them using colour. We here use a
robust regression fit with MASS::rlm().
ggplot(my.data, aes(x, y.otlr)) +
stat_poly_line(method = "rlm") +
stat_fit_deviations(formula = formula, method = "rlm",
mapping = aes(colour = after_stat(posterior.weights)),
linewidth = 1,
show.legend = TRUE) +
scale_color_gradient(name = "Posterior\nweight",
low = "red", high = "grey60", limits = c(0, 1)) +
geom_point()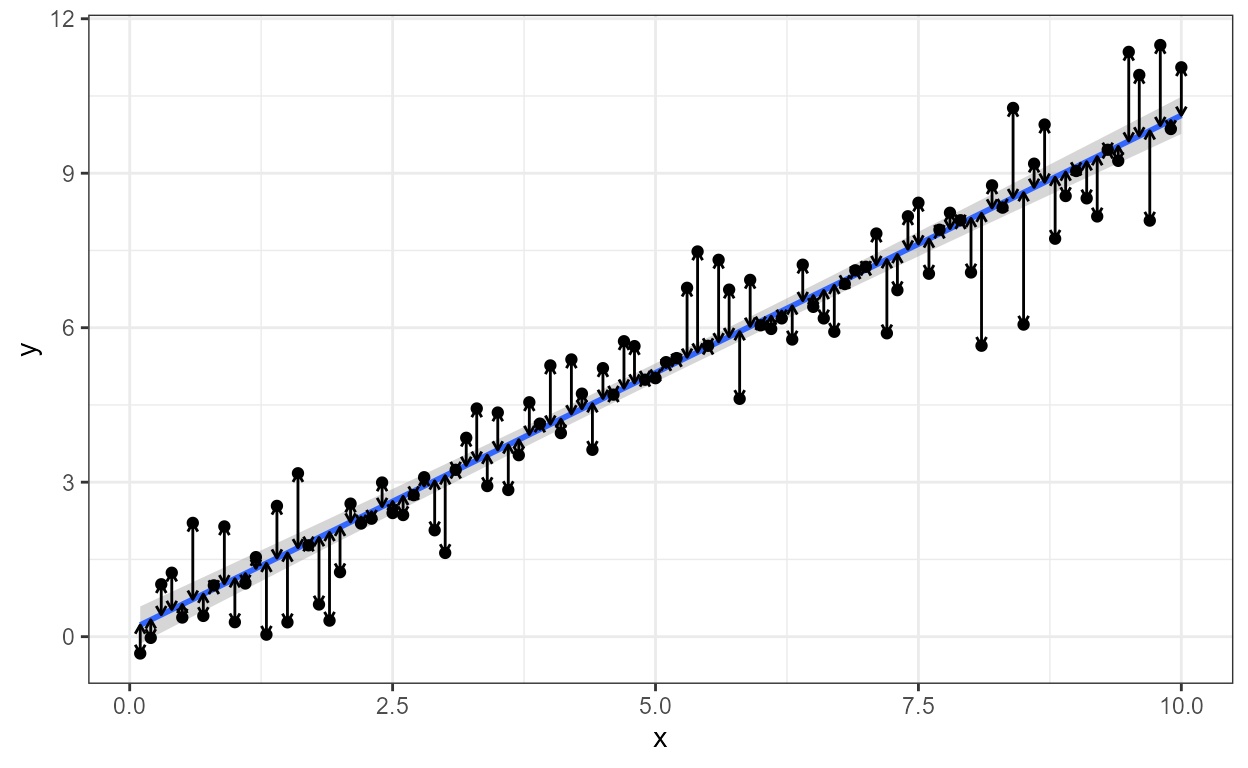
With method gls() using varPower() fitted
weights for heterogeneous error variance describe the change in variance
as a function of the fitted values.
ggplot(my.data, aes(x, y.sdinc)) +
stat_fit_deviations(method = "gls",
method.args = list(weights = varPower(form = ~ x)),
mapping =
aes(colour = after_stat(posterior.weights)),
linewidth = 1,
show.legend = TRUE) +
stat_poly_line(method = "gls",
method.args = list(weights = varPower(form = ~ x))) +
geom_point() +
scale_colour_gradient2(name = "Power of variance\nweight",
midpoint = 1, low = "blue", high = "red", mid = "grey60")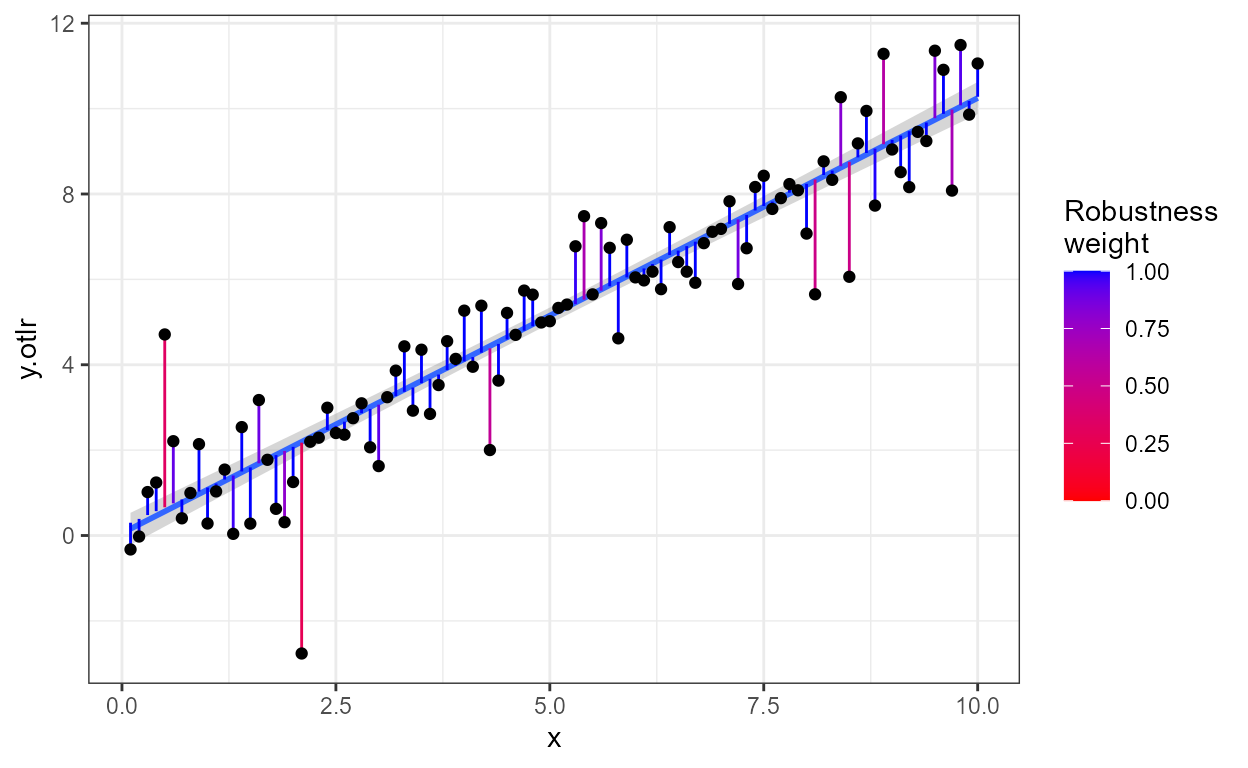
Of course it is also possible to plot the weights themselves, most
easily using stat_fit_residuals(). The weights when using a
variance covariate with its defaults, like here, are a function of the
predicted values rather than of the individual deviations.
ggplot(my.data, aes(x, y.sdinc)) +
stat_fit_residuals(method = "gls",
method.args = list(weights = varPower(form = ~ x)),
geom = "point",
mapping =
aes(y = stage(start = y.sdinc,
after_stat = posterior.weights),
colour = after_stat(posterior.weights))) +
scale_colour_gradient2(name = "Power of\nvariance\nweight",
midpoint = 1, low = "blue", high = "red", mid = "grey80")
stat_fit_glance
Package ‘broom’ provides consistently formatted output from different
model fitting functions. These made it possible to write a
model-annotation statistic that is very flexible but that requires
additional input from the user to generate the character strings to be
mapped to the label aesthetic.
As we have above given some simple examples, we here exemplify this statistic in a plot with grouping, and assemble a label for the P-value using a string parsed into a expression. We also change the default position of the labels.
In an interactive R session the message shown below is issued twice,
once for each group created by the mapping of group to the
colour aesthetic. The message lists all variables returned
by the statistics and accessible within a call to aes()
using after_stat().
'stat_fit_glance' variables (1 rows): r.squared, adj.r.squared, sigma, statistic, p.value, df, logLik, AIC, BIC, deviance, df.residual, nobs, fm.class, fm.method, fm.formula, fm.formula.chr, npcx, npcy, flipped_aes.Many of variable names, and are those returned by the call to the
glance() method.
# formula <- y ~ poly(x, 3, raw = TRUE)
# broom::augment does not handle poly() correctly!
formula <- y ~ x + I(x^2) + I(x^3)
ggplot(my.data, aes(x, y.poly.grp, colour = group)) +
geom_point() +
stat_poly_line(formula = formula) +
stat_fit_glance(method = "lm",
method.args = list(formula = formula),
label.x = "right",
label.y = "bottom",
aes(label = sprintf("italic(P)*\"-value = \"*%.3g",
after_stat(p.value))),
parse = TRUE)
It is also possible to fit a non-linear model using least squares
(LS) with method = "nls", and any other model for which a
broom::glance() method exists. Do consult the documentation
for package ‘broom’. Here we fit the Michaelis-Menten equation to
reaction rate versus concentration data.
In this case the message issued in interactive R sessions is different to that for the example above.
'stat_fit_glance' variables (1 rows): sigma, isConv, finTol, logLik, AIC, BIC, deviance, df.residual, nobs, fm.class, fm.method, fm.formula, fm.formula.chr, npcx, npcy, flipped_aes.
micmen.formula <- y ~ SSmicmen(x, Vm, K)
ggplot(Puromycin, aes(conc, rate, colour = state)) +
geom_point() +
stat_smooth(method = "nls",
formula = micmen.formula,
se = FALSE) +
stat_fit_glance(method = "nls",
method.args = list(formula = micmen.formula),
aes(label =
after_stat(
paste("AIC = ", signif(AIC, digits = 3),
", BIC = ", signif(BIC, digits = 3),
sep = ""))),
label.x = "centre",
label.y = "bottom")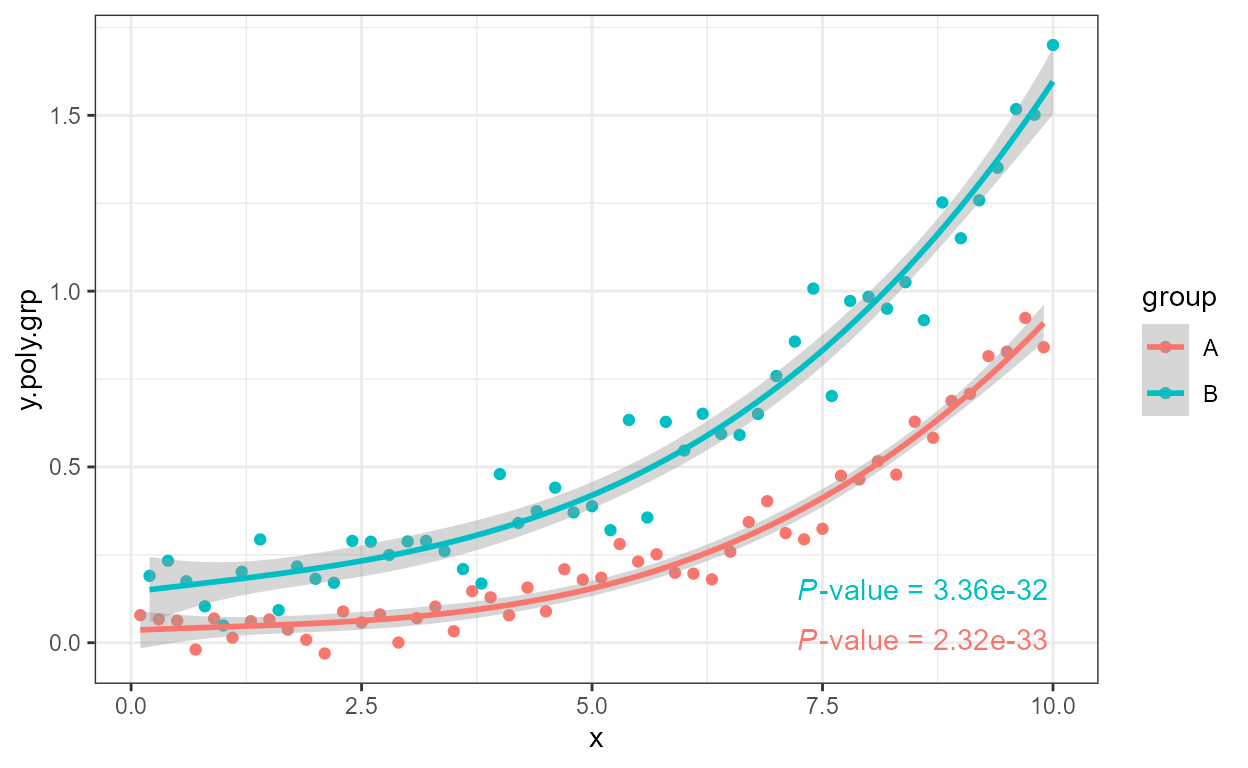
stat_fit_tb
This ggplot statistic makes it possible to add summary or ANOVA
tables for any fitted model for which broom::tidy() is
implemented. The output from broom::tidy() is embedded as a
single list value within the returned data, as an object of
class tibble::tibble.
This statistic ignores grouping based on aesthetics,
i.e., uses a panel function to fit the model. Fitting the model
by panel allows fitting models when x or y is
a factor (as in such cases ggplot splits the
data into groups, one for each level of the factor, which is needed for
example for stat_summary() to work as expected). By
default, the "table" geometry is used. The use of
ggpp::geom_table() is described in the User Guide of
package ‘ggpp’. Table themes and mapped aesthetics are supported.
The default output of stat_fit_tb() is the default
output from tidy(fm) where fm is the fitted
model.
formula <- y ~ x + I(x^2) + I(x^3)
ggplot(my.data, aes(x, y.poly)) +
geom_point() +
stat_poly_line(formula = formula) +
stat_fit_tb(method.args = list(formula = formula),
tb.vars = c(Parameter = "term",
Estimate = "estimate",
"s.e." = "std.error",
"italic(t)" = "statistic",
"italic(P)" = "p.value"),
label.y = "top", label.x = "left",
parse = TRUE)
When tb.type = "fit.anova" the output returned is that
from tidy(anova(fm)) where fm is the fitted
model. Here we also show how to replace names of columns and terms, and
exclude one column, in this case, the mean squares.
formula <- y ~ x + I(x^2) + I(x^3)
ggplot(my.data, aes(x, y.poly)) +
geom_point() +
stat_poly_line(formula = formula) +
stat_fit_tb(method.args = list(formula = formula),
tb.type = "fit.anova",
tb.vars = c(Effect = "term",
df = "df",
"italic(F)" = "statistic",
"italic(P)" = "p.value"),
tb.params = c(x = 1, "x^2" = 2, "x^3" = 3, Resid = 4),
label.y = "top", label.x = "left",
parse = TRUE)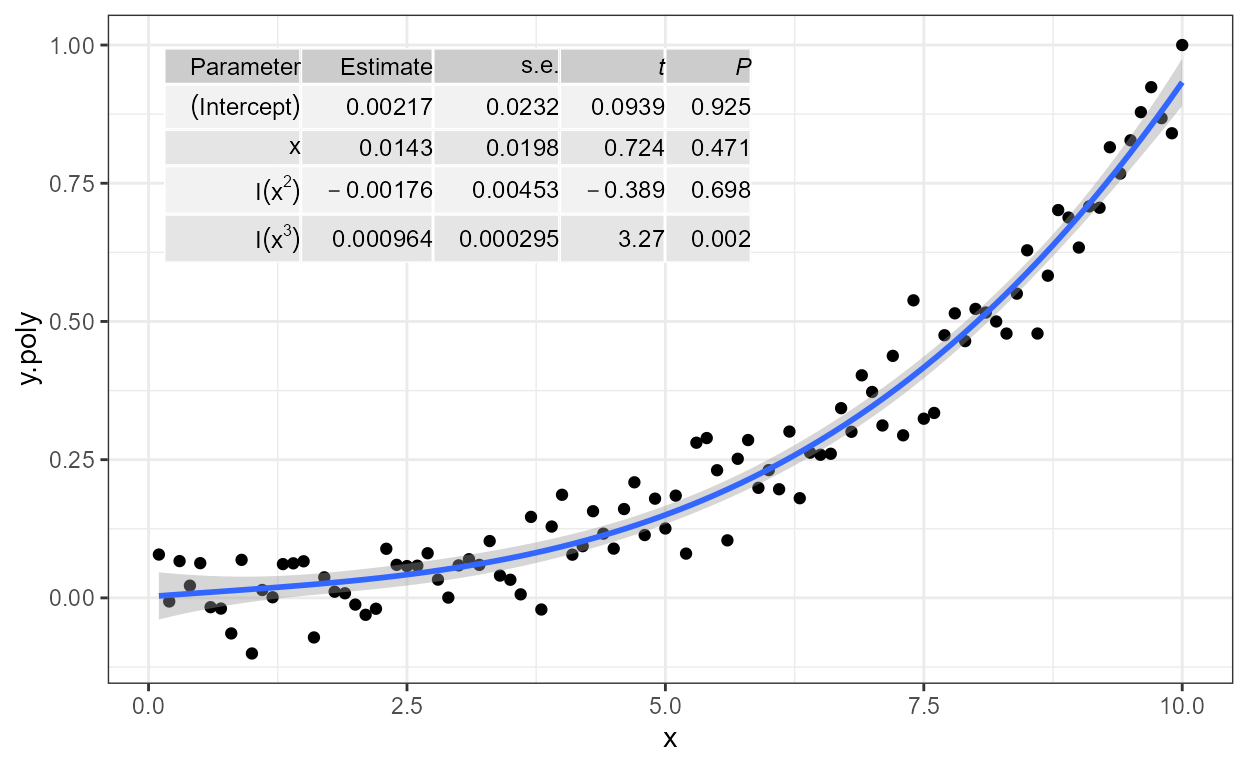
When tb.type = "fit.coefs" the output returned is that
of tidy(fm) after selecting the term and
estimate columns.
formula <- y ~ x + I(x^2) + I(x^3)
ggplot(my.data, aes(x, y.poly)) +
geom_point() +
stat_poly_line(method = "lm", formula = formula) +
stat_fit_tb(method = "lm",
method.args = list(formula = formula),
tb.type = "fit.coefs", parse = TRUE,
label.y = "center", label.x = "left")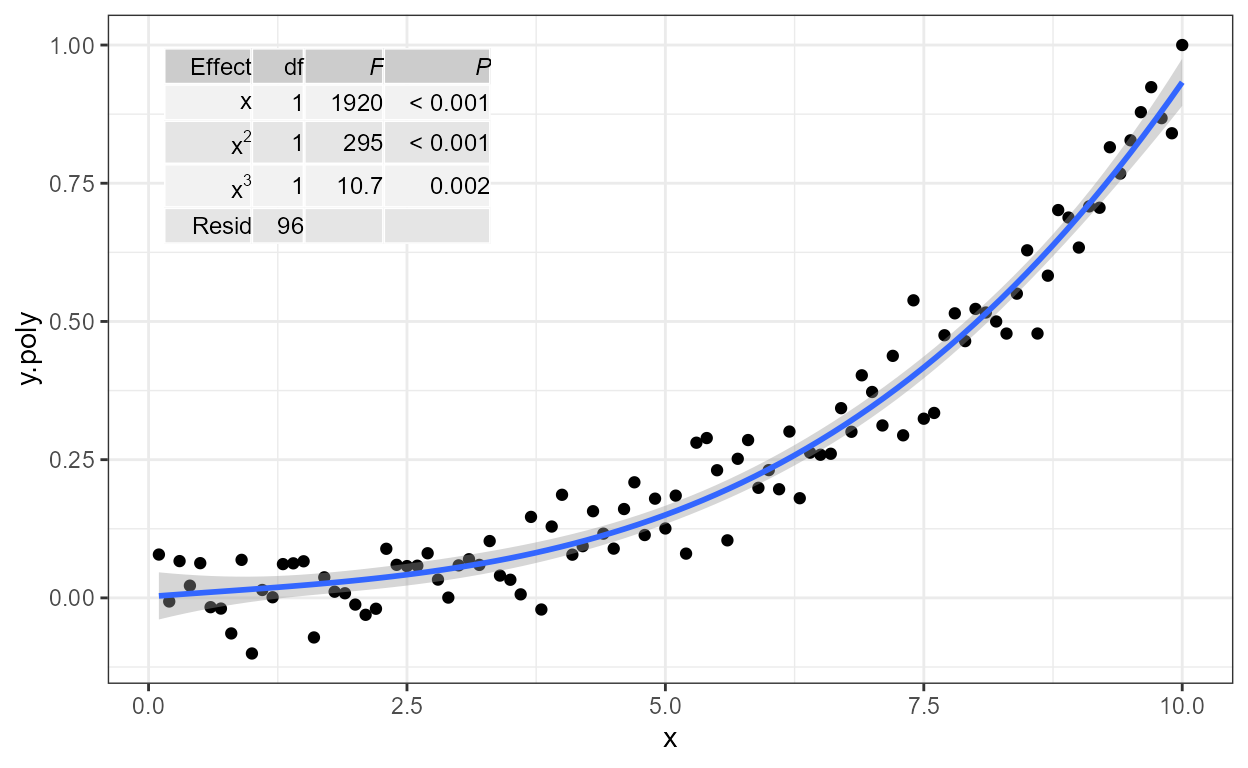
Faceting works as expected, but grouping is ignored as mentioned
above. In this case, the colour aesthetic is not applied to the text of
the tables. Furthermore, if label.x.npc or
label.y.npc are passed numeric vectors of length > 1,
the corresponding values are obeyed by the different panels.
micmen.formula <- y ~ SSmicmen(x, Vm, K)
ggplot(Puromycin, aes(conc, rate, colour = state)) +
facet_wrap(~state) +
geom_point() +
stat_smooth(method = "nls",
formula = micmen.formula,
se = FALSE) +
stat_fit_tb(method = "nls",
method.args = list(formula = micmen.formula),
tb.type = "fit.coefs",
label.x = 0.9,
label.y = c(0.75, 0.2)) +
theme(legend.position = "none") +
labs(x = "C", y = "V")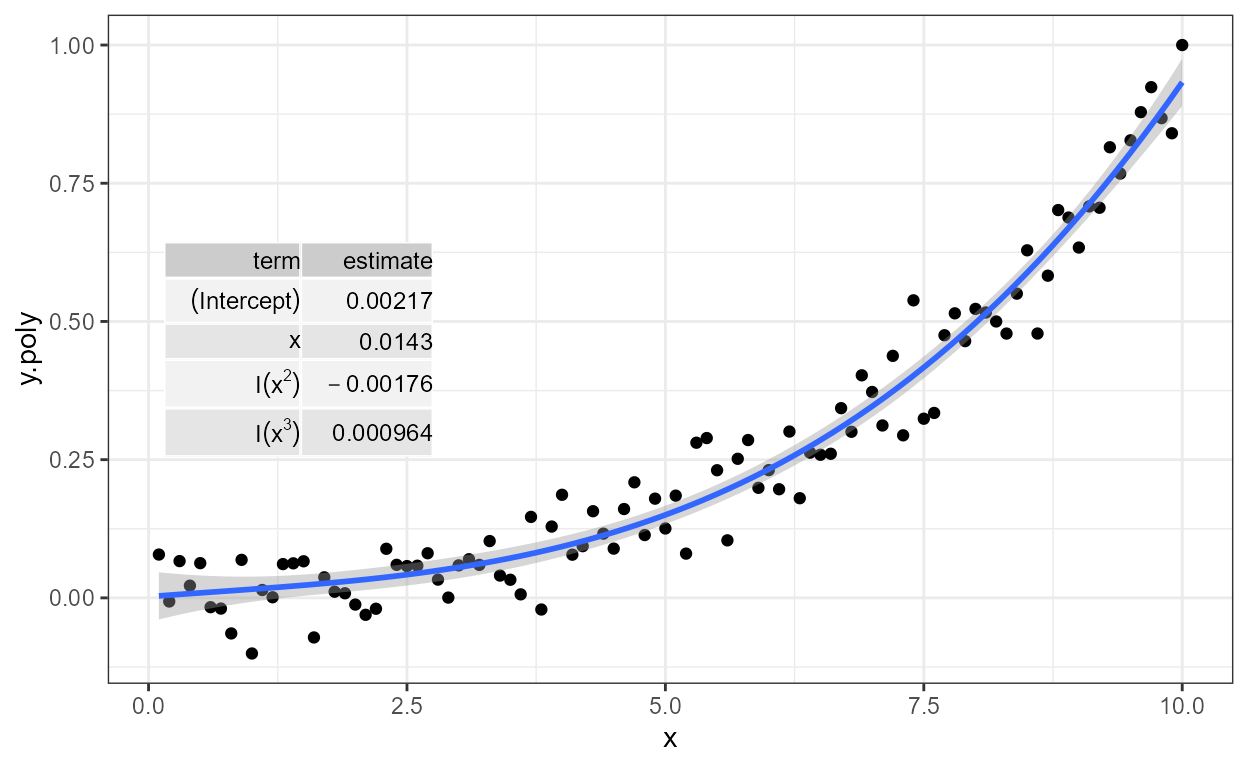
The data in the example below are split by ggplot into six groups
based on the levels of the feed factor. However,
stat_fit_tb(), differently to
stat_poly_line(), fits models by whole panel. Here the
explanatory variable mapped to x is a factor.
ggplot(chickwts, aes(reorder(factor(feed), weight), weight)) +
stat_summary(fun.data = "mean_se") +
stat_fit_tb(tb.type = "fit.anova",
label.x = "center",
label.y = "bottom") +
labs(x = "Feed") +
expand_limits(y = 0)
We can flip the system of coordinates, if desired.
ggplot(chickwts, aes(reorder(factor(feed), weight), weight)) +
stat_summary(fun.data = "mean_se") +
stat_fit_tb(tb.type = "fit.anova", label.x = "left", size = 3) +
scale_x_discrete(expand = expansion(mult = c(0.2, 0.5))) +
labs(y = "Feed") +
coord_flip()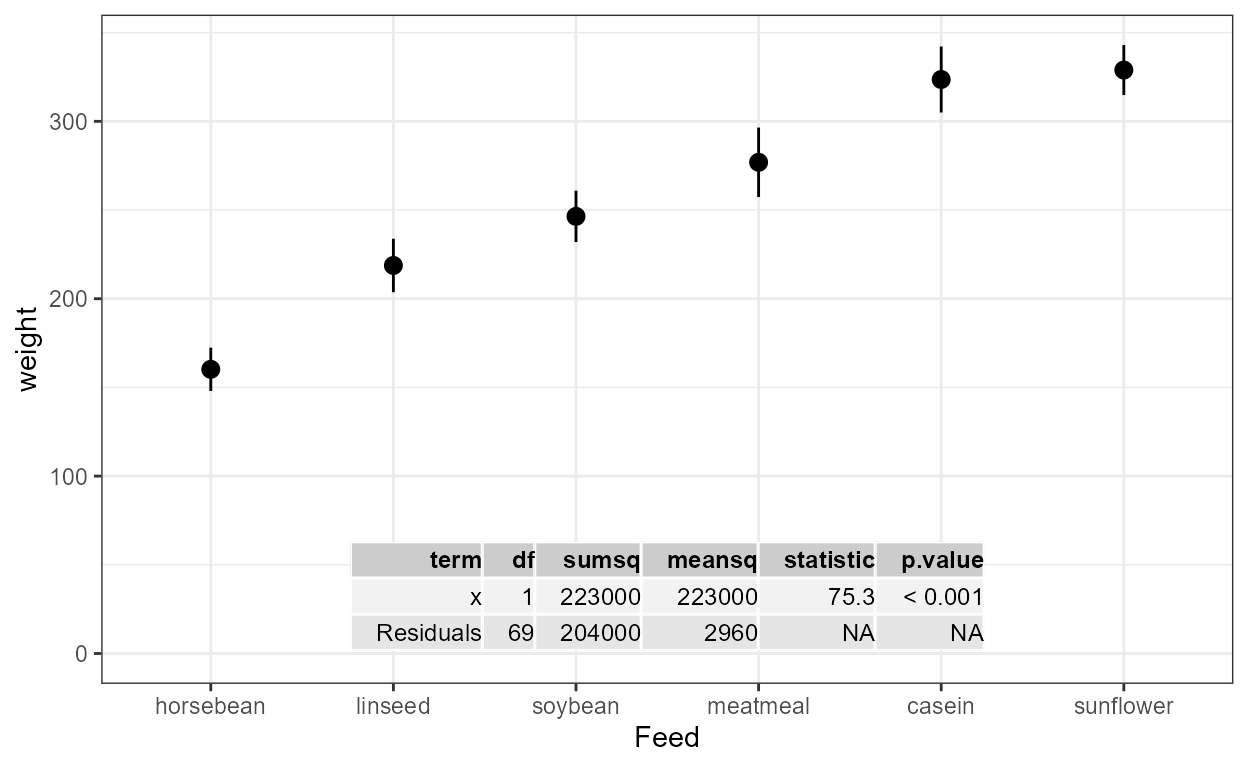
It is also possible to rotate the table using angle.
Here we also show how to replace the column headers with strings to be
parsed into R expressions.
ggplot(chickwts, aes(reorder(factor(feed), weight), weight)) +
stat_summary(fun.data = "mean_se") +
stat_fit_tb(tb.type = "fit.anova",
angle = 90, size = 3,
label.x = "right", label.y = "center",
hjust = 0.5, vjust = 0,
tb.vars = c(Effect = "term",
"df",
"M.S." = "meansq",
"italic(F)" = "statistic",
"italic(P)" = "p.value"),
parse = TRUE) +
scale_x_discrete(name = "Feed",
expand = expansion(mult = c(0.1, 0.35))) +
expand_limits(y = 0)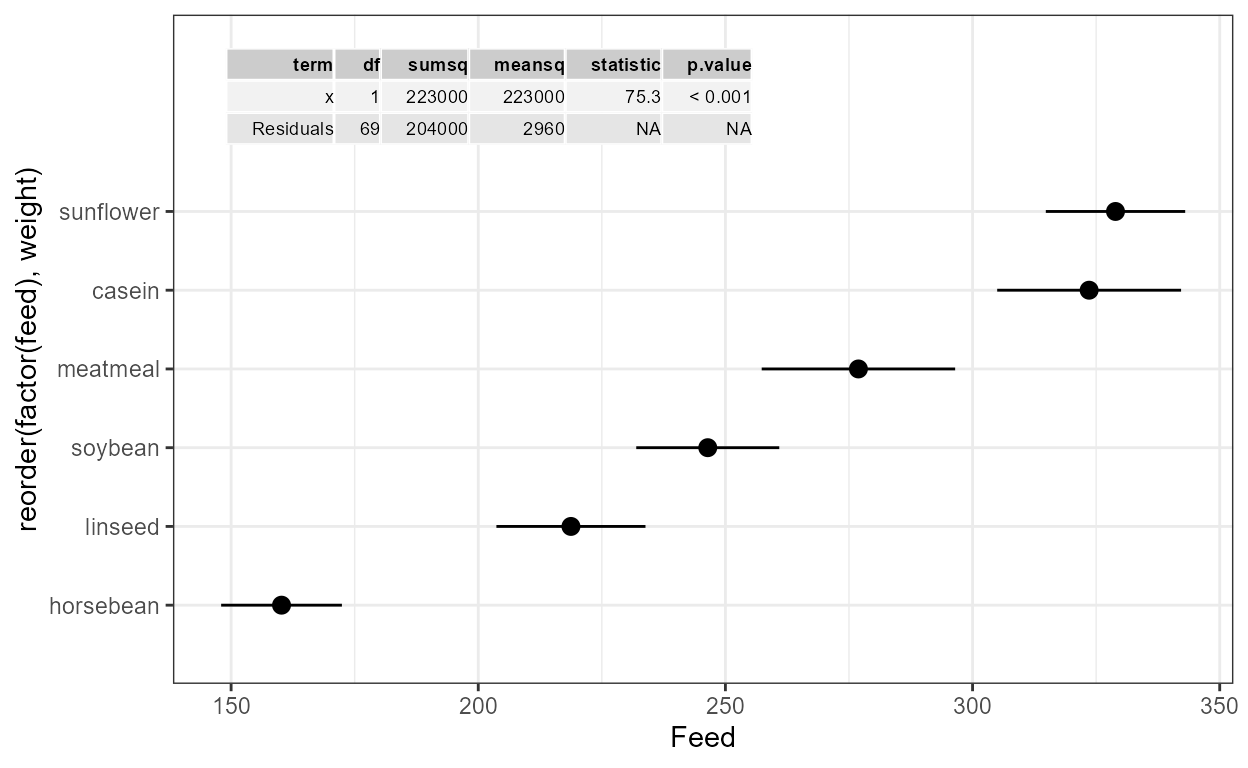
stat_fit_tidy
This stat makes it possible to add the equation for any fitted model
for which broom::tidy() is implemented. Alternatively,
individual values such as estimates for the fitted parameters, standard
errors, or P-values can be added to a plot. However, the user
has to explicitly construct the labels within
ggplot2::aes(). This statistic respects grouping based on
aesthetics, and reshapes the output of broom::tidy() so
that the values for a given group are in a single row in the returned
data.
As first example we fit a non-linear model, the Michaelis-Menten
equation of reaction kinetics, using stats::nls(). We use
the self-starting function stats::SSmicmen() available in
R.
In an interactive R session the message displayed is:
'stat_fit_tidy' variables (1 rows): Vm_estimate, K_estimate, Vm_se, K_se, Vm_stat, K_stat, Vm_p.value, K_p.value, npcx, npcy, fm.class, fm.method, fm.formula, fm.formula.chr, flipped_aes.
micmen.formula <- y ~ SSmicmen(x, Vm, K)
ggplot(Puromycin, aes(conc, rate, colour = state)) +
geom_point() +
stat_smooth(method = "nls",
formula = micmen.formula,
se = FALSE) +
stat_fit_tidy(method = "nls",
method.args = list(formula = micmen.formula),
label.x = "right",
label.y = "bottom",
aes(label =
after_stat(
paste("V[m]~`=`~", signif(Vm_estimate, digits = 3),
"%+-%", signif(Vm_se, digits = 2),
"~~~~K~`=`~", signif(K_estimate, digits = 3),
"%+-%", signif(K_se, digits = 2),
sep = ""))),
parse = TRUE)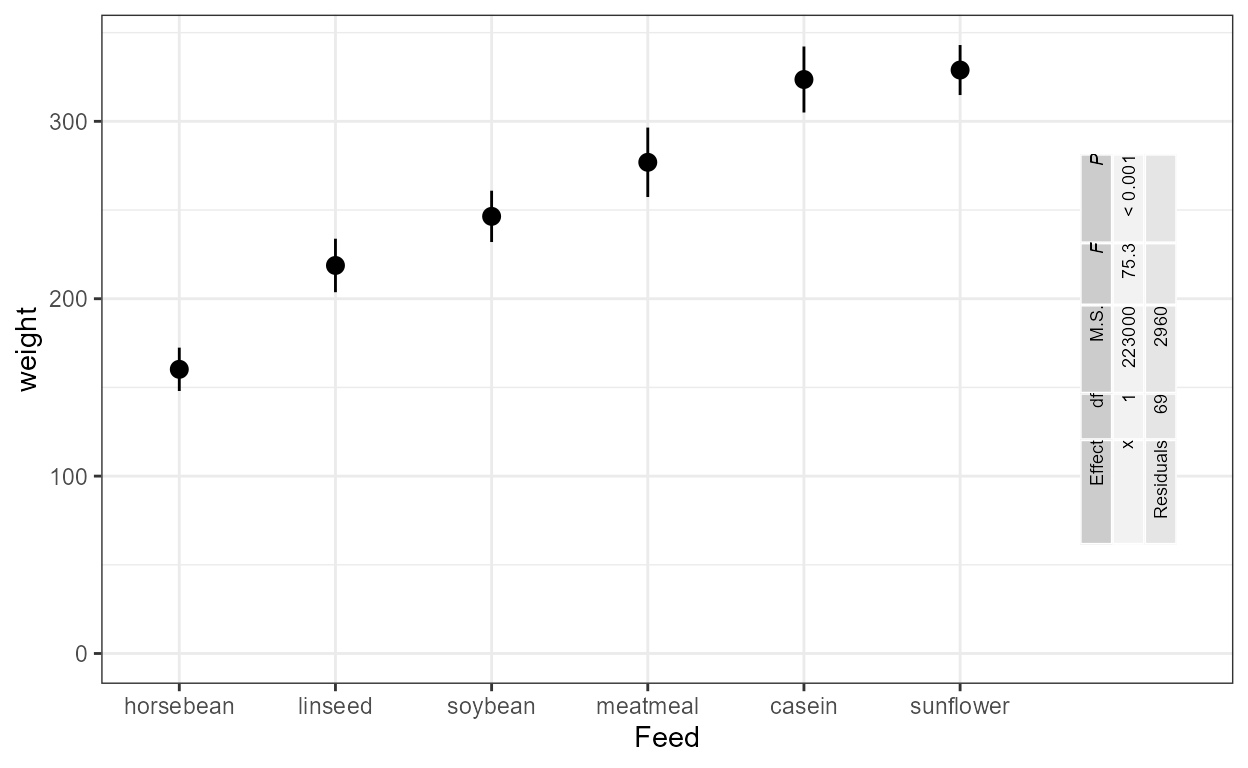
Using paste we can build a string that can be parsed into an R expression, in this case for a non-linear equation.
micmen.formula <- y ~ SSmicmen(x, Vm, K)
ggplot(Puromycin, aes(conc, rate, colour = state)) +
geom_point() +
stat_smooth(method = "nls",
formula = micmen.formula,
se = FALSE) +
stat_fit_tidy(method = "nls",
method.args = list(formula = micmen.formula),
size = 3,
label.x = "center",
label.y = "bottom",
vstep = 0.12,
aes(label =
after_stat(
paste("V~`=`~frac(",
signif(Vm_estimate, digits = 2), "~C,",
signif(K_estimate, digits = 2), "+C)",
sep = ""))),
parse = TRUE) +
labs(x = "C", y = "V")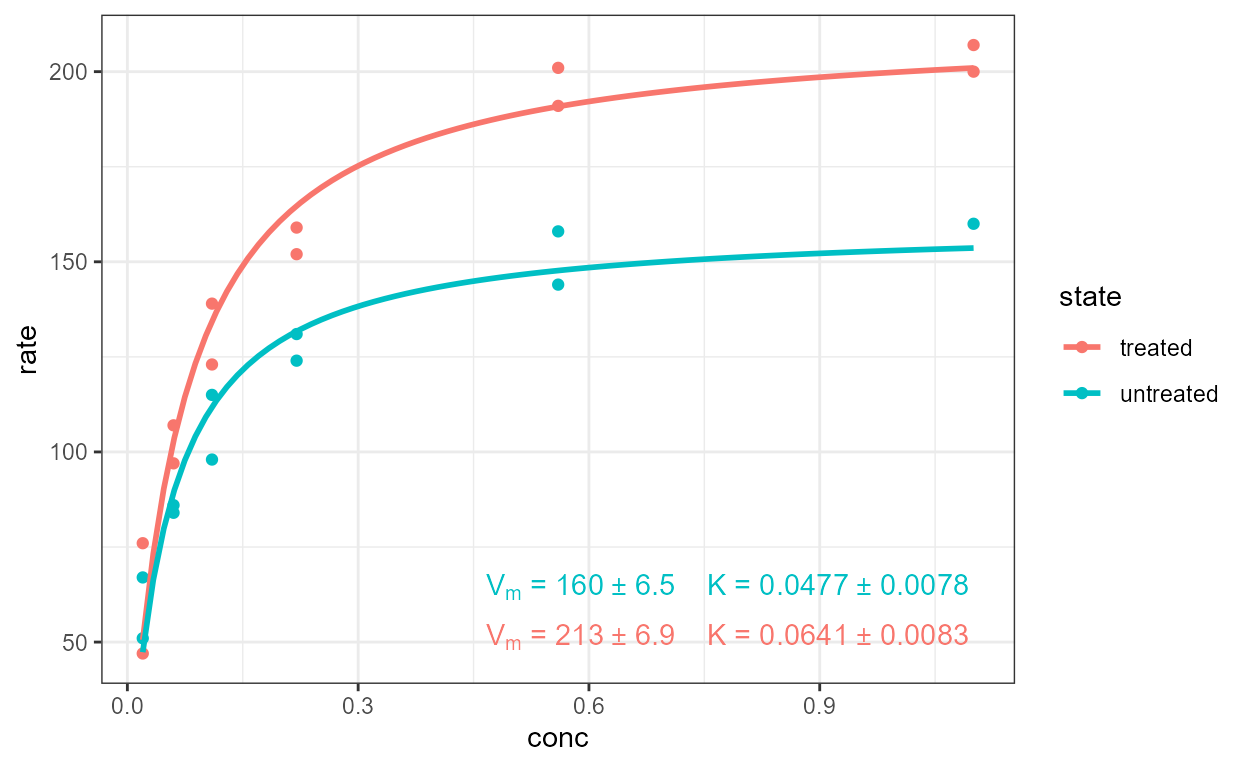
What if we would need a more specific statistic, similar to
stat_poly_eq()? We can use stat_fit_tidy() as
the basis for its definition.
stat_micmen_eq <- function(vstep = 0.12,
size = 3,
...) {
stat_fit_tidy(method = "nls",
method.args = list(formula = micmen.formula),
aes(label =
after_stat(
paste("V~`=`~frac(",
signif(Vm_estimate, digits = 2), "~C,",
signif(K_estimate, digits = 2), "+C)",
sep = ""))),
parse = TRUE,
vstep = vstep,
size = size,
...)
}The code for the figure is now simpler, and still produces the same figure (not shown).
micmen.formula <- y ~ SSmicmen(x, Vm, K)
ggplot(Puromycin, aes(conc, rate, colour = state)) +
geom_point() +
stat_smooth(method = "nls",
formula = micmen.formula,
se = FALSE) +
stat_micmen_eq(label.x = "center",
label.y = "bottom") +
labs(x = "C", y = "V")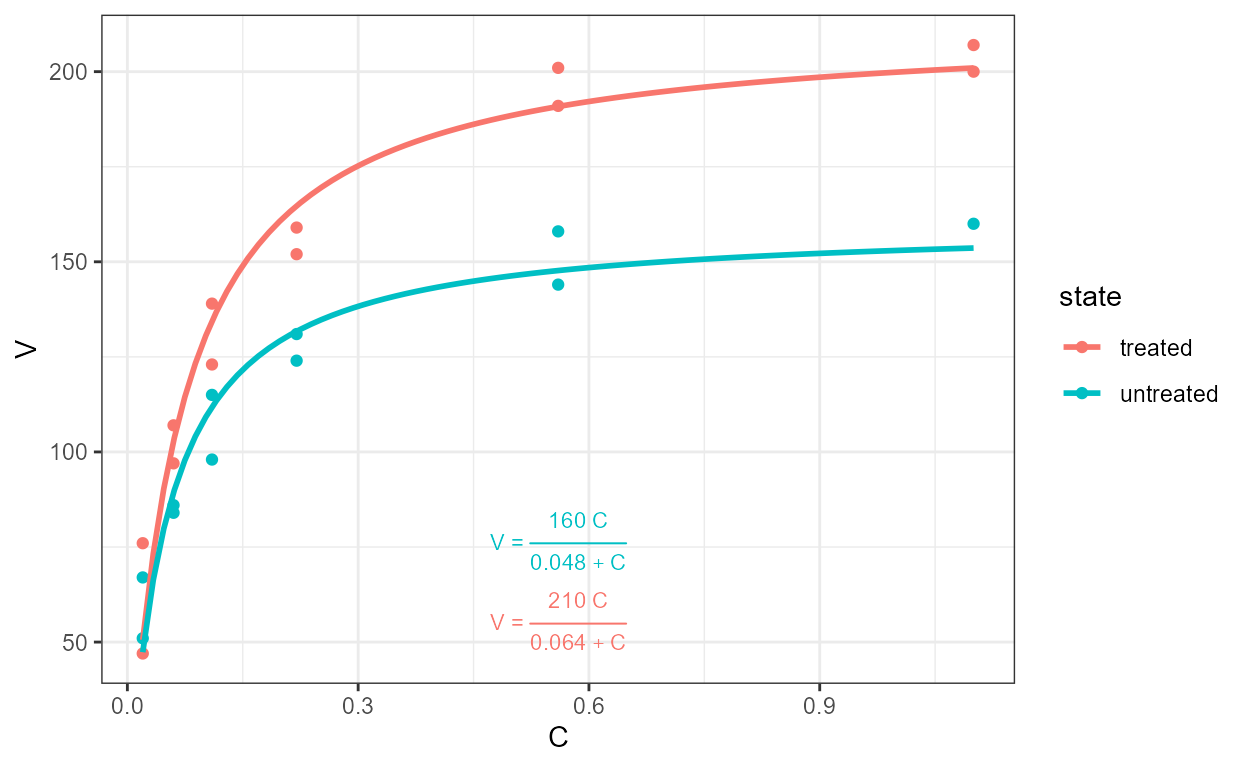
- As a second example we show a quantile regression fit using function
quantreg::rq()from package ‘quantreg’.
In an interactive R session the message below is displayed, giving
all the information needed for constructing a character string and
mapping it to the label aesthetic:
'stat_fit_tidy' variables (1 rows): Intercept_estimate, x_estimate, Intercept_se, x_se, Intercept_stat, x_stat, Intercept_p.value, x_p.value, Intercept_tau, x_tau, npcx, npcy, fm.class, fm.method, fm.formula, fm.formula.chr, flipped_aes.
my_formula <- y ~ x
my.format <- 'y~"="~%.3g+%.3g~x*", with "*italic(P)~"="~%.3f'
ggplot(mpg, aes(displ, 1 / hwy)) +
geom_point() +
stat_quantile(quantiles = 0.5, formula = my_formula) +
stat_fit_tidy(method = "rq",
method.args = list(formula = y ~ x, tau = 0.5),
tidy.args = list(se.type = "nid"),
mapping = aes(label =
after_stat(
sprintf(fmt = my.format,
Intercept_estimate,
x_estimate,
x_p.value))),
parse = TRUE)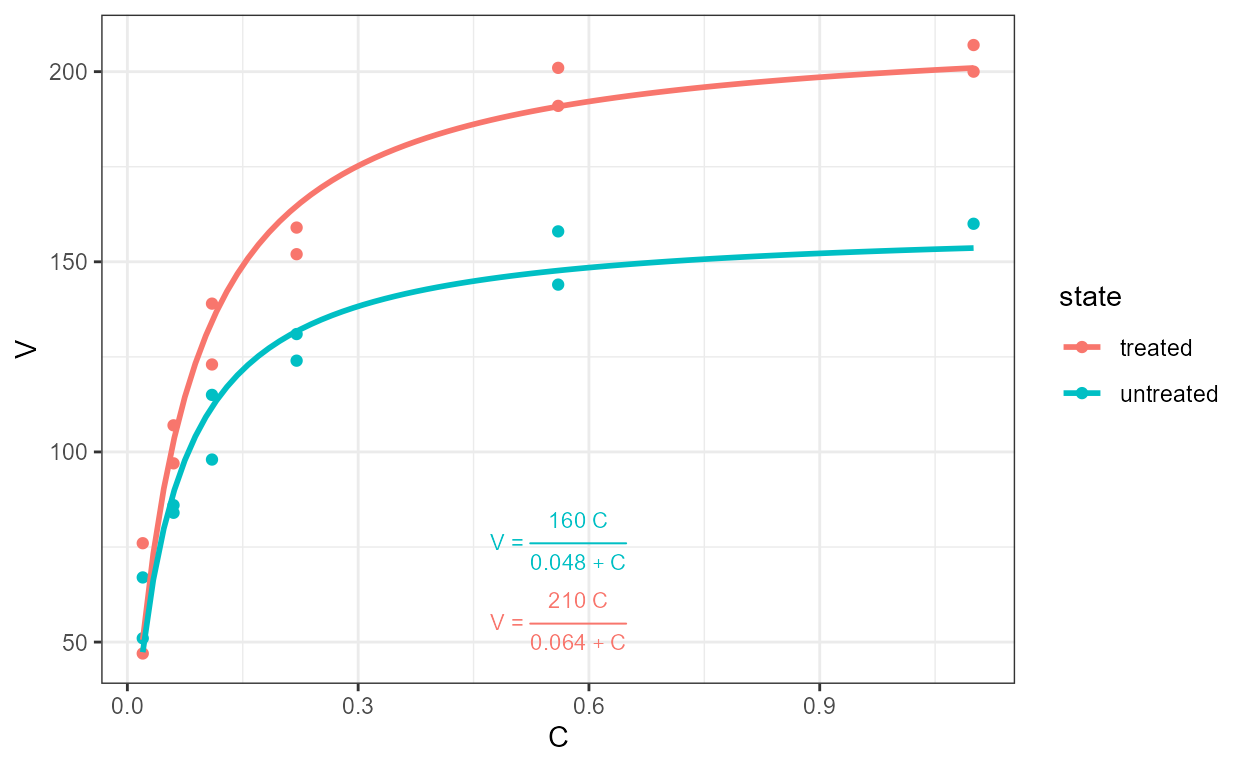
We can define a stat_rq_eq() if we need to add similar
equations to several plots. In this example we retain the ability of the
user to override most of the default default arguments.
stat_rq_eqn <-
function(formula = y ~ x,
tau = 0.5,
method = "br",
mapping =
aes(label =
after_stat(
sprintf(
'y~"="~%.3g+%.3g~x*", with "*italic(P)~"="~%.3f',
Intercept_estimate, x_estimate, x_p.value))),
parse = TRUE,
...) {
method.args <- list(formula = formula,
tau = tau,
method = method)
stat_fit_tidy(method = "rq",
method.args = method.args,
tidy.args = list(se.type = "nid"),
mapping = mapping,
parse = parse,
...)
}And the code of the figure now as simple as. Figure not shown, as is identical to the one above.
ggplot(mpg, aes(displ, 1 / hwy)) +
geom_point() +
stat_quantile(quantiles = 0.5, formula = my_formula) +
stat_rq_eqn(tau = 0.5, formula = my_formula)
stat_fit_augment
In simple cases ggplot2::stat_smooth,
stat_poly_line(), stat_ma_line(),
stat_quant_line(), stat_deviations() or
stat_residuals() can be easier to use than
stat_fit_augment. On the other hand
stat_fit_augment supports a larger number of model fit
functions.
When statistics specific to the type of model fitted are available,
their use is in general simpler that the use of
stat_fit_augment(). On the other hand,
stat_fit_augment() can handle any fitted model that is
supported by package ‘broom’ or its extensions. All these statistics
support grouping and facets.
In an interactive R session the message below is displayed, giving
all the information needed for constructing a character string and
mapping it to the label aesthetic:
'stat_fit_augment' variables (100 rows): y, x, I(x^2), I(x^3), .fitted, .resid, .hat, .sigma, .cooksd, .std.resid, y.observed, t.value, .se.fit, fm.class, fm.method, fm.formula, fm.formula.chr, flipped_aes.As the intention is to plot a line and/or band, the returned data frame has numerous rows per group, the number given by the arguments passed in the call (or their defaults).
# formula <- y ~ poly(x, 3, raw = TRUE)
# broom::augment does not handle poly correctly!
formula <- y ~ x + I(x^2) + I(x^3)
ggplot(my.data, aes(x, y.poly)) +
geom_point() +
stat_fit_augment(method = "lm",
method.args = list(formula = formula))
We can override the variable returned as y to be any of
the variables in the data frame returned by
broom::augment() while still preserving the original
y values.
formula <- y ~ x + I(x^2) + I(x^3)
ggplot(my.data, aes(x, y.poly)) +
stat_fit_augment(method = "lm",
method.args = list(formula = formula),
geom = "point",
y.out = ".resid") +
labs(y = "Residuals")
formula <- y ~ x + I(x^2) + I(x^3)
ggplot(my.data, aes(x, y.poly.grp, colour = group)) +
stat_fit_augment(method = "lm",
method.args = list(formula = formula),
geom = "point",
y.out = ".std.resid") +
labs(y = "Residuals")
We can use any model fitting method for which
broom::augment() is implemented. When a method, in this
case of nls(), has no support for confidence limits and
‘broom’ sets them to NA values, no confidence band in
plotted and a warning is issued by geom_smooth() from
‘ggplot2’, which is the default. The warning is harmless, and if needed,
it can be silenced by passing geom = "line" to override the
default.
args <- list(formula = y ~ k * e ^ x,
start = list(k = 1, e = 2))
ggplot(mtcars, aes(wt, mpg)) +
geom_point() +
stat_fit_augment(method = "nls",
method.args = args)## Warning in max(ids, na.rm = TRUE): no non-missing arguments to max; returning
## -Inf
args <- list(formula = y ~ k * e ^ x,
start = list(k = 1, e = 2))
ggplot(mtcars, aes(wt, mpg)) +
stat_fit_augment(method = "nls",
method.args = args,
geom = "point",
y.out = ".resid") +
labs(y = "Residuals")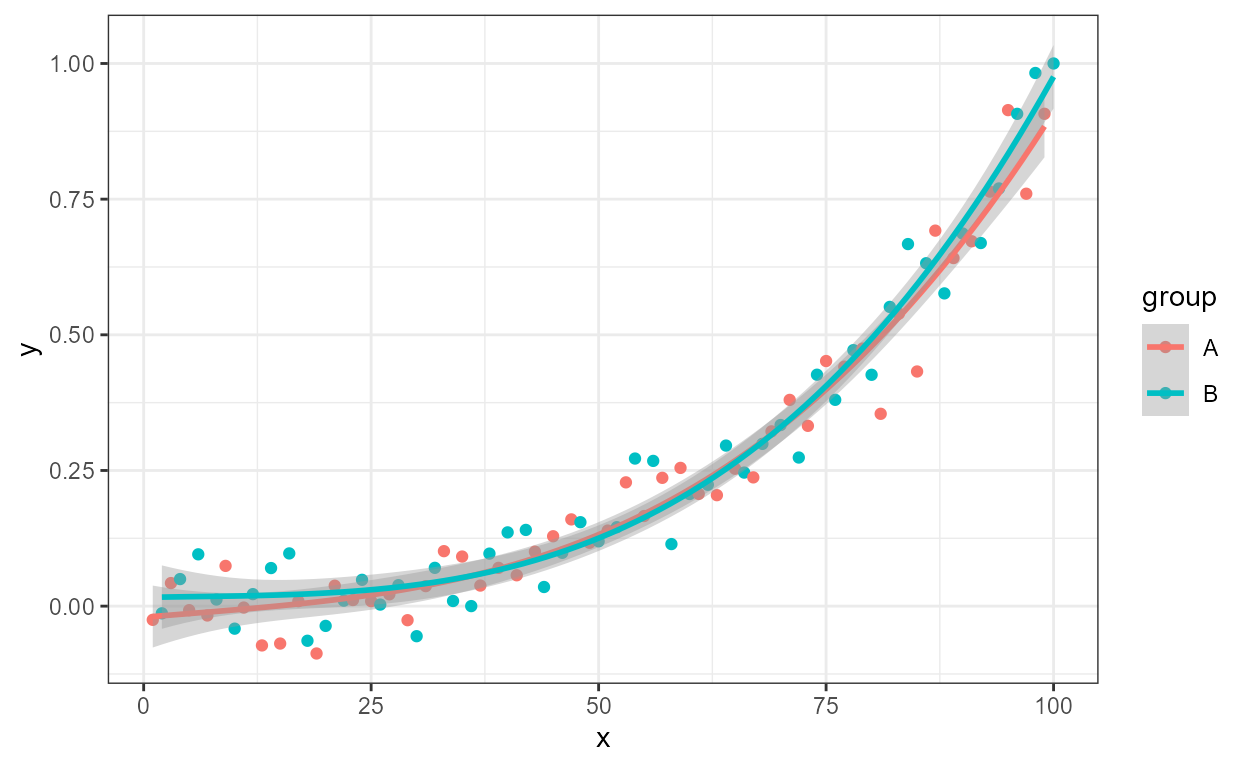
Note: The tidiers for mixed models have moved to package ‘broom.mixed’!
args <- list(model = y ~ SSlogis(x, Asym, xmid, scal),
fixed = Asym + xmid + scal ~1,
random = Asym ~1 | group,
start = c(Asym = 200, xmid = 725, scal = 350))
ggplot(Orange, aes(age, circumference, colour = Tree)) +
geom_point() +
stat_fit_augment(method = "nlme",
method.args = args,
augment.args = list(data = quote(data)),
geom = "line")
Inspecting computed variables and labels
In the case of model fitting statistics like
stat_poly_eq() and stat_poly_line(), which
variables are present or are not set to NA depends on the
model fit method used and frequently also on the arguments
passed to the parameters of the stats including method
method.args.
In ‘ggpmisc’ (>= 1.0.0) when executed in an interactive R
session statistics display by default a message listing either the names
of variables in the returned data frame containing non-missing (tested
with is.na()) data or the short names of non-missing
formatted character strings. The messages also display the number of
rows returned by compute function, per data group or per panel. In the
case of column names, they can be mapped to any aesthetics using
aes(), or to the label aesthetic using
use_label() or f_use_label(). Functions
use_label() or f_use_label() recognize short
names or nicknames for the formatted text labels.
As other messages in R, these messages can be silenced. They can also
be controlled specifically using R option
"ggpmisc.stat.vars.message" which can take values
"colnames", "nicknames" and
"skip". As the documentation is generated in an R session
that is not interactive, the option needs to be set here to display a
message.
# force same behaviours as in an interactive R session
old.options <- options(ggpmisc.stat.vars.message = "nicknames")
formula <- y ~ poly(x, 3, raw = TRUE)
ggplot(my.data, aes(x, y.poly)) +
geom_point() +
stat_poly_line(formula = formula) +
stat_poly_eq(formula = formula)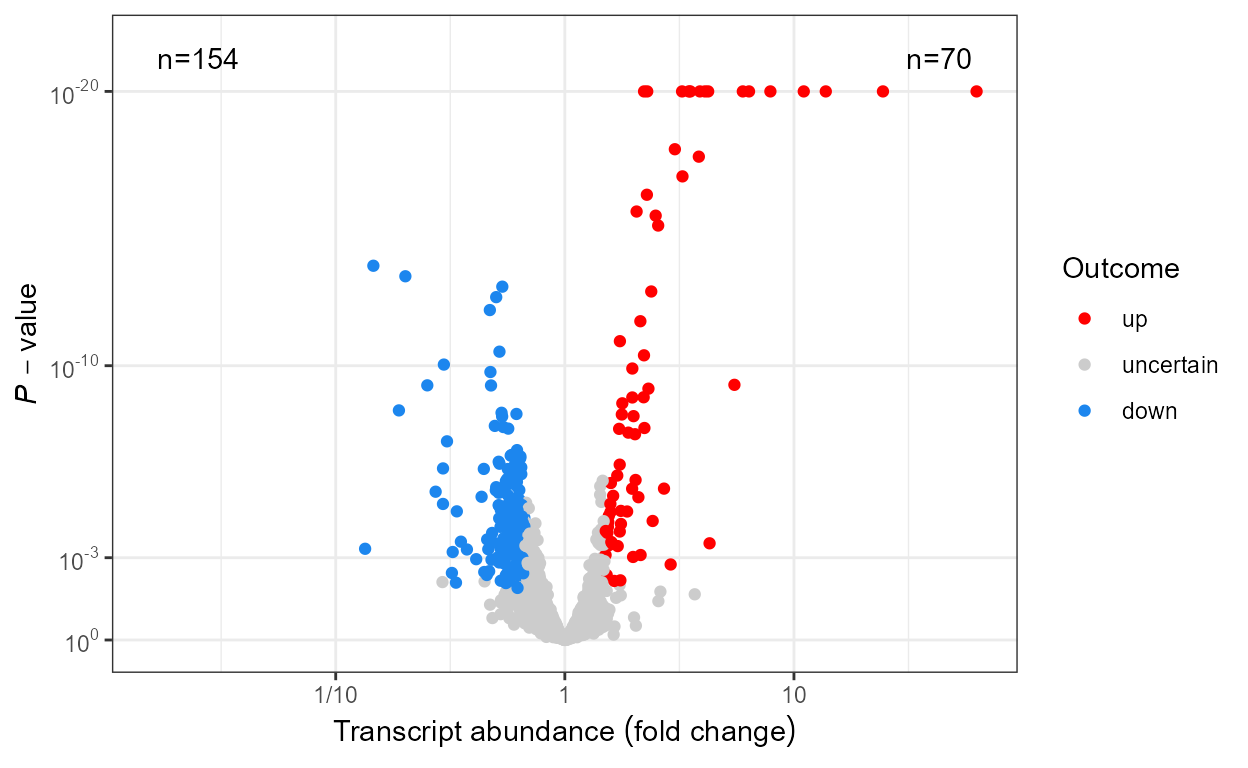
Moreover, when using stat_fit_glance(),
stat_fit_tidy(), stat_fit_augment() and
stat_fit_tb() the documentation cannot describe the
variables present in the returned data because they call
methods using their generic interface and the exact specialization used
depends on the argument passed to method, which can be
easily one that has not been tested during the development of ‘ggpmisc’.
These statistics do not automatically generate formatted labels and the
message lists all columns in the returned data frame containing
available data.
# formula <- y ~ poly(x, 3, raw = TRUE)
# broom::augment does not handle poly() correctly
formula <- y ~ x + I(x^2) + I(x^3)
ggplot(my.data, aes(x, y.poly)) +
geom_point() +
stat_poly_line(formula = formula) +
stat_fit_glance(aes(label =
after_stat(
sprintf("italic(P)*\"-value = \"*%.3g",
p.value))),
parse = TRUE,
method.args = list(formula = formula),
label.x = "right",
label.y = "bottom")
We restore the options to their previous state.
options(old.options)In addition package ‘gginnards’ exports
gginnards::geom_debug_group() that prints the data frame,
making it possible to explore its contents by temporarily substituting
other geoms with in the plot code.
gginnards::geom_debug_group() uses by default
head() to echo to the R console the data it receives as
input. It ignores the aesthetic mappings so it can be used with any
statistics or directly as a layer function. However, unrecognised
aesthetics can trigger warnings during plot rendering. These warnings
can be ignored in most cases.
# formula <- y ~ poly(x, 3, raw = TRUE)
# broom::augment does not handle poly() correctly!
formula <- y ~ x + I(x^2) + I(x^3)
ggplot(my.data, aes(x, y.poly)) +
geom_point() +
stat_poly_line(formula = formula) +
stat_fit_glance(aes(label =
after_stat(
sprintf("italic(P)*\"-value = \"*%.3g",
p.value))),
# parse = TRUE,
geom = "debug_group",
method.args = list(formula = formula),
label.x = "right",
label.y = "bottom")## [1] "PANEL 1; group(s) -1; 'draw_function()' input 'data' (head):"
## r.squared adj.r.squared sigma statistic p.value df logLik AIC
## 1 0.9587146 0.9574245 0.05573386 743.0932 2.790566e-66 3 148.864 -287.728
## BIC deviance df.residual nobs fm.class fm.method
## 1 -274.7021 0.2982013 96 100 lm lm
## fm.formula fm.formula.chr x npcx y npcy
## 1 y ~ x + I(x^2) + I(x^3) y ~ x + I(x^2) + I(x^3) 9.505 NA -0.04555283 NA
## flipped_aes PANEL group label orientation
## 1 FALSE 1 -1 italic(P)*"-value = "*2.79e-66 NA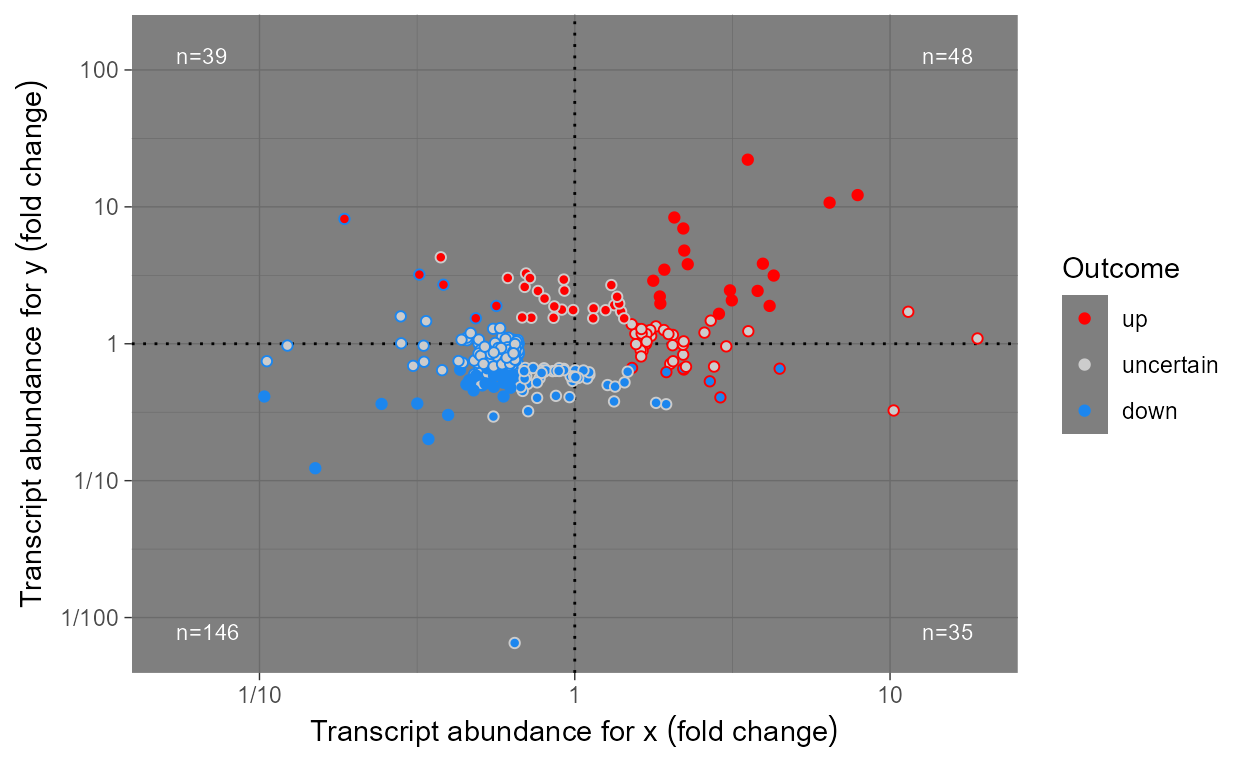
In the case of stat_fit_tb() the computed variables
returned include a list column containing embedded data frames. In this
case, function str() is more informative than
head(), so we can pass it as argument overriding the
default.
formula <- y ~ x + I(x^2) + I(x^3)
ggplot(my.data, aes(x, y.poly)) +
geom_point() +
stat_poly_line(formula = formula) +
stat_fit_tb(geom = "debug_panel",
summary.fun = str,
method.args = list(formula = formula),
tb.vars = c(Parameter = "term",
Estimate = "estimate",
"s.e." = "std.error",
"italic(t)" = "statistic",
"italic(P)" = "p.value"),
# parse = TRUE,
label.y = "top",
label.x = "left")## Warning in stat_fit_tb(geom = "debug_panel", summary.fun = str, method.args = list(formula = formula), : Ignoring unknown parameters: `table.theme`, `table.rownames`, `table.colnames`,
## `table.hjust`, and `summary.fun`## [1] "PANEL 1; group(s) -1; 'draw_function()' input 'data' (head):"
## PANEL x y group
## 1 1 0.1 1 -1
## fm.tb
## 1 (Intercept), x, I(x^2), I(x^3), 0.00217, 0.0143, -0.00176, 0.000964, 0.0232, 0.0198, 0.00453, 0.000295, 0.0939, 0.724, -0.389, 3.27, 0.925, 0.471, 0.698, 0.002
## fm.tb.type fm.class fm.method fm.formula
## 1 fit.summary lm lm y ~ x + I(x^2) + I(x^3)
## fm.formula.chr npcx npcy flipped_aes
## 1 y ~ x + I(x^2) + I(x^3) NA NA FALSE
## label
## 1 (Intercept), x, I(x^2), I(x^3), 0.00217, 0.0143, -0.00176, 0.000964, 0.0232, 0.0198, 0.00453, 0.000295, 0.0939, 0.724, -0.389, 3.27, 0.925, 0.471, 0.698, 0.002
## orientation
## 1 NA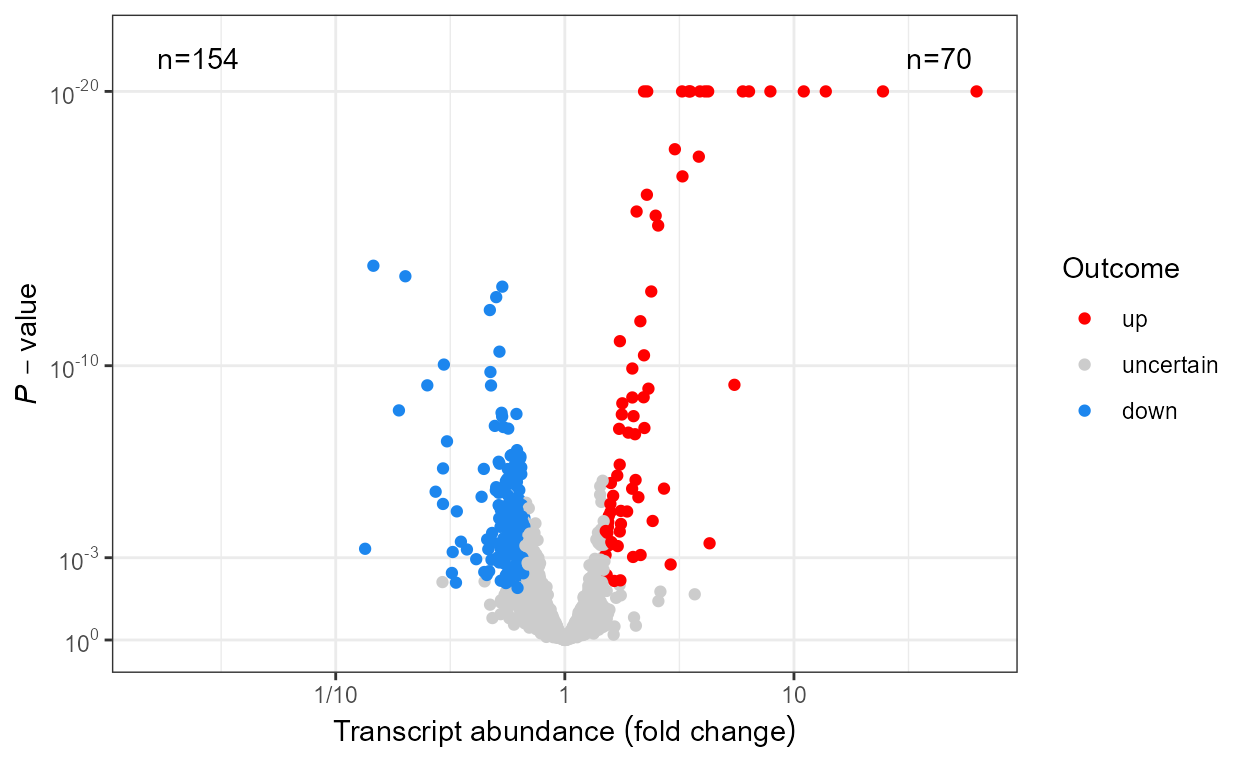
gginnards::geom_debug_group() can be used with stats
from ‘ggplot2’ and its extensions. More examples are given in the documentation of
package ‘gginnards’.
Examples for Scales
Volcano and quadrant plots are scatter plots with some peculiarities. Creating these plots from scratch using ‘ggplot2’ can be time consuming, but allows flexibility in design. Rather than providing a ‘canned’ function to produce volcano plots, package ‘ggpmisc’ provides several building blocks that facilitate the production of volcano and quadrant plots. These are wrappers on scales from packages ‘scales’ and ‘ggplot2’ with suitable defaults plus helper functions to create factors from numeric outcomes.
scale_color_outcome, scale_fill_outcome
Manual scales for colour and fill aesthetics with defaults suitable for the three way outcomes from statistical tests.
scale_x_FDR, scale_y_FDR, scale_x_logFC, scale_y_logFC, scale_x_Pvalue, scale_y_Pvalue
Scales for x or y aesthetics mapped to P-values, FDR (false discovery rate) or log FC (logarithm of fold-change) as used in volcano and quadrant plots of transcriptomics and metabolomics data.
symmetric_limits
A simple function to expand scale limits to be symmetric around zero. Can be passed as argument to parameter limits of continuous scales from packages ‘ggpmisc’, ‘ggplot2’ or ‘scales’ (and extensions).
Volcano-plot examples
Volcano plots are frequently used for transcriptomics and metabolomics. They are used to show P-values or FDR (false discovery rate) as a function of effect size, which can be either an increase or a decrease. Effect sizes are expressed as fold-changes compared to a control or reference condition. Colours are frequently used to highlight significant responses. Counts of significant increases and decreases are frequently also added.
Outcomes encoded as -1, 0 or 1, as seen in the tibble below need to
be converted into factors with suitable labels for levels. This can be
easily achieved with function outcome2factor().
head(volcano_example.df) ## tag gene outcome logFC PValue genotype
## 1 AT1G01040 ASU1 0 -0.15284466 0.35266997 Ler
## 2 AT1G01290 ASG4 0 -0.30057068 0.05471732 Ler
## 3 AT1G01560 ATSBT1.1 0 -0.57783350 0.06681310 Ler
## 4 AT1G01790 AtSAM1 0 -0.04729662 0.74054263 Ler
## 5 AT1G02130 AtTRM82 0 -0.14279891 0.29597519 Ler
## 6 AT1G02560 PRP39 0 0.23320752 0.07487043 LerMost frequently fold-change data is available log-transformed, using either 2 or 10 as base. In general it is more informative to use tick labels expressed as un-transformed fold-change.
By default scale_x_logFC() and
scale_y_logFC() expect the logFC data log2-transformed, but
this can be overridden. The default use of untransformed fold-change for
tick labels can also be overridden. Scale scale_x_logFC()
in addition by default expands the scale limits to make them symmetric
around zero. If %unit is included in the name character
string, suitable units are appended as shown in the example below.
Scales scale_y_Pvalue() and
scale_x_Pvalue() have suitable defaults for name and
labels, while scale_colour_outcome() provides suitable
defaults for the colours mapped to the outcomes. To change the labels
and title of the key or guide pass suitable
arguments to parameters name and labels of
these scales. These x and y scales by default squish off-limits
(out-of-bounds) observations towards the limits.
ggplot(volcano_example.df,
aes(logFC, PValue, colour = outcome2factor(outcome))) +
geom_point() +
scale_x_logFC(name = "Transcript abundance%unit") +
scale_y_Pvalue() +
scale_colour_outcome() +
stat_quadrant_counts(data = function(x) {subset(x, outcome != 0)})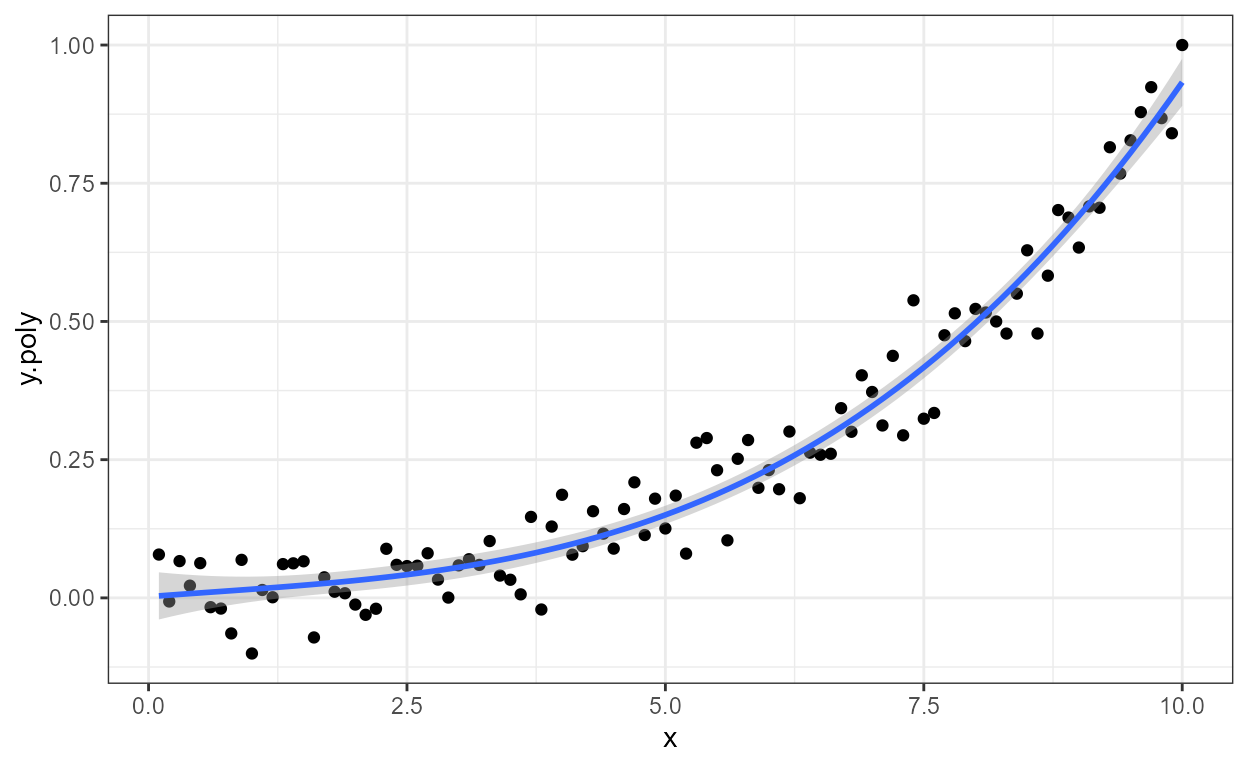
By default outcome2factor() creates a factor with three
levels as in the example above, but this default can be overridden as
shown below. A scale with base-two logarithms as tick labels for log FC
is also used.
ggplot(volcano_example.df,
aes(logFC, PValue, colour = outcome2factor(outcome, n.levels = 2))) +
geom_point() +
scale_x_logFC(name = "Transcript abundance%unit", log.base.labels = 2) +
scale_y_Pvalue() +
scale_colour_outcome(values = "outcome:de") +
stat_quadrant_counts(data = function(x) {subset(x, outcome != 0)})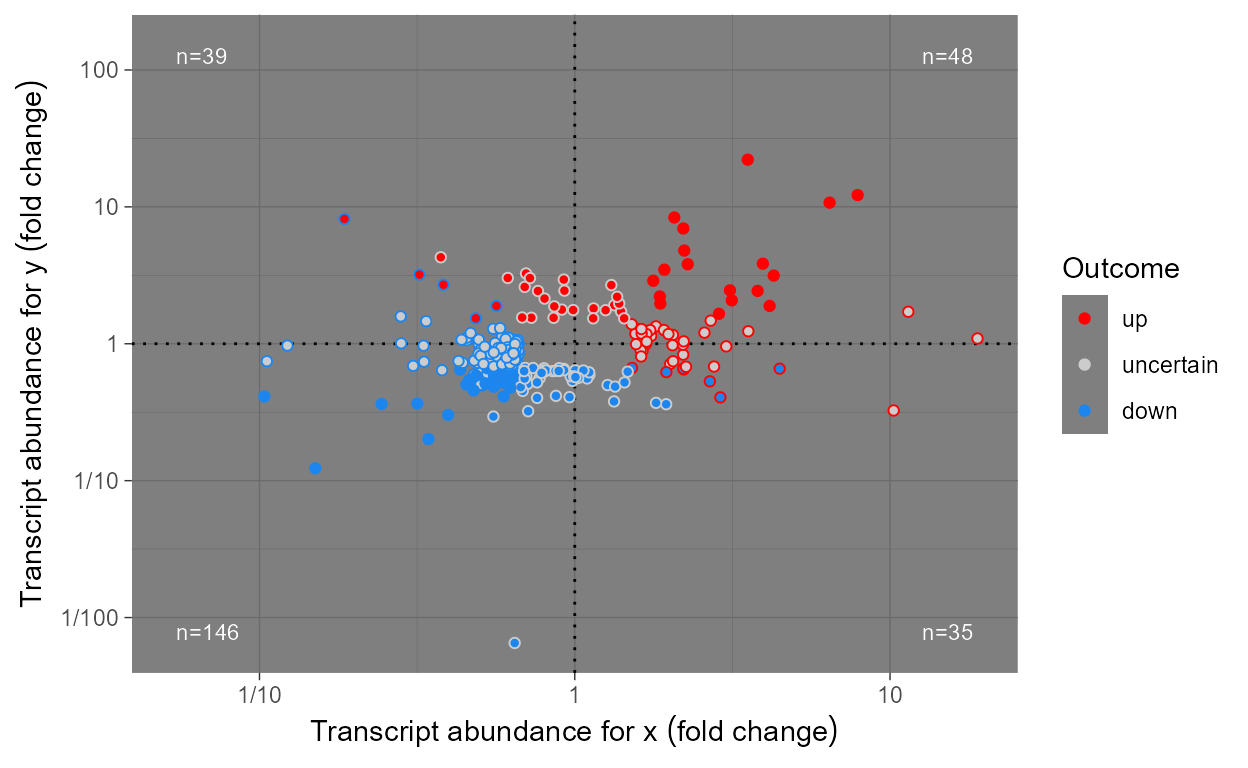
Quadrant-plot examples
Quadrant plots are scatter plots with comparable variables on both axes and usually include the four quadrants. When used for transcriptomics and metabolomics, they are used to compare responses expressed as fold-change to two different conditions or treatments. They are useful when many responses are measured as in transcriptomics (many different genes) or metabolomics (many different metabolites).
A single panel quadrant plot is as easy to produce as a volcano plot
using scales scale_x_logFC() and
scale_y_logFC(). The data includes two different outcomes
and two different log fold-change variables. See the previous section on
volcano plots for details. In this example we use as shape a filled
circle and map one of the outcomes to colour and the other to fill,
using the two matched scales scale_colour_outcome() and
scale_fill_outcome().
head(quadrant_example.df)## tag gene outcome.x outcome.y logFC.x logFC.y genotype
## 1 AT5G11060 TIC56 0 0 -0.17685517 -0.32956762 Ler
## 2 AT3G01280 ATWRKY48 0 0 -0.06471884 0.07771315 Ler
## 3 AT5G06320 ANY1 0 0 -0.35200684 -0.04331339 Ler
## 4 AT1G05850 AP1M1 0 0 -0.40284744 -0.04505435 Ler
## 5 AT2G22300 HSA32 0 0 -0.34482142 -0.11185095 Ler
## 6 AT2G16070 UBQ11 0 0 -0.22328946 -0.23210780 LerIn this plot we do not include those genes whose change in transcript abundance is uncertain under both x and y conditions.
ggplot(subset(quadrant_example.df,
xy_outcomes2factor(outcome.x, outcome.y) != "none"),
aes(logFC.x, logFC.y,
colour = outcome2factor(outcome.x),
fill = outcome2factor(outcome.y))) +
geom_quadrant_lines(linetype = "dotted") +
stat_quadrant_counts(size = 3, colour = "white") +
geom_point(shape = "circle filled") +
scale_x_logFC(name = "Transcript abundance for x%unit") +
scale_y_logFC(name = "Transcript abundance for y%unit") +
scale_colour_outcome() +
scale_fill_outcome() +
theme_dark()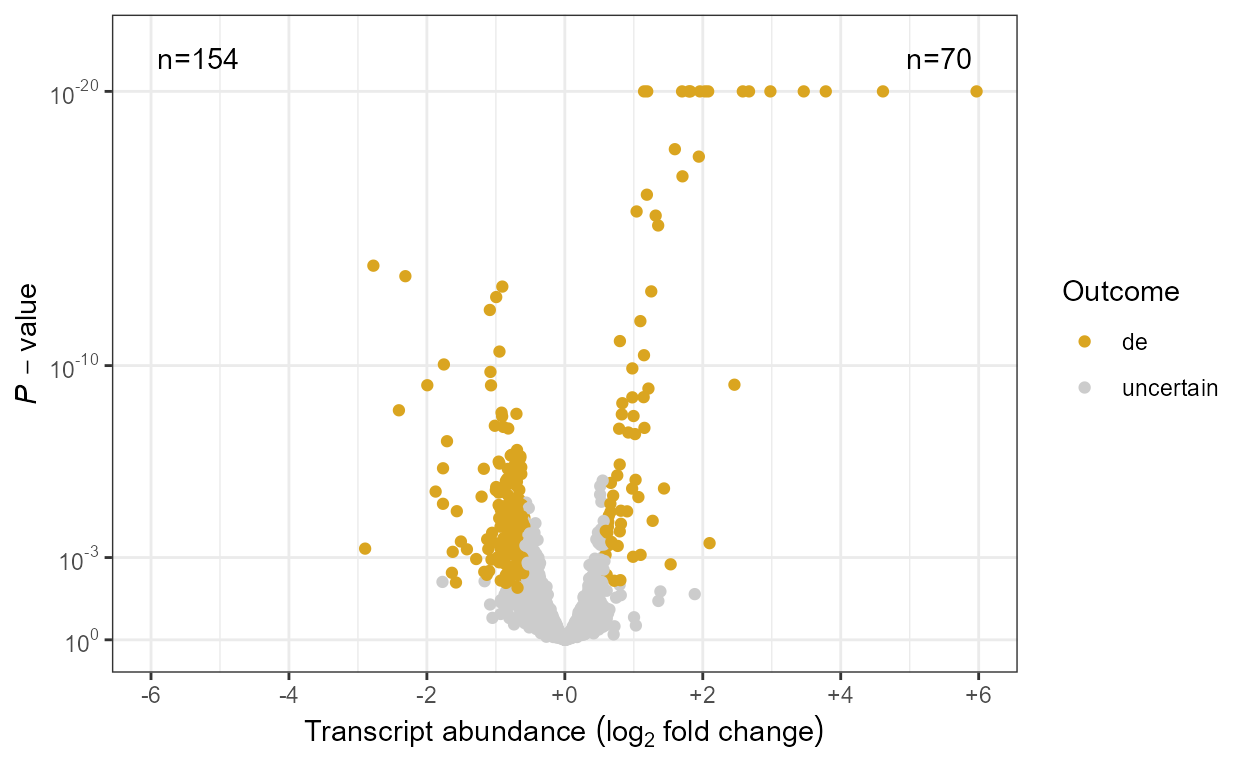
To plot in separate panels those observations that are significant along both x and y axes, x axis, y axis, or none, with quadrants merged takes more effort. We first define two helper functions to add counts and quadrant lines to each of the four panels.
all_quadrant_counts <- function(...) {
list(
stat_quadrant_counts(data = . %>% filter(outcome.xy.fct == "xy"), ...),
stat_quadrant_counts(data = . %>% filter(outcome.xy.fct == "x"), pool.along = "y", ...),
stat_quadrant_counts(data = . %>% filter(outcome.xy.fct == "y"), pool.along = "x", ...),
stat_quadrant_counts(data = . %>% filter(outcome.xy.fct == "none"), quadrants = 0L, ...)
)
}
all_quadrant_lines <- function(...) {
list(
geom_hline(data = data.frame(outcome.xy.fct = factor(c("xy", "x", "y", "none"),
levels = c("xy", "x", "y", "none")),
yintercept = c(0, NA, 0, NA)),
aes(yintercept = yintercept),
na.rm = TRUE,
...),
geom_vline(data = data.frame(outcome.xy.fct = factor(c("xy", "x", "y", "none"),
levels = c("xy", "x", "y", "none")),
xintercept = c(0, 0, NA, NA)),
aes(xintercept = xintercept),
na.rm = TRUE,
...)
)
}And use these functions to build the final plot, in this case including all genes.
quadrant_example.df %>%
mutate(.,
outcome.x.fct = outcome2factor(outcome.x),
outcome.y.fct = outcome2factor(outcome.y),
outcome.xy.fct = xy_outcomes2factor(outcome.x, outcome.y)) %>%
ggplot(., aes(logFC.x, logFC.y, colour = outcome.x.fct, fill = outcome.y.fct)) +
geom_point(shape = 21) +
all_quadrant_lines(linetype = "dotted") +
all_quadrant_counts(size = 3, colour = "white") +
scale_x_logFC(name = "Transcript abundance for x%unit") +
scale_y_logFC(name = "Transcript abundance for y%unit") +
scale_colour_outcome() +
scale_fill_outcome() +
facet_wrap(~outcome.xy.fct) +
theme_dark()